+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/docs/.vuepress/components/unlock/UnlockContent.vue b/docs/.vuepress/components/unlock/UnlockContent.vue
new file mode 100644
index 00000000000..f85351ae8f4
--- /dev/null
+++ b/docs/.vuepress/components/unlock/UnlockContent.vue
@@ -0,0 +1,243 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ 人机验证
+ ++ 为保障正常阅读体验,本站部分内容已开启一次性验证。验证后全站解锁。 +
+ +
+ ![公众号二维码]() +
+
+
+ + 扫码/微信搜索关注 + “JavaGuide” +
+回复 “验证码”
+
+
+
+
+
+ 验证码错误,请重试
+
+
+
+
+
+
+
+
+
diff --git a/docs/.vuepress/config.ts b/docs/.vuepress/config.ts
index eed17cf0e1d..b34f2b96aa5 100644
--- a/docs/.vuepress/config.ts
+++ b/docs/.vuepress/config.ts
@@ -7,54 +7,60 @@ export default defineUserConfig({
title: "JavaGuide",
description:
- "「Java 学习指北 + Java 面试指南」一份涵盖大部分 Java 程序员所需要掌握的核心知识。准备 Java 面试,复习 Java 知识点,首选 JavaGuide! ",
+ "JavaGuide 是一份面向后端开发/后端面试的学习与复习指南,覆盖 Java、数据库/MySQL、Redis、分布式、高并发、高可用、系统设计等核心知识。",
lang: "zh-CN",
head: [
// meta
["meta", { name: "robots", content: "all" }],
["meta", { name: "author", content: "Guide" }],
- [
- "meta",
- {
- "http-equiv": "Cache-Control",
- content: "no-cache, no-store, must-revalidate",
- },
- ],
- ["meta", { "http-equiv": "Pragma", content: "no-cache" }],
- ["meta", { "http-equiv": "Expires", content: "0" }],
- [
- "meta",
- {
- name: "keywords",
- content:
- "Java基础, 多线程, JVM, 虚拟机, 数据库, MySQL, Spring, Redis, MyBatis, 系统设计, 分布式, RPC, 高可用, 高并发",
- },
- ],
- [
- "meta",
- {
- name: "description",
- content:
- "「Java学习 + 面试指南」一份涵盖大部分 Java 程序员所需要掌握的核心知识。准备 Java 面试,首选 JavaGuide!",
- },
- ],
+ // [
+ // "meta",
+ // {
+ // name: "keywords",
+ // content:
+ // "JavaGuide, 后端面试, 后端开发, Java面试, Java基础, 并发编程, JVM, 数据库, MySQL, Redis, Spring, 分布式, 高并发, 高性能, 高可用, 系统设计, 消息队列, 缓存, 计算机网络, Linux",
+ // },
+ // ],
+ // [
+ // "meta",
+ // {
+ // name: "description",
+ // content:
+ // "JavaGuide 是一份面向后端开发/后端面试的学习与复习指南,覆盖 Java、数据库/MySQL、Redis、分布式、高并发、高可用、系统设计等核心知识。",
+ // },
+ // ],
+ ["meta", { property: "og:site_name", content: "JavaGuide" }],
+ ["meta", { property: "og:type", content: "website" }],
+ ["meta", { property: "og:locale", content: "zh_CN" }],
+ ["meta", { property: "og:url", content: "https://javaguide.cn/" }],
["meta", { name: "apple-mobile-web-app-capable", content: "yes" }],
- // 添加百度统计
+ // 添加百度统计 - 异步加载避免阻塞渲染
[
"script",
- {},
+ { defer: true },
`var _hmt = _hmt || [];
(function() {
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?5dd2e8c97962d57b7b8fea1737c01743";
+ hm.async = true;
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();`,
],
],
- bundler: viteBundler(),
+ bundler: viteBundler({
+ viteOptions: {
+ css: {
+ preprocessorOptions: {
+ scss: {
+ silenceDeprecations: ["if-function"],
+ },
+ },
+ },
+ },
+ }),
theme,
diff --git a/docs/.vuepress/features/unlock/config.ts b/docs/.vuepress/features/unlock/config.ts
new file mode 100644
index 00000000000..c2272adb650
--- /dev/null
+++ b/docs/.vuepress/features/unlock/config.ts
@@ -0,0 +1,37 @@
+import { PREVIEW_HEIGHT } from "./heights";
+
+const withDefaultHeight = (
+ paths: readonly string[],
+ height: string = PREVIEW_HEIGHT.XL,
+): Record
+
+
+
+
+
+
+
+
+
+
+
+
+ 人机验证
++ 为保障正常阅读体验,本站部分内容已开启一次性验证。验证后全站自动解锁。 +
+ +
+ ![公众号二维码]() +
+
+
+ + 扫码关注公众号,回复 “验证码” +
+
+
+
+
+
+ 验证码错误,请重新输入
+ -如果你**时间比较充裕**,更推荐直接在 [JavaGuide 官网](https://javaguide.cn/) 上**系统学习**:内容比突击版更全面、更深入,更适合打基础和长期提升。
+## 🌐 关于网站
-**突击版本网站入口**:[interview.javaguide.cn](https://interview.javaguide.cn/)
+JavaGuide 已经持续维护 6 年多了,累计提交 **6000+** commit ,共有 **620+** 多位贡献者共同参与维护和完善。
-对应的 PDF 版本,可以直接在公众号后台回复“**PDF**”获取:
+网站内容覆盖:
-
+- **后端面试**:Java 基础、集合、并发、JVM、MySQL、Redis、分布式、系统设计等核心知识。
+- **AI 应用开发**:大模型(LLM)基础、Agent 智能体、RAG 检索增强生成、MCP 协议等前沿技术。
-## 面试辅导
+真心希望能够把这个项目做好,真正能够帮助到有需要的朋友!
-给自己打个小广告,如果需要面试辅导(比如简历优化、一对一提问、高频考点突击资料等),欢迎了解我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)。已经坚持维护六年,内容持续更新,虽白菜价(**0.4元/天**)但质量很高,主打一个良心!
+如果觉得 JavaGuide 的内容对你有帮助的话,还请点个免费的 Star(绝不强制点 Star,觉得内容不错有收获再点赞就好),这是对我最大的鼓励,感谢各位一路同行,共勉!传送门:[GitHub](https://github.com/Snailclimb/JavaGuide) | [Gitee](https://gitee.com/SnailClimb/JavaGuide)。
-
-
-如果你**时间比较充裕**,更推荐直接在 [JavaGuide 官网](https://javaguide.cn/) 上**系统学习**:内容比突击版更全面、更深入,更适合打基础和长期提升。
+## 🌐 关于网站
-**突击版本网站入口**:[interview.javaguide.cn](https://interview.javaguide.cn/)
+JavaGuide 已经持续维护 6 年多了,累计提交 **6000+** commit ,共有 **620+** 多位贡献者共同参与维护和完善。
-对应的 PDF 版本,可以直接在公众号后台回复“**PDF**”获取:
+网站内容覆盖:
-
+- **后端面试**:Java 基础、集合、并发、JVM、MySQL、Redis、分布式、系统设计等核心知识。
+- **AI 应用开发**:大模型(LLM)基础、Agent 智能体、RAG 检索增强生成、MCP 协议等前沿技术。
-## 面试辅导
+真心希望能够把这个项目做好,真正能够帮助到有需要的朋友!
-给自己打个小广告,如果需要面试辅导(比如简历优化、一对一提问、高频考点突击资料等),欢迎了解我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)。已经坚持维护六年,内容持续更新,虽白菜价(**0.4元/天**)但质量很高,主打一个良心!
+如果觉得 JavaGuide 的内容对你有帮助的话,还请点个免费的 Star(绝不强制点 Star,觉得内容不错有收获再点赞就好),这是对我最大的鼓励,感谢各位一路同行,共勉!传送门:[GitHub](https://github.com/Snailclimb/JavaGuide) | [Gitee](https://gitee.com/SnailClimb/JavaGuide)。
-
-  -
+- [项目介绍](./javaguide/intro.md)(JavaGuide 的诞生)
+- [贡献指南](./javaguide/contribution-guideline.md)(期待你的贡献,奖励丰富)
+- [常见问题](./javaguide/faq.md)(统一回复大家的一些疑问)
diff --git a/docs/about-the-author/README.md b/docs/about-the-author/README.md
index 12f6eab7f3f..43524d2ff58 100644
--- a/docs/about-the-author/README.md
+++ b/docs/about-the-author/README.md
@@ -1,5 +1,6 @@
---
title: 个人介绍 Q&A
+description: JavaGuide作者Guide个人介绍,19年本科毕业、大学期间变现20w+实现经济独立、坚持写博客的经历与收获分享。
category: 走近作者
---
diff --git a/docs/about-the-author/deprecated-java-technologies.md b/docs/about-the-author/deprecated-java-technologies.md
index 0146d71c4a3..84dc6e720b2 100644
--- a/docs/about-the-author/deprecated-java-technologies.md
+++ b/docs/about-the-author/deprecated-java-technologies.md
@@ -1,5 +1,6 @@
---
title: 已经淘汰的 Java 技术,不要再学了!
+description: 已淘汰的Java技术盘点,JSP、Struts、EJB、Java Applets、SOAP等过时技术不建议学习,附现代替代方案推荐。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/dog-that-copies-other-people-essay.md b/docs/about-the-author/dog-that-copies-other-people-essay.md
index 653b616eaab..2ae67150843 100644
--- a/docs/about-the-author/dog-that-copies-other-people-essay.md
+++ b/docs/about-the-author/dog-that-copies-other-people-essay.md
@@ -1,5 +1,6 @@
---
title: 抄袭狗,你冬天睡觉脚必冷!!!
+description: 原创文章被抄袭的无奈经历,知乎、CSDN多平台盗文现象吐槽,分享如何屏蔽低质量内容和维护原创权益。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/feelings-after-one-month-of-induction-training.md b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
index ed57578a907..8ea32dd5c74 100644
--- a/docs/about-the-author/feelings-after-one-month-of-induction-training.md
+++ b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
@@ -1,5 +1,6 @@
---
title: 入职培训一个月后的感受
+description: ThoughtWorks入职培训一个月感受,从Windows切换到Mac的适应、TWU培训内容、Feedback反馈文化等新人入职体验分享。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
index cc9fe136749..d737f1a10b4 100644
--- a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
+++ b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
@@ -1,5 +1,6 @@
---
title: 从毕业到入职半年的感受
+description: 应届生入职半年的工作感受,CRUD业务代码的价值、技术积累靠工作之余、从学校到职场的转变心得分享。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/internet-addiction-teenager.md b/docs/about-the-author/internet-addiction-teenager.md
index 78f94e2a483..82788023c3c 100644
--- a/docs/about-the-author/internet-addiction-teenager.md
+++ b/docs/about-the-author/internet-addiction-teenager.md
@@ -1,5 +1,6 @@
---
title: 我曾经也是网瘾少年
+description: 从网瘾少年到程序员的成长经历,初中沉迷游戏、高中觉醒奋起直追、高考失眠的真实故事,分享如何克服网瘾专注学习。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/javaguide-100k-star.md b/docs/about-the-author/javaguide-100k-star.md
index e89060dbe27..da851386ee9 100644
--- a/docs/about-the-author/javaguide-100k-star.md
+++ b/docs/about-the-author/javaguide-100k-star.md
@@ -1,5 +1,6 @@
---
title: JavaGuide 开源项目 100K Star 了!
+description: JavaGuide开源项目达成100K Star里程碑,从2018年创建到突破十万星标的复盘总结,分享开源维护心得与未来规划。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md b/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
index 2fa306d2fe9..67306b969fa 100644
--- a/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
+++ b/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
@@ -1,5 +1,6 @@
---
title: 某培训机构盗我文章做成视频还上了B站热门
+description: 原创文章被培训机构盗用制作成B站视频的维权经历,揭露培训机构剽窃原创引流的套路,呼吁尊重原创内容。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/my-college-life.md b/docs/about-the-author/my-college-life.md
index 43d96bd4186..4df47ca785d 100644
--- a/docs/about-the-author/my-college-life.md
+++ b/docs/about-the-author/my-college-life.md
@@ -1,5 +1,6 @@
---
title: 害,毕业三年了!
+description: 双非一本程序员的大学四年,从参加社团活动到办补习班赚钱、确定Java后端方向、创建JavaGuide、最终拿到ThoughtWorks offer的真实经历。
category: 走近作者
star: 1
tag:
diff --git a/docs/about-the-author/writing-technology-blog-six-years.md b/docs/about-the-author/writing-technology-blog-six-years.md
index 9e18a67d8c4..b03faf75e76 100644
--- a/docs/about-the-author/writing-technology-blog-six-years.md
+++ b/docs/about-the-author/writing-technology-blog-six-years.md
@@ -1,5 +1,6 @@
---
title: 坚持写技术博客六年了!
+description: 坚持写技术博客六年的心得分享,写博客的好处、如何坚持下去、写哪些方向的博客、实用写作技巧等经验总结。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/zhishixingqiu-two-years.md b/docs/about-the-author/zhishixingqiu-two-years.md
index dd0455a3f13..f1f7885390a 100644
--- a/docs/about-the-author/zhishixingqiu-two-years.md
+++ b/docs/about-the-author/zhishixingqiu-two-years.md
@@ -1,12 +1,13 @@
---
-title: 我的知识星球 4 岁了!
+title: 我的知识星球 6 岁了!
+description: JavaGuide知识星球介绍,提供Java面试指北专栏、简历修改、一对一答疑等服务,已帮助9000+球友提升求职竞争力。
category: 知识星球
star: 2
---
在 **2019 年 12 月 29 号**,经过了大概一年左右的犹豫期,我正式确定要开始做一个自己的星球,帮助学习 Java 和准备 Java 面试的同学。一转眼,已经六年了。感谢大家一路陪伴,我会信守承诺,继续认真维护这个纯粹的 Java 知识星球,不让信任我的读者失望。
-
+
我是比较早一批做星球的技术号主,也是坚持做下来的那一少部人(大部分博主割一波韭菜就不维护星球了)。最开始的一两年,纯粹靠爱发电。当初定价非常低(一顿饭钱),加上刚工作的时候比较忙,提供的服务也没有现在这么多。
@@ -46,29 +47,34 @@ star: 2
- **独家面试手册**:多本原创 PDF 后端面试手册免费领取,全网独家。
- **有问必答**:一对一免费提问,提供专属求职指南,拒绝焦虑。
+**🚀 实战项目**
+
+星球已经推出的实战项目如下:
+
+- [⭐AI 智能面试辅助平台 + RAG 知识库](https://javaguide.cn/zhuanlan/interview-guide.html):基于 Spring Boot 4.0 + Java 21 + Spring AI 2.0 开发。非常适合作为学习和简历项目,学习门槛低,帮助提升求职竞争力,是主打就业的实战项目。
+- [手写 RPC 框架](https://javaguide.cn/zhuanlan/handwritten-rpc-framework.html):从零开始基于 Netty+Kyro+Zookeeper 实现一个简易的 RPC 框架。麻雀虽小五脏俱全,项目代码注释详细,结构清晰。
+
+今年陆续还会推出更多企业级实战案例(预告一下,下一个是大家期待的:**企业智能客服**)!
+
🔥 **氛围与福利**
- **海量资源**:Java 优质面试资源持续更新分享。
- **抱团成长**:打卡活动、读书交流、线下聚会,让学习之路不再孤单。
- **惊喜福利**:不定期节日抽奖、送书送课,福利拿到手软。
-🚀 **拥抱 AI**
-
-星球目前正在深度分享 **AI 编程** 方法论,并计划推出 **AI 实战项目**。
-
💡 **总结**:这里的任何一项服务(尤其是简历修改和面试资料),单独拎出来的价值都已远超星球门票。
-这里赠送一个 **30** 元的星球新人专属优惠券(数量有限,价格即将上调)!
+目前星球正在做活动,两本书的价格,就能让你拥有上万培训班的服务!
-
+这里再提供一张 **30**元的优惠卷(**价格马上上调,老用户扫码续费半价** ):
-老用户续费可以添加微信(**javaguide1024**)领取一个半价基础基础上的续费优惠卷,记得备注 **“续费”** 。
+
### 专属专栏
星球更新了 **《Java 面试指北》**、**《Java 必读源码系列》**(目前已经整理了 Dubbo 2.6.x、Netty 4.x、SpringBoot2.1 的源码)、 **《从零开始写一个 RPC 框架》**(已更新完)、**《Kafka 常见面试题/知识点总结》** 等多个优质专栏。
-
+
《Java 面试指北》内容概览:
@@ -76,6 +82,17 @@ star: 2
进入星球之后,这些专栏即可免费永久阅读,永久同步更新!
+### 实战项目
+
+星球已经推出的实战项目如下:
+
+- [⭐AI 智能面试辅助平台 + RAG 知识库](https://javaguide.cn/zhuanlan/interview-guide.html):基于 Spring Boot 4.0 + Java 21 + Spring AI 2.0 开发。非常适合作为学习和简历项目,学习门槛低,帮助提升求职竞争力,是主打就业的实战项目。
+- [手写 RPC 框架](https://javaguide.cn/zhuanlan/handwritten-rpc-framework.html):从零开始基于 Netty+Kyro+Zookeeper 实现一个简易的 RPC 框架。麻雀虽小五脏俱全,项目代码注释详细,结构清晰。
+
+今年陆续还会推出更多企业级实战案例!并且,星球还分享了很多高频项目经历的优化版介绍和面试准备(持续更新中)。
+
+
+
### PDF 面试手册
进入星球就免费赠送多本优质 PDF 面试手册。
@@ -120,7 +137,7 @@ JavaGuide 知识星球优质主题汇总传送门:
-
+- [项目介绍](./javaguide/intro.md)(JavaGuide 的诞生)
+- [贡献指南](./javaguide/contribution-guideline.md)(期待你的贡献,奖励丰富)
+- [常见问题](./javaguide/faq.md)(统一回复大家的一些疑问)
diff --git a/docs/about-the-author/README.md b/docs/about-the-author/README.md
index 12f6eab7f3f..43524d2ff58 100644
--- a/docs/about-the-author/README.md
+++ b/docs/about-the-author/README.md
@@ -1,5 +1,6 @@
---
title: 个人介绍 Q&A
+description: JavaGuide作者Guide个人介绍,19年本科毕业、大学期间变现20w+实现经济独立、坚持写博客的经历与收获分享。
category: 走近作者
---
diff --git a/docs/about-the-author/deprecated-java-technologies.md b/docs/about-the-author/deprecated-java-technologies.md
index 0146d71c4a3..84dc6e720b2 100644
--- a/docs/about-the-author/deprecated-java-technologies.md
+++ b/docs/about-the-author/deprecated-java-technologies.md
@@ -1,5 +1,6 @@
---
title: 已经淘汰的 Java 技术,不要再学了!
+description: 已淘汰的Java技术盘点,JSP、Struts、EJB、Java Applets、SOAP等过时技术不建议学习,附现代替代方案推荐。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/dog-that-copies-other-people-essay.md b/docs/about-the-author/dog-that-copies-other-people-essay.md
index 653b616eaab..2ae67150843 100644
--- a/docs/about-the-author/dog-that-copies-other-people-essay.md
+++ b/docs/about-the-author/dog-that-copies-other-people-essay.md
@@ -1,5 +1,6 @@
---
title: 抄袭狗,你冬天睡觉脚必冷!!!
+description: 原创文章被抄袭的无奈经历,知乎、CSDN多平台盗文现象吐槽,分享如何屏蔽低质量内容和维护原创权益。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/feelings-after-one-month-of-induction-training.md b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
index ed57578a907..8ea32dd5c74 100644
--- a/docs/about-the-author/feelings-after-one-month-of-induction-training.md
+++ b/docs/about-the-author/feelings-after-one-month-of-induction-training.md
@@ -1,5 +1,6 @@
---
title: 入职培训一个月后的感受
+description: ThoughtWorks入职培训一个月感受,从Windows切换到Mac的适应、TWU培训内容、Feedback反馈文化等新人入职体验分享。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
index cc9fe136749..d737f1a10b4 100644
--- a/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
+++ b/docs/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.md
@@ -1,5 +1,6 @@
---
title: 从毕业到入职半年的感受
+description: 应届生入职半年的工作感受,CRUD业务代码的价值、技术积累靠工作之余、从学校到职场的转变心得分享。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/internet-addiction-teenager.md b/docs/about-the-author/internet-addiction-teenager.md
index 78f94e2a483..82788023c3c 100644
--- a/docs/about-the-author/internet-addiction-teenager.md
+++ b/docs/about-the-author/internet-addiction-teenager.md
@@ -1,5 +1,6 @@
---
title: 我曾经也是网瘾少年
+description: 从网瘾少年到程序员的成长经历,初中沉迷游戏、高中觉醒奋起直追、高考失眠的真实故事,分享如何克服网瘾专注学习。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/javaguide-100k-star.md b/docs/about-the-author/javaguide-100k-star.md
index e89060dbe27..da851386ee9 100644
--- a/docs/about-the-author/javaguide-100k-star.md
+++ b/docs/about-the-author/javaguide-100k-star.md
@@ -1,5 +1,6 @@
---
title: JavaGuide 开源项目 100K Star 了!
+description: JavaGuide开源项目达成100K Star里程碑,从2018年创建到突破十万星标的复盘总结,分享开源维护心得与未来规划。
category: 走近作者
tag:
- 个人经历
diff --git a/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md b/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
index 2fa306d2fe9..67306b969fa 100644
--- a/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
+++ b/docs/about-the-author/my-article-was-stolen-and-made-into-video-and-it-became-popular.md
@@ -1,5 +1,6 @@
---
title: 某培训机构盗我文章做成视频还上了B站热门
+description: 原创文章被培训机构盗用制作成B站视频的维权经历,揭露培训机构剽窃原创引流的套路,呼吁尊重原创内容。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/my-college-life.md b/docs/about-the-author/my-college-life.md
index 43d96bd4186..4df47ca785d 100644
--- a/docs/about-the-author/my-college-life.md
+++ b/docs/about-the-author/my-college-life.md
@@ -1,5 +1,6 @@
---
title: 害,毕业三年了!
+description: 双非一本程序员的大学四年,从参加社团活动到办补习班赚钱、确定Java后端方向、创建JavaGuide、最终拿到ThoughtWorks offer的真实经历。
category: 走近作者
star: 1
tag:
diff --git a/docs/about-the-author/writing-technology-blog-six-years.md b/docs/about-the-author/writing-technology-blog-six-years.md
index 9e18a67d8c4..b03faf75e76 100644
--- a/docs/about-the-author/writing-technology-blog-six-years.md
+++ b/docs/about-the-author/writing-technology-blog-six-years.md
@@ -1,5 +1,6 @@
---
title: 坚持写技术博客六年了!
+description: 坚持写技术博客六年的心得分享,写博客的好处、如何坚持下去、写哪些方向的博客、实用写作技巧等经验总结。
category: 走近作者
tag:
- 杂谈
diff --git a/docs/about-the-author/zhishixingqiu-two-years.md b/docs/about-the-author/zhishixingqiu-two-years.md
index dd0455a3f13..f1f7885390a 100644
--- a/docs/about-the-author/zhishixingqiu-two-years.md
+++ b/docs/about-the-author/zhishixingqiu-two-years.md
@@ -1,12 +1,13 @@
---
-title: 我的知识星球 4 岁了!
+title: 我的知识星球 6 岁了!
+description: JavaGuide知识星球介绍,提供Java面试指北专栏、简历修改、一对一答疑等服务,已帮助9000+球友提升求职竞争力。
category: 知识星球
star: 2
---
在 **2019 年 12 月 29 号**,经过了大概一年左右的犹豫期,我正式确定要开始做一个自己的星球,帮助学习 Java 和准备 Java 面试的同学。一转眼,已经六年了。感谢大家一路陪伴,我会信守承诺,继续认真维护这个纯粹的 Java 知识星球,不让信任我的读者失望。
-
+
我是比较早一批做星球的技术号主,也是坚持做下来的那一少部人(大部分博主割一波韭菜就不维护星球了)。最开始的一两年,纯粹靠爱发电。当初定价非常低(一顿饭钱),加上刚工作的时候比较忙,提供的服务也没有现在这么多。
@@ -46,29 +47,34 @@ star: 2
- **独家面试手册**:多本原创 PDF 后端面试手册免费领取,全网独家。
- **有问必答**:一对一免费提问,提供专属求职指南,拒绝焦虑。
+**🚀 实战项目**
+
+星球已经推出的实战项目如下:
+
+- [⭐AI 智能面试辅助平台 + RAG 知识库](https://javaguide.cn/zhuanlan/interview-guide.html):基于 Spring Boot 4.0 + Java 21 + Spring AI 2.0 开发。非常适合作为学习和简历项目,学习门槛低,帮助提升求职竞争力,是主打就业的实战项目。
+- [手写 RPC 框架](https://javaguide.cn/zhuanlan/handwritten-rpc-framework.html):从零开始基于 Netty+Kyro+Zookeeper 实现一个简易的 RPC 框架。麻雀虽小五脏俱全,项目代码注释详细,结构清晰。
+
+今年陆续还会推出更多企业级实战案例(预告一下,下一个是大家期待的:**企业智能客服**)!
+
🔥 **氛围与福利**
- **海量资源**:Java 优质面试资源持续更新分享。
- **抱团成长**:打卡活动、读书交流、线下聚会,让学习之路不再孤单。
- **惊喜福利**:不定期节日抽奖、送书送课,福利拿到手软。
-🚀 **拥抱 AI**
-
-星球目前正在深度分享 **AI 编程** 方法论,并计划推出 **AI 实战项目**。
-
💡 **总结**:这里的任何一项服务(尤其是简历修改和面试资料),单独拎出来的价值都已远超星球门票。
-这里赠送一个 **30** 元的星球新人专属优惠券(数量有限,价格即将上调)!
+目前星球正在做活动,两本书的价格,就能让你拥有上万培训班的服务!
-
+这里再提供一张 **30**元的优惠卷(**价格马上上调,老用户扫码续费半价** ):
-老用户续费可以添加微信(**javaguide1024**)领取一个半价基础基础上的续费优惠卷,记得备注 **“续费”** 。
+
### 专属专栏
星球更新了 **《Java 面试指北》**、**《Java 必读源码系列》**(目前已经整理了 Dubbo 2.6.x、Netty 4.x、SpringBoot2.1 的源码)、 **《从零开始写一个 RPC 框架》**(已更新完)、**《Kafka 常见面试题/知识点总结》** 等多个优质专栏。
-
+
《Java 面试指北》内容概览:
@@ -76,6 +82,17 @@ star: 2
进入星球之后,这些专栏即可免费永久阅读,永久同步更新!
+### 实战项目
+
+星球已经推出的实战项目如下:
+
+- [⭐AI 智能面试辅助平台 + RAG 知识库](https://javaguide.cn/zhuanlan/interview-guide.html):基于 Spring Boot 4.0 + Java 21 + Spring AI 2.0 开发。非常适合作为学习和简历项目,学习门槛低,帮助提升求职竞争力,是主打就业的实战项目。
+- [手写 RPC 框架](https://javaguide.cn/zhuanlan/handwritten-rpc-framework.html):从零开始基于 Netty+Kyro+Zookeeper 实现一个简易的 RPC 框架。麻雀虽小五脏俱全,项目代码注释详细,结构清晰。
+
+今年陆续还会推出更多企业级实战案例!并且,星球还分享了很多高频项目经历的优化版介绍和面试准备(持续更新中)。
+
+
+
### PDF 面试手册
进入星球就免费赠送多本优质 PDF 面试手册。
@@ -120,7 +137,7 @@ JavaGuide 知识星球优质主题汇总传送门:VS Code / Cursor"]:::client + end + + subgraph Layer["MCP 层"] + direction LR + style Layer fill:#F5F7FA,color:#333333,stroke:#005D7B,stroke-width:2px + MCPClient["MCP Client
(连接管理)"]:::infra --> MCPServer["MCP Server
(功能接口)"]:::business + end + + subgraph Data["数据源层"] + direction LR + style Data fill:#F5F7FA,color:#333333,stroke:#005D7B,stroke-width:2px + LocalFiles["本地文件
Git 仓库"]:::storage + ExternalAPI["外部 API
GitHub / 天气"]:::storage + end + + App --> MCPClient + MCPServer --> LocalFiles + MCPServer --> ExternalAPI + + linkStyle default stroke-width:2px,stroke:#333333,opacity:0.8 +``` + +**组件详解:** + +| 组件 | 定位 | 职责 | 代表产品 | 失败路径与性能指标 | +| --------------- | ----------- | ----------------------------------------------- | -------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------- | +| **MCP Host** | 用户交互层 | 运行 AI 应用,托管 LLM,管理 MCP Client | Claude Desktop v1.0、VS Code (Cline)、Cursor | Server 崩溃时需自动重连;建议支持 50+ 并发 Server 连接 | +| **MCP Client** | 连接管理层 | 与 MCP Server 建立 1:1 连接,转发 JSON-RPC 请求 | 集成在 Host 内部 | **失败路径**:断连时需指数退避重连(初始 1s,最大 60s);**性能指标**:连接建立 P99 < 100ms | +| **MCP Server** | 能力暴露层 | 实现 MCP 协议,暴露 Resources/Tools 等能力 | 开发者使用 SDK 开发 | **失败路径**:资源不存在返回 `-32004`,权限不足返回 `-32003`;**性能指标**:Tool 调用 P99 < 200ms,Resources 加载 P99 < 500ms | +| **Data Source** | 数据/服务层 | 提供实际数据或执行操作 | 文件系统、数据库、外部 API | 需实现连接池和熔断,防止级联故障 | + +**重要特性:** + +1. **一对多关系**:一个 Host 可以管理多个 Client,每个 Client 对应一个 Server +2. **解耦设计**:Client 和 Server 通过 JSON-RPC 通信,不依赖具体实现 +3. **多实例支持**:可以同时连接多个不同功能的 MCP Server + +> 🐛 **常见误区**: +> +> 很多开发者认为 Host 直接连接 Server。实际上,Host 内部会为每个配置的 Server 创建独立的 Client 实例。这种设计使得不同 Server 之间的连接互不影响。 + +### ⭐️ 请描述 MCP 的完整工作流程 + +MCP 的工作流程可以分为 **7 个步骤**: + +```mermaid +sequenceDiagram + participant U as User + participant H as Host (LLM) + participant C as MCP Client + participant S as MCP Server + participant D as Data Source + + U->>H: 提问: "分析这个仓库的最新提交" + H->>H: 思考 (Chain of Thought) + H->>C: Call Tool: list_commits() + C->>S: JSON-RPC Request
{method: "tools/call", params: ...} + S->>D: Fetch Git Logs + D-->>S: Return Logs + S-->>C: JSON-RPC Response
{result: ...} + C-->>H: Tool Output + H->>H: 思考与总结 + H-->>U: 返回分析结果 +``` + +**步骤详解:** + +| 步骤 | 描述 | 关键点 | +| ------------------ | ------------------------------------ | ------------------------------ | +| **1. 用户请求** | 用户通过 Host 发送问题 | Host 首先接收用户输入 | +| **2. LLM 推理** | Host 内部的 LLM 判断是否需要外部能力 | 使用 Chain of Thought 进行思考 | +| **3. 工具调用** | LLM 决定调用哪个 Tool | 通过 Client 发起调用 | +| **4. 协议转换** | Client 将调用转换为 JSON-RPC 请求 | 标准化的消息格式 | +| **5. Server 处理** | MCP Server 解析请求并访问数据源 | 业务逻辑的真正执行者 | +| **6. 数据返回** | 结果沿原路返回给 LLM | JSON-RPC Response | +| **7. 最终生成** | LLM 结合工具结果生成最终回复 | 用户体验的核心环节 | + +### MCP 使用什么通信协议? + +#### JSON-RPC 2.0 + +MCP 采用 **JSON-RPC 2.0** 作为应用层通信协议,原因如下: + +| 优势 | 说明 | +| ------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| **轻量级** | 相比 gRPC,JSON-RPC 无需通过 Protobuf 进行额外的跨语言编译和桩代码生成,降低了接入阻力。但作为 Trade-off,JSON-RPC 缺乏原生的强类型约束,MCP 必须在应用层强依赖 JSON Schema 对 Tool 的入参进行严格的结构化声明与运行时校验。 | +| **传输无关** | 可以运行在 stdio、HTTP、WebSocket 等多种传输层之上 | +| **易调试** | 纯文本格式,便于人工阅读和调试 | +| **广泛支持** | 几乎所有编程语言都有成熟的 JSON-RPC 库 | + +**JSON-RPC 消息格式:** + +```json +// 请求 +{ + "jsonrpc": "2.0", + "method": "tools/call", + "params": { + "name": "read_file", + "arguments": { "path": "/path/to/file.txt" } + }, + "id": 1 +} + +// 响应 +{ + "jsonrpc": "2.0", + "id": 1, + "result": { + "content": [ + { + "type": "text", + "text": "文件内容..." + } + ] + }, + "error": null // error 和 result 互斥 +} +``` + +#### JSON-RPC vs HTTP + +| 对比维度 | HTTP (RESTful) | JSON-RPC | +| ------------ | ---------------------------- | -------------------------- | +| **语义模型** | 面向资源 (Resource-Oriented) | 面向操作 (Action-Oriented) | +| **调用方式** | GET/POST/PUT/DELETE + URI | method 名 + 参数 | +| **数据格式** | 灵活 (JSON/XML/HTML) | 严格 JSON | +| **功能特性** | 丰富 (状态码/缓存/重定向) | 极简 (仅 RPC 规范) | +| **适用场景** | 公开 API、Web 服务 | 内部通信、工具调用 | + +> 🌈 **拓展阅读**: +> +> - [JSON-RPC 2.0 官方规范](https://www.jsonrpc.org/specification) +> - [A gRPC transport for the Model Context Protocol](https://cloud.google.com/blog/products/networking/grpc-as-a-native-transport-for-mcp) + +### ⭐️ MCP 支持哪些传输方式? + +#### stdio(标准输入/输出) + +| 特性 | 说明 | +| ------------ | ------------------------------------------------------- | +| **适用场景** | 本地进程间通信 (IPC) | +| **实现方式** | Host 启动 MCP Server 作为子进程,通过 stdin/stdout 通信 | +| **优势** | 极度轻量,无网络开销,启动快 | +| **典型应用** | Claude Desktop、本地 IDE 插件 | + +**安全提示**:stdio 模式下 MCP Server 与 Host 同权限,恶意 Server 可读取任意文件。生产环境必须采用以下防护措施: + +- **系统级隔离**:引入基于 **cgroups** 与 **namespace** 的沙箱(如 Docker/gVisor),建议限制 **CPU < 10%** 配额、内存 < 512MB,防止资源耗尽。 +- **进程管理**:配置子进程的 **SIGTERM/SIGKILL** 优雅退出钩子,防止僵尸进程和文件描述符泄漏。 +- **源码审计**:审阅社区 Server 的源代码,只使用可信来源的 Server;建议建立沙箱突破审计日志。 +- **网络限制**:沙箱内禁止出站网络连接,防范数据外泄。 + +**Streamable HTTP 模式增强安全**: + +- **认证机制**:每条请求携带标准 `Authorization` 头,支持 OAuth 2.0 或 API Key 认证(旧版 HTTP+SSE 只在建立 SSE 连接时校验一次,后续请求无法逐条鉴权)。 +- **传输加密**:强制 TLS 1.3,防止中间人攻击。 +- **访问控制**:基于 RBAC 限制 Resources 和 Tools 的访问权限。 + +#### Streamable HTTP(推荐) + +> MCP 协议版本 `2025-03-26` 正式引入 Streamable HTTP 传输方式,取代了旧版的 HTTP+SSE。旧版 HTTP+SSE 使用两个端点(`/sse` 持久连接 + `/sse/messages` 发送消息),已**标记为废弃**,不建议在新项目中使用。 + +| 特性 | 说明 | +| -------------- | --------------------------------------------------------------------------------------------------------- | +| **适用场景** | 远程部署、独立服务、生产环境 | +| **实现方式** | 单端点(如 `/mcp`),客户端 POST 发送 JSON-RPC 请求,服务端按需返回 JSON 响应或 SSE 流 | +| **优势** | 标准兼容性好(负载均衡器、API 网关、CORS 中间件开箱即用),每条请求独立鉴权,无需维护长连接 | +| **典型应用** | Web 应用、团队共享的 MCP 服务、云端托管 MCP Server | + +**Streamable HTTP 核心机制**: + +| 能力 | 说明 | +| ---------------- | -------------------------------------------------------------------------------------------------------- | +| **单端点交互** | 所有客户端→服务端消息通过 POST 发送到同一端点(如 `https://example.com/mcp`) | +| **灵活响应** | 服务端返回 `application/json`(简单请求-响应)或 `text/event-stream`(流式推送,如进度通知) | +| **会话管理** | 通过 `Mcp-Session-Id` 响应头分配会话 ID,客户端在后续请求中携带 | +| **可恢复性** | 基于 SSE 事件 ID + `Last-Event-ID` 请求头实现断线重连后消息补发 | +| **服务端推送** | 客户端可通过 GET 请求打开独立 SSE 流,接收服务端主动推送的通知和请求(可选能力) | + +**Streamable HTTP vs 旧版 HTTP+SSE 对比**: + +| 对比维度 | 旧版 HTTP+SSE(已废弃) | Streamable HTTP(当前推荐) | +| ------------ | ---------------------------------------------- | ------------------------------------------------- | +| **端点数量** | 两个(`/sse` + `/sse/messages`) | 一个(如 `/mcp`) | +| **连接模型** | 必须维护持久 SSE 连接 | 标准 HTTP 请求-响应,SSE 可选 | +| **认证** | 仅连接建立时校验,后续无法逐条鉴权 | 每条 POST 请求携带 `Authorization` 头,逐条鉴权 | +| **基础设施** | 需要粘性会话,与负载均衡器/API 网关兼容性差 | 与标准 HTTP 基础设施天然兼容 | +| **会话管理** | 非正式化 | `Mcp-Session-Id` 头,生命周期明确 | + +**选型决策**: + + + +#### 传输层异常与背压分析(生产级考量) + +| 风险类型 | stdio 模式 | Streamable HTTP 模式 | 工程防御手段 | +| ------------------------ | --------------------------------------------------------------------- | ---------------------------------- | ---------------------------------------------------------- | +| **子进程僵死** | 高:Server 异常退出时,Host 可能未正确回收子进程,产生 Zombie Process | 低:无子进程概念 | 配置 `SIGCHLD` 信号处理器 + `waitpid` 兜底回收 | +| **文件描述符泄漏** | 高:stdin/stdout 管道未关闭会导致 FD Leak,最终耗尽系统资源 | 低:标准 HTTP 连接,框架自动管理 | 设置 FD 上限(`ulimit -n`),实现连接池健康检查 | +| **连接中断** | 中:Server 崩溃导致管道断裂 | 低:每次请求独立,天然容错 | 指数退避重试 + 熔断机制(Circuit Breaker) | +| **背压(Backpressure)** | 缺失:stdio 无流量控制机制 | 原生支持:HTTP 状态码控制流量 | 实现滑动窗口限流,超出缓冲区时返回 `429 Too Many Requests` | + +## 工程实践 + +### 开发 MCP Server 时有哪些最佳实践? + +#### 1. 工具粒度设计 (Tool Granularity) + +**原则:单一职责,语义明确** + +| 反面示例 | 正面示例 | +| -------------------------------- | ---------------------------------------------------------- | +| `execute_sql(sql)` | `get_user_by_id(id)` / `list_active_orders()` | +| `file_operation(op, path, data)` | `read_file(path)` / `write_file(path, content)` | +| `database(action, params)` | `query_userByEmail(email)` / `updateUserProfile(id, data)` | + +**设计建议**: + +- 工具名称使用**动词+名词**形式:`get_`、`list_`、`create_`、`update_`、`delete_`。 +- 参数类型要**明确且可验证**:使用 JSON Schema 定义`。 +- 避免过度抽象:不要把多个操作塞进一个工具`。 + +#### 2. Context Window 管理 + +MCP 的 Resources 能力可能一次性加载大量文本,导致: + +| 问题 | 后果 | 解决方案 | +| -------------- | ---------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | +| 上下文溢出 | LLM 无法处理完整内容 | 实现**分块 (Chunking)** 逻辑 | +| 中间丢失 | LLM 忽略上下文中间的内容 | 提供**摘要 (Summarization)** | +| 成本过高 | Token 消耗过大 | 实现**按需加载**和**增量同步** | +| **OOM 风险** | **内存溢出导致 Server 被 Kill** | **严格限制单条资源大小(如 < 10MB),超出时返回元数据而非全文** | +| **Token 爆炸** | **超出上下文窗口触发截断,丢失关键信息** | **限制绝对字符长度(如 < 1MB)、返回分页元数据,或依赖 Host 端的 Context Window 截断机制**。**注意:** 由于 MCP Server 是模型无感知的,严禁硬编码特定模型的 Tokenizer(如 `tiktoken`)进行预计算,否则接入其他 LLM 平台时会失效。 | + +#### 3. 错误处理与用户体验 + +| 错误类型 | 处理方式 | +| ------------------ | -------------------------- | +| **参数验证失败** | 返回清晰的错误提示和建议 | +| **权限不足** | 说明所需权限和申请方式 | +| **服务暂时不可用** | 提供重试机制和预计恢复时间 | +| **部分失败** | 明确哪些操作成功、哪些失败 | + +#### 4. 安全防护 + +| 风险 | 防护措施 | +| ---------------- | ---------------------------- | +| **路径遍历攻击** | 验证文件路径,限制访问目录 | +| **SQL 注入** | 使用参数化查询,禁止拼接 SQL | +| **敏感信息泄露** | 脱敏处理,避免返回完整凭证 | +| **资源滥用** | 实现速率限制和配额管理 | + +#### 5. 调试与监控 + +**推荐工具**: + +- [**MCP Inspector**](https://modelcontextprotocol.io/docs/tools/inspector):官方调试工具,可模拟 Host 发送请求 + + ```bash + npx @modelcontextprotocol/inspector node my-server.js + ``` + +- **日志记录**:记录所有 JSON-RPC 请求和响应 +- **性能监控**:跟踪响应时间、错误率、Token 消耗 +- **健康检查**:实现 `/health` 端点用于监控 + +### 如何开发一个自定义的 MCP 服务器? + +**开发流程:** + +``` +1. 选择 SDK + ├─ TypeScript (官方首选) + ├─ Python + └─ Java (Spring AI) + +2. 定义能力 + ├─ Resources: 暴露哪些数据? + ├─ Tools: 提供哪些功能? + └─ Prompts: 有哪些常用操作模板? + +3. 实现业务逻辑 + └─ 连接数据源/服务,实现具体功能 + +4. 本地测试 + └─ 使用 MCP Inspector 验证 + +5. 部署配置 + └─ 在 Host 中配置 Server 启动命令 +``` + +**快速示例 (Python SDK):** + +```python +from mcp.server import Server +from mcp.types import Tool, TextContent + +# 创建 Server 实例 +server = Server("my-mcp-server") + +# 定义 Tool +@server.tool() +async def get_weather(city: str) -> str: + """获取指定城市的天气信息""" + # 实际业务逻辑 + return f"{city} 今天晴天,温度 25°C" + +# 定义 Resource +@server.resource("weather://forecast") +async def weather_forecast() -> str: + """返回未来一周天气预报""" + return "未来七天天气预报..." + +# 启动 Server +if __name__ == "__main__": + server.run() +``` + +**配置示例 (Claude Desktop):** + +```json +{ + "mcpServers": { + "my-server": { + "command": "python", + "args": ["/path/to/my_server.py"], + "env": { + "API_KEY": "your-api-key" + } + } + } +} +``` + +> ⚠️ **工程提示**:在生产环境中,Python MCP Server 依赖 `mcp` SDK,直接使用全局 `python` 命令会因依赖缺失而启动失败。请使用虚拟环境中的 Python 解释器路径(如 `/path/to/venv/bin/python`),或推荐使用现代化包管理器(如 `uvx` 或 `npx`),例如: +> +> ```json +> { +> "command": "uvx", +> "args": ["--from", "mcp", "python", "/path/to/my_server.py"] +> } +> ``` +> +> 启动失败时,可查看 Claude Desktop 的 `mcp.log` 排查问题。 + +## 拓展阅读 + +### 官方资源 + +- [MCP 官方文档](https://modelcontextprotocol.io/) +- [MCP GitHub 仓库](https://github.com/modelcontextprotocol) +- [MCP Inspector 调试工具](https://github.com/modelcontextprotocol/inspector) + +### 社区资源 + +- [Awesome MCP Servers](https://github.com/punkpeye/awesome-mcp-servers) +- [MCP 官方 SDK](https://github.com/modelcontextprotocol/servers) + +### 推荐文章 + +1. [从原理到示例:Java开发玩转MCP - 阿里云开发者](https://mp.weixin.qq.com/s/TYoJ9mQL8tgT7HjTQiSdlw) +2. [MCP 实践:基于 MCP 架构实现知识库答疑系统 - 阿里云开发者](https://mp.weixin.qq.com/s/ETmbEAE7lNligcM_A_GF8A) +3. [从零开始教你打造一个MCP客户端](https://mp.weixin.qq.com/s/zYgQEpdUC5C6WSpMXY8cxw) + +## 总结 + +MCP 协议的出现,标志着 AI 应用开发从"各自为战"走向"标准化协作"的时代。通过本文,我们系统梳理了 MCP 的核心知识: + +**核心要点回顾**: + +1. **MCP 是什么**:AI 领域的"USB-C 接口",通过 JSON-RPC 2.0 统一了 LLM 与外部工具的通信规范 +2. **四大核心能力**:Resources(只读数据)、Tools(可执行动作)、Prompts(预设指令)、Sampling(请求 LLM 推理) +3. **四层架构**:Host → Client → Server → Data Source,一对多连接,模型无感知 +4. **传输方式**:stdio(本地)、Streamable HTTP(远程),各有适用场景 +5. **生产级实践**:工具粒度设计、Context Window 管理、安全防护、失败路径处理 + +**与其他概念的区别**: + +- MCP vs Function Calling:MCP 是协议标准,Function Calling 是 LLM 能力 +- MCP vs Agent:MCP 是基础设施,Agent 是应用层系统 + +**学习建议**: + +1. **动手实践**:写一个简单的 MCP Server,理解 Host-Client-Server 的交互流程 +2. **阅读官方文档**:MCP 规范还在快速演进,保持对官方文档的关注 +3. **关注生态**:Awesome MCP Servers 收集了大量开源实现,是学习的好素材 + +MCP 为 AI 应用的规模化落地提供了标准化的基础设施,掌握它将让你在 AI 应用开发中如虎添翼。 diff --git a/docs/ai/agent/prompt-engineering.md b/docs/ai/agent/prompt-engineering.md new file mode 100644 index 00000000000..e69de29bb2d diff --git a/docs/ai/agent/skills.md b/docs/ai/agent/skills.md new file mode 100644 index 00000000000..fa00efb777c --- /dev/null +++ b/docs/ai/agent/skills.md @@ -0,0 +1,277 @@ +--- +title: 万字详解 Agent Skills:是什么?怎么用?和 Prompt、MCP 有什么区别? +description: 深入解析 Agent Skills 概念,探讨 Skills 与 Prompt、MCP、Function Calling 的本质区别,以及如何在实战中设计优秀的 Skill 固化代码规范。 +category: AI 应用开发 +icon: “skill” +head: + - - meta + - name: keywords + content: Agent Skills,MCP,Function Calling,Prompt,AI Agent,智能体,延迟加载,上下文注入 +--- + +2025 年初,Anthropic 在推出 **MCP(Model Context Protocol)** 之后,进一步提出了 **Agent Skills** 的概念。这不是技术倒退,而是对智能体架构的深度思考——**连接性(Connectivity)与能力(Capability)应该分离**。 + +很多开发者认为”只要提示词写得好,AI 就能帮我做一切”。但事实是:**Prompt 适合单次任务,Skills 才是构建可复用 AI 能力的正确方式**。 + +Skills 的出现,标志着 AI 应用从”玩具”走向”工具”、从”个人技巧”走向”工程化”的关键转折。今天 Guide 就带大家彻底搞懂这个概念,深入探讨 Skills 的设计理念、与相关技术的本质区别,以及如何在实战中用好这个能力。本文接近 1.2w 字,建议收藏,通过本文你将搞懂: + +1. ⭐ **Skills 是什么**:为什么说 Skill 是”延迟加载”的 sub-agent?它的核心机制——上下文注入和延迟加载是如何工作的? +2. ⭐ **Skills vs Prompt vs MCP vs Function Calling**:这四者的本质区别是什么?它们分别适用于什么场景?这是面试中的高频盲区。 +3. ⭐ **优秀的 Skill 长什么样**:一个设计良好的 Skill 应该包含哪些要素?元数据、触发条件、执行流程如何设计? +4. ⭐ **项目实战**:如何在真实开发中用 Skills 固化代码规范、排查流程、Review 标准?如何把团队中的”隐性知识”变成可复用的 AI 能力? + +## Skills 是什么? + +用一句话概括:**Skill 是一个用自然语言定义的、具有特定领域上下文(Domain Context)的逻辑指令集,本质上是通过延迟加载(Lazy Loading)优化 Token 消耗的 Sub-Agent(子智能体)**。 + +在团队协作中,很多"隐性知识"都在老员工脑子里,比如代码规范、排查流程、Review 标准。Skills 的核心价值,就是**把这些隐性规则变成显性的文档(SOP),让 AI 能够自主阅读、理解并执行**。 + +与传统编程不同,Skills 不强制规定每一步的代码逻辑,而是**用自然语言将决策权下放给模型**——模型通过 `load_skill()` 动态加载 `SKILL.md` 后,将其中定义的规则、流程和约束**实时注入到推理上下文**中,指导后续的工具调用和决策。这既保留了 Agent 处理不确定性的优势,又避免了纯代码编排的僵化。 + +> 为什么不用"基于 Function Calling 封装"?这个表述容易让人误以为 Skill 是某种 Function Calling 的语法糖。实际上,Skill 的核心机制是**上下文注入**——Agent 读取 Markdown 文档,把其中的规则和流程纳入推理上下文。Function Calling 只是 Agent 执行某些动作(如调脚本、查资源)时可能用到的底层手段,不是 Skills 本身的定义层。 +> +> 注意:`load_skill()` 是对"Agent 读取并激活 SKILL.md"这一过程的概念性描述,不同工具(Claude Code、Cursor 等)的实际触发方式会有差异。 + +**关键机制**: + +- **延迟加载(Lazy Loading)**:元数据保持简短(通常远少于正文)常驻上下文,正文仅在触发时动态注入,避免挤占 Token +- **动态上下文注入**:不同于静态文档的"阅读",Skills 是将规则实时注入推理上下文,直接影响模型决策 + +## Skills 和 Prompt、MCP、Function Calling有什么区别? + +这也是面试中常被问到的点,容易混淆: + +**1. Skills vs Prompt** + +| 维度 | Prompt | Skills | +| :----------- | :------------------------- | :----------------------------- | +| **本质** | 单次对话的文本指令 | 可持久化、可发现的**能力单元** | +| **复用性** | 随对话上下文丢失,难以维护 | 标准化封装,跨项目、多场景复用 | +| **加载机制** | 全量载入(挤占 Token) | **延迟加载**(按需读取正文) | + +- **Prompt**:用户即时表达意图的载体(如"分析这份报表")。 +- **Skills**:包含**元数据(何时使用)+ 正文(如何执行)**的完整方案,通过 `load_skill()` 机制按需加载到上下文。 + +**2. Skills vs MCP** + +这是最容易产生误解的地方。 + +| 维度 | MCP (Model Context Protocol) | Skills | +| :----------- | :----------------------------------------- | :--------------------------------------------- | +| **核心思路** | **标准化连接**:通过 JSON-RPC 统一数据格式 | **逻辑编排**:用自然语言描述复杂执行路径 | +| **定义方式** | 在 Server 端用代码(TS/Python)写死逻辑 | 在 `SKILL.md` 中用自然语言引导模型决策 | +| **环境依赖** | 需要运行一个 MCP Server 进程 | 依赖可执行环境(如本地 Shell 或沙箱) | +| **哲学** | **以协议为中心**:一次编写,所有 AI 通用 | **以模型为中心**:利用模型推理能力处理不确定性 | + +- **MCP 解决的是连通性** :它像 USB-C,让 AI 能以统一格式读文件、查数据库。 +- **Skills 解决的是编排逻辑** :它像一份说明书,告诉 AI 如何执行复杂任务流——这些任务完全可以包括调用多个 MCP 工具。 +- **两者的关系** :它们**不是竞争关系**,而是解决不同层面的问题。MCP 负责把外部系统接入进来,Skills 负责决定什么时候用、怎么组合这些能力。一个高级 Skill 的底层往往就是调用多个 MCP 工具。 + + + +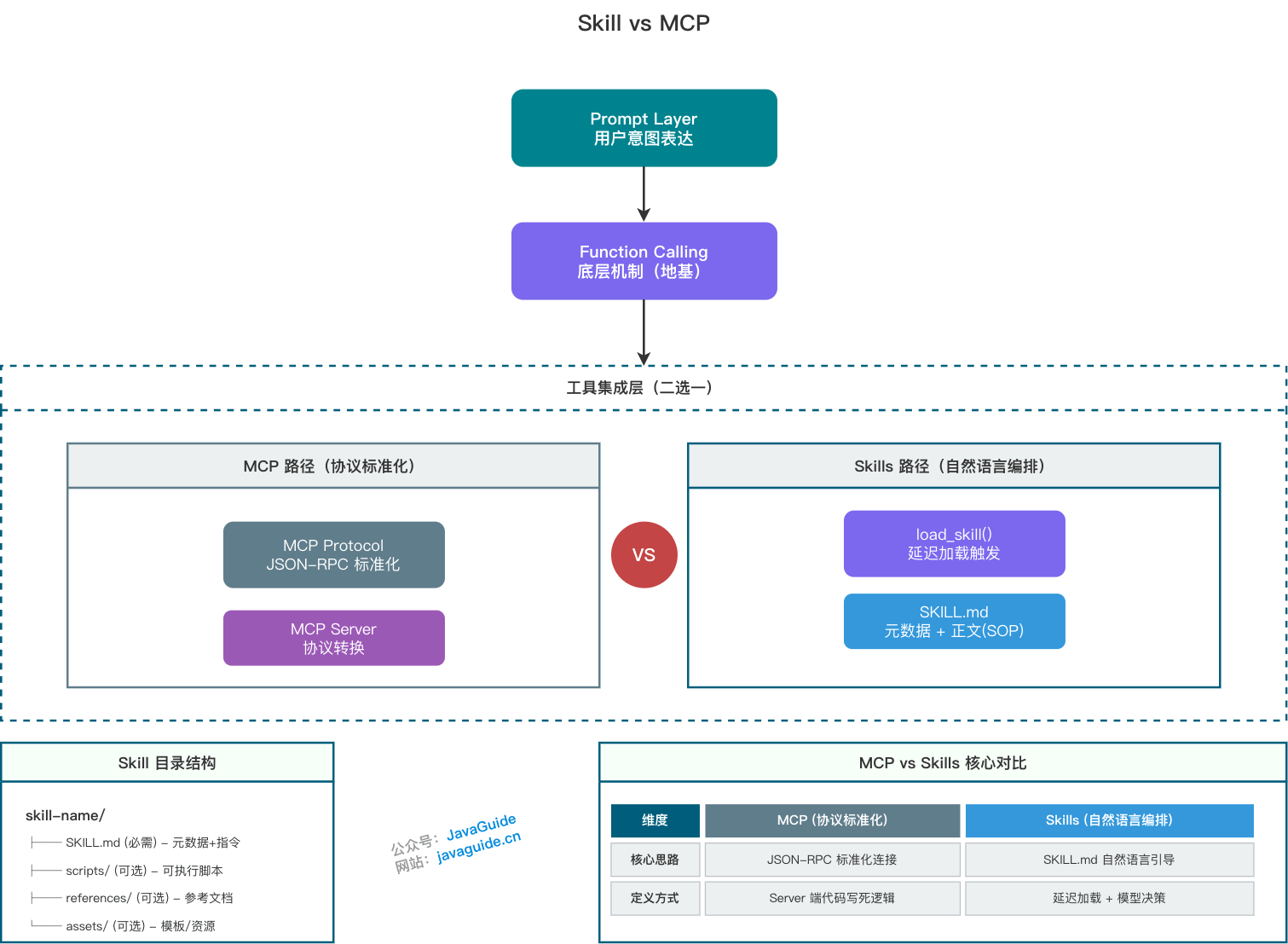 + +**3. Function Calling vs Skills** + +| 维度 | Function Calling | Skills | +| :----------- | :----------------------- | :---------------------------------------------------------------------- | +| **层级** | 底层机制 | 上层应用 | +| **依赖关系** | 基础能力 | 在执行时**可能使用** Function Calling(如加载文档、执行脚本、读取资源) | +| **粒度** | 原子操作(单次工具调用) | 复合流程(多步骤决策 + 工具组合) | + +Skills **没有创造新能力**,而是通过自然语言文档将能力组织成更易用的形式: + +1. Agent 读取 `SKILL.md`,将规则和流程注入推理上下文。 +2. 根据上下文指导,Agent 可能通过 Function Calling 执行脚本、读取资源或调用 MCP 工具。 + +**系统总结**: + +| **组件** | **一句话定义** | **形象类比** | **关键理解** | +| :------------------- | :------------------------- | :----------- | :-------------------------------------------------- | +| **Prompt** | 即时意图表达的载体 | 用户说的话 | 单次、易失 | +| **Function Calling** | LLM 输出结构化调用的能力 | 神经信号 | **一切的基础**,实现非结构化→结构化转换 | +| **MCP** | 标准化的工具接入协议 | USB-C 接口 | 解决外部系统"如何接入"(连通性) | +| **Skills** | 用自然语言定义的 sub-agent | 任务说明书 | 解决复杂任务"如何编排"(执行逻辑),可调用 MCP 工具 | + +**四层关系**:Function Calling 是地基 → Prompt 表达意图 → MCP 负责连通外部系统 → Skills 负责编排复杂任务流(可调用 MCP) + +这里需要澄清一个常见误解:MCP 和 Skills **不是竞争关系**,也**不是非此即彼**。 + +- **MCP** 解决外部系统如何接入:让 AI 能以统一格式读文件、查数据库、调用 API。 +- **Skills** 解决复杂任务如何编排:用自然语言定义执行流程,这些流程完全可以包含调用多个 MCP 工具。 + +在实际项目中,两者经常配合使用:一个 Skill 的正文里会指导 Agent 先用 MCP 读取数据库,再用 MCP 调用外部 API,最后生成报告。 + +**一句话总结**:Prompt 承载意图,Function Calling 实现交互,MCP 负责连通外部系统,Skills 负责编排复杂任务流——从'说什么'到'怎么做'再到'聪明地做'。 + +## Skills 长什么样?你是怎么用的? + +从结构上看,Skill 很简单,核心就是一个 `SKILL.md` 文件,包含**元数据**(描述什么时候用)和**正文**(具体的执行 SOP)。 + +**设计上的亮点是“渐进式披露”**: + +- **元数据**常驻上下文,AI 知道有哪些技能可用。 +- **正文**按需加载,只有触发时才读取,避免挤占 Token。 + +复杂点的 Skill,还会有附加的资源目录、脚本和参考文档。 + +Skill 的完整目录结构是这样的: + +``` +skill-name/ +├── SKILL.md # 必需:元数据(何时使用)+ 正文(指令、流程、示例) +├── scripts/ # 可选:可执行脚本(Python/Bash),按需调用 +├── references/ # 可选:参考文档,按需读取 +└── assets/ # 可选:模板、图片等资源 +``` + +**项目实战**: + +我在项目中主要用 Skills 来**固化工程标准**。比如定义一个 `code-reviewer` Skill,明确要求从架构合理性、异常处理完整性、日志规范、安全风险、性能隐患等多个维度进行结构化审查。这样 AI 在 Review 代码时,就不再是“随缘点评”,而是严格执行团队标准。这对于保持代码质量的一致性非常有用。 + +除了 Code Review,我也会定义其他 Skill,例如: + +- `api-endpoint-generator` - 按项目统一响应结构与异常模型生成标准化接口代码 +- `database-access-review` - 审查数据库访问逻辑,关注索引使用与慢查询风险 +- `refactor-analysis` - 先评估影响范围与依赖关系,再输出分步骤重构方案 +- `security-audit` - 扫描 SQL 拼接、XSS、权限绕过等常见安全风险 + +**优秀 Skill 示例**: + +- Code-Review-Expert(专家代码审查 Skill,以资深工程师视角进行结构化代码审查,覆盖:架构设计、SOLID 原则、安全性、性能问题、错误处理、边界条件):**https://github.com/sanyuan0704/code-review-expert** +- Git Commit with Conventional Commits(一个基于 Conventional Commits 规范的智能提交工具,可自动分析 diff、智能暂存文件并生成语义化 commit message,安全高效完成标准化 Git 提交):**https://github.com/github/awesome-copilot/blob/main/skills/git-commit/SKILL.md** +- TDD(测试驱动开发,先编写测试用例,观察它是否失败,然后编写最少的代码使其通过测试):**https://github.com/obra/superpowers/blob/main/skills/test-driven-development/SKILL.md** + +**https://skills.sh/** 这个网站上可以查找自己需要和热门的 Skiils。 + + + +这里 Guide 多提一下,回答这个问题的时候,你也可以说自己团队用到了一些开源的软件开发 Skills 集合,例如 Superpowers 中内置的。 + + + +另外,很多 AI 编程 CLI 和 IDE 也会内置一些开箱即用的 Skills,例如 Claude Code 就内置了: + +| 技能 | 功能 | 特点 | +| ----------------- | ------------------------------------------------ | ----------------------------------------------------------- | +| **/simplify** | 审查最近修改的文件(复用、质量、效率),自动修复 | 并行多代理审查,适合功能/修复后清理 | +| **/batch <指令>** | 大规模批量修改代码库 | 自动任务拆分,每个任务在隔离 git worktree 中执行,可批量 PR | +| **/debug [描述]** | 排查当前 Claude Code 会话问题 | 读取 debug log | + +## 如何编写高质量的 AI Agent Skills? + +很多开发者第一次接触 Skills 时,会下意识地把它当成"文档"来写——堆砌背景介绍、安装指南、版本历史……结果发现 AI 要么"读不懂",要么"不用它"。 + +**编写高质量的 Skills 是一项专门的技能**,它不是在写给人看的 README,而是在**给 AI 写执行协议**。这个区别决定了你需要完全不同的思维方式: + +- **写给人**:注重可读性、完整性、背景知识 +- **写给 AI**:注重精准性、可执行性、上下文效率 + +接下来的内容将系统性地介绍如何编写高质量的 Skills。这些原则来自 Anthropic 官方文档和社区大规模生产实践,经过实战验证,能够让你的 Skills 在实际使用中发挥最大价值。 + +### 语义精确的 Metadata(元数据) + +Metadata 是 Agent 进行任务路由的核心依据,尤其是 description,它充当 LLM 的“索引”。 + +- **原则**:消除歧义,明确边界,并融入意图触发词。 +- **优化逻辑**:从“描述功能”转向“定义场景、问题和触发条件”。 + +| 维度 | 不好的示例 | 优化的示例 | 说明 | +| -------- | ------------ | -------------------------------------------------------------------------------------------------- | --------------------------------- | +| 描述 | 分析系统日志 | 诊断 Spring Boot 生产环境的运行时异常,包括解析 Java 堆栈跟踪、定位 OOM 内存溢出和分析慢接口耗时。 | 边界清晰,避免泛化。 | +| 触发意图 | 无明确引导 | 当用户提到“接口报错”、“系统卡死”、“频繁 Full GC”或粘贴错误日志时,立即激活此技能。 | 提供具体触发词,便于 Agent 匹配。 | + +在 Metadata 中添加 `parameters` 字段,定义输入输出格式(如 YAML),帮助 LLM 减少幻觉。例如: + +```yaml +parameters: + input: { type: string, description: "错误日志或堆栈跟踪" } + output: { type: json, description: "诊断结果,包括根因和建议" } +``` + +### 模块化与单一职责 + +大型“全能” Skills 会导致 LLM 在参数构建时产生幻觉。Agentic Workflow 更适合细粒度工具矩阵。 + +- **原则**:按排查维度拆分,确保每个 Skill 单一职责(SRP)。 +- **优化方案**:避免单一“系统故障排查器”,改为工具集: + - `jvm-metrics-analyzer`:专责通过 Prometheus 采集 JVM 指标(如堆内存、线程数)。 + - `distributed-trace-finder`:利用 SkyWalking 或 Zipkin 追踪特定 TraceId 的链路耗时。 + - `k8s-pod-event-viewer`:专责查询 Kubernetes Pod 状态变更和重启记录。 + +### 确定性优先原则 + +对于需要严谨逻辑的计算或格式转化,**永远不要相信 LLM 的“直觉”**,要让它去驱动脚本。 + +- **原则**:LLM 负责**提取参数**,脚本负责**逻辑闭环**。 +- **案例优化**: 当 Agent 发现 CPU 负载过高时,不要让它“盲猜”哪个线程有问题,而是让它调用一个封装好的诊断脚本。 + +**Skill 定义中的执行逻辑:** + +> “如果 CPU 使用率超过 80%,请提取节点 IP,调用 `./scripts/capture_thread_dump.sh`。不要尝试在对话框中手动模拟线程分析,直接解析脚本返回的 **Top 3 耗时线程堆栈**。” + +### 渐进式披露策略 + +避免”信息过载”导致 Agent 迷失。通过文档的分层结构,让 Agent 只在需要时加载细节。 + +**三层结构建议**: + +1. **SKILL.md(主体)**:定义核心故障类型(4xx, 5xx)和标准排查流转(SOP)。 +2. **`troubleshooting-guide.md`(附加)**:放置一些罕见的”陈年老坑”或特定中间件(如 RocketMQ)的配置盲区。 +3. **runbooks/(数据文件)**:存储历史故障知识库,由 Agent 通过 RAG 检索后再参考,而不是一股脑塞进上下文。 + +### 总结 + +编写高质量 Skills 的 **五大核心原则**: + +| **原则** | **核心思想** | **关键实践** | +| -------------- | ------------------------ | ----------------------------------------- | +| **语义精确** | 从”描述功能”到”定义场景” | 用祈使句 + 触发关键词 + 明确边界 | +| **极简主义** | 上下文是公共资源 | 删除噪音,10 行示例代替100行文字 | +| **模块化** | 单一职责避免幻觉 | 按排查维度拆解,而非建立”全能工具” | +| **确定性优先** | 识别”脆弱操作” | LLM 提取参数,脚本负责逻辑闭环 | +| **渐进式披露** | 按需加载,避免上下文爆炸 | L1 元数据常驻 + L2 正文按需 + L3 资源隔离 | + +**记住**:Skills 不是文档,而是**执行协议**。 + +## 总结与选型建议 + +### 核心观点 + +Skills 和 MCP 代表了智能体技术栈中两个关键的抽象层: + +| **组件** | **一句话定义** | **形象类比** | **关键理解** | +| ---------- | -------------------------- | ------------ | ---------------------------------- | +| **MCP** | 标准化的工具接入协议 | USB-C 接口 | 解决外部系统"如何接入"(连通性) | +| **Skills** | 用自然语言定义的 sub-agent | 任务说明书 | 解决复杂任务"如何编排"(执行逻辑) | + +**两者不是竞争关系,而是互补关系**: + +- MCP 专注于"能力"(提供基础设施连接) +- Skills 专注于"智慧"(提供业务逻辑和领域知识) + +### 实践建议 + +| 场景 | 推荐方案 | 原因 | +| -------------------------------------- | -------------------------------- | ---------------------- | +| 外部服务连接(数据库、API、云服务) | **优先使用 MCP** | 标准化接口,易于维护 | +| 复杂工作流(多步骤任务、领域专业知识) | **优先使用 Skills** | 封装领域知识,可复用 | +| 上下文受限场景(长对话、大量工具) | **使用 Skills 进行渐进式管理** | 降低 token 消耗 90%+ | +| 企业级智能体构建 | **采用 MCP + Skills 的分层架构** | 关注点分离,易维护扩展 | + +### 面试准备要点 + +**高频问题**: + +1. **Skills 是什么?** → 延迟加载的 sub-agent,解决"如何编排"问题 +2. **Skills 和 MCP 的区别?** → MCP 负责连通性,Skills 负责执行逻辑,互补关系 +3. **如何降低 token 消耗?** → 渐进式披露:元数据常驻,正文按需加载 +4. **什么是渐进式披露?** → 三层架构:元数据 → 正文 → 附加资源 +5. **如何编写高质量 Skills?** → 精准 description + 单一职责 + 确定性优先 + +**追问准备**: + +- 你的团队用了哪些 Skills?如何组织的? +- 如何评估一个 Skill 的好坏? +- Skills 如何与 MCP 配合使用? +- 如何避免 Skills 的上下文污染问题? diff --git a/docs/ai/ai-coding/cc-glm5.1.md b/docs/ai/ai-coding/cc-glm5.1.md new file mode 100644 index 00000000000..a9955aa2286 --- /dev/null +++ b/docs/ai/ai-coding/cc-glm5.1.md @@ -0,0 +1,456 @@ +--- +title: Claude Code 接入第三方模型实战:JVM 智能诊断与慢查询治理 +description: 通过 Claude Code 接入 GLM-5.1 模型,完成 JVM 智能诊断助手从零搭建和百万级数据量慢查询治理两个实战任务,分享 AI 辅助编程的工作方法与踩坑经验。 +category: AI 编程实战 +head: + - - meta + - name: keywords + content: Claude Code,AI编程,GLM-5.1,JVM诊断,慢查询优化,AI辅助开发,Arthas,Agent,Spring AI +--- + +大家好,我是 Guide。前面分享过 [IDEA 搭配 Qoder 插件的实战](./idea-qoder-plugin.md)和 [Trae 接入大模型的实战](./trae-m2.7.md),分别覆盖了 JetBrains 体系和 VS Code 体系下的 AI 辅助编码。这篇换个角度,聊聊 **Claude Code 接入第三方模型** 的实战体验。 + +Claude Code 本身是 Anthropic 官方的 CLI 编码工具,但它支持通过环境变量切换底层模型。这意味着你不必局限于 Claude 系列,完全可以接入其他模型来使用。本文以 GLM-5.1 作为示例,但接入方式是通用的——换成其他兼容模型,流程基本一致。 + +我选了两个比较有代表性的复杂场景来验证: + +- **场景一**:从零搭建一个基于 Arthas 的 JVM 智能诊断 Agent,涵盖技术选型、架构设计、编码落地的完整流程 +- **场景二**:在百万级数据量的既有订单系统中定位并治理慢查询,考验 AI 对现有代码库的理解和增量优化能力 + +一个是从零开始的工程交付,另一个是面对既有系统的性能治理,正好覆盖 AI 辅助编程的两种典型工作模式。 + +## 环境准备:Claude Code 接入第三方模型 + +在正式开始之前,需要完成 Claude Code 与第三方模型的对接。整个配置过程分三步: + +**第一步**:安装 Claude Code + +```bash +npm i -g @anthropic-ai/claude-code@latest +``` + +**第二步**:安装 cc-switch 完成模型切换(macOS 用户可通过 homebrew 安装,详情参考 cc-switch 官方文档:
PDF / Word / HTML / DB 记录"/] + DOC -->|加载 & 解析| SPLIT + SPLIT["✂️ 文本分割器
按语义/标题/长度切分"] + SPLIT -->|产生 chunks| CHUNKS + CHUNKS[/"📑 文档片段
带元数据的文本块"/] + end + + subgraph Vectorization["向量化 & 存储"] + direction TB + CHUNKS -->|批量嵌入| EMB + EMB["🧠 嵌入模型
文本 → 语义向量"] + EMB -->|生成 embeddings| VEC + VEC[/"🔢 向量表示
高维稠密向量"/] + VEC -->|持久化存储| DB + DB[("🗄️ 向量数据库
Milvus / pgvector / Faiss")] + end + end + + %% 颜色主题:文档阶段暖色 → 向量阶段冷色渐变 + style DOC fill:#F4D03F,stroke:#D35400,color:#333 + style SPLIT fill:#52B788,stroke:#2E8B57,color:#fff + style CHUNKS fill:#E67E22,stroke:#D35400,color:#fff + style EMB fill:#3498DB,stroke:#2980B9,color:#fff + style VEC fill:#2980B9,stroke:#1ABC9C,color:#fff + style DB fill:#2C3E50,stroke:#1A252F,color:#fff + + %% 子图美化 + style PreProcess fill:#FFF3E0,stroke:#FFCC80,stroke-dasharray: 5 5 + style Vectorization fill:#E3F2FD,stroke:#90CAF9,stroke-dasharray: 5 5 + style Indexing fill:#F5F5F5,stroke:#BDBDBD,rx:20,ry:20 +``` + +检索通常在线进行的,当用户提交一个问题时,系统会使用已索引的文档来回答问题。该阶段通常包括以下步骤: + +1. **接收请求:** 接收用户的自然语言查询(Query),例如一个问题或任务描述。在某些进阶场景中,系统会先对原始查询进行改写或扩充,以提高后续检索的覆盖率。 +2. **查询向量化:** 使用嵌入模型(Embedding Model)将用户查询转换为语义向量表示(Query Embedding,也就是高维稠密向量),以捕捉查询的语义信息。 +3. **信息检索 (R):** 在嵌入存储(Embedding Store)中,通过语义相似性搜索找到与查询向量最相关的文档片段(Relevant Segments)。 +4. **生成增强 (A):** 将检索到的相关片段和原始查询作为上下文输入给 LLM,并使用合适的提示词引导 LLM 基于检索到的信息回答问题。 +5. **输出生成 (G):** 向用户输出自然语言回复,并附带相关的参考资料链接。 +6. **结果反馈(可选):** 如果用户对生成的结果不满意,可以允许用户提供反馈,通过调整提示词或检索方式优化生成效果。在某些实现中,支持多轮交互,进一步完善回答。 + +**检索阶段的简化流程图如下**: + +```mermaid +flowchart TB + subgraph Retrieval["🔍 检索阶段(在线推理)"] + direction TB + + subgraph QueryVectorization["查询向量化"] + direction LR + Q[/"💬 用户查询
自然语言问题或指令"/] + Q -->|语义编码| EMB2 + EMB2["🧠 嵌入模型
Query → 语义向量(同文档模型)"] + EMB2 -->|生成查询向量| QV + QV[/"🔢 查询向量
高维稠密向量"/] + end + + subgraph RetrieveAndGenerate["检索 & 生成"] + direction TB + QV -->|相似度搜索| DB2 + DB2[("🗄️ 向量数据库
Top-K 近似最近邻检索")] + DB2 -->|返回相关块| REL + REL[/"📑 相关片段
Top-K 最相似文档块"/] + REL -->|合并证据| CTX + Q -->|原始查询| CTX + CTX["🔗 上下文构建
Query + 相关片段(带元数据)"] + CTX -->|提示工程| LLM + LLM["🤖 大语言模型
生成式推理(带引用)"] + LLM -->|输出最终答案| ANS + ANS[/"✅ 生成答案
自然语言回复 + 来源引用"/] + end + end + + %% 颜色主题:查询暖色 → 向量/检索冷色 → 生成回归暖色 + style Q fill:#F4D03F,stroke:#D35400,color:#333 + style EMB2 fill:#52B788,stroke:#2E8B57,color:#fff + style QV fill:#E67E22,stroke:#D35400,color:#fff + style DB2 fill:#2C3E50,stroke:#1A252F,color:#fff + style REL fill:#E67E22,stroke:#D35400,color:#fff + style CTX fill:#3498DB,stroke:#2980B9,color:#fff + style LLM fill:#52B788,stroke:#2E8B57,color:#fff + style ANS fill:#F4D03F,stroke:#D35400,color:#333 + + %% 子图美化(与上一张保持一致) + style QueryVectorization fill:#FFF3E0,stroke:#FFCC80,stroke-dasharray: 5 5 + style RetrieveAndGenerate fill:#E3F2FD,stroke:#90CAF9,stroke-dasharray: 5 5 + style Retrieval fill:#F5F5F5,stroke:#BDBDBD,rx:20,ry:20 +``` + +## RAG 与传统搜索引擎的区别是什么? + +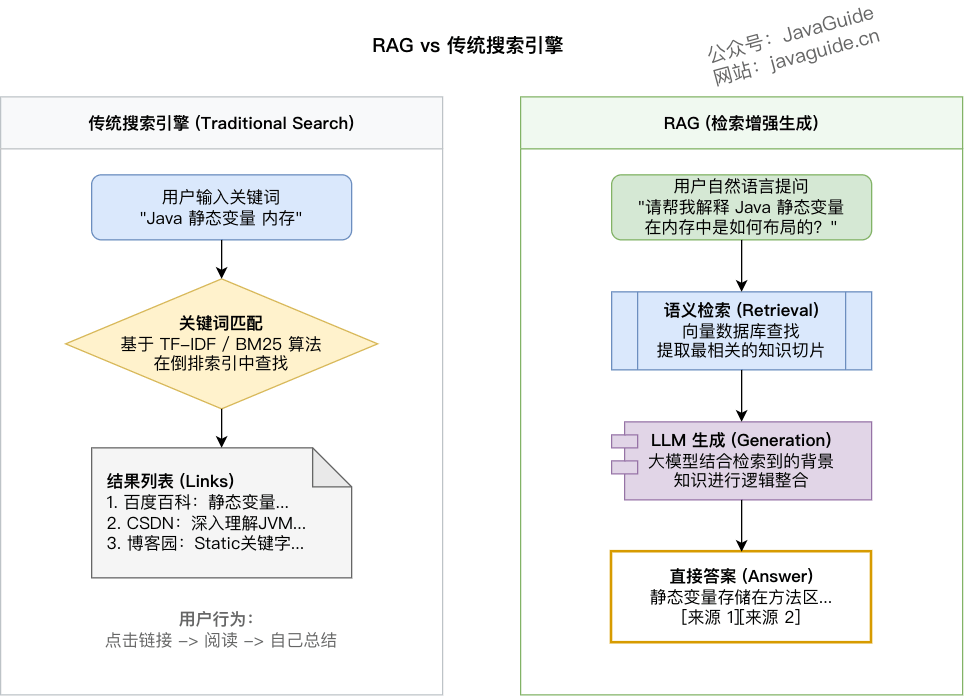 + +RAG 与传统搜索引擎虽然都涉及信息获取,但它们在**检索机制、信息处理和交付形式**上有本质区别: + +1. **检索机制:** + - **传统搜索**主要依赖**倒排索引与词汇匹配**(如 BM25、TF-IDF),对关键词的字面形式依赖强。虽然现代搜索引擎也引入了语义理解(如 BERT),但核心仍是基于词汇统计的相关性计算。 + - **RAG** 通常采用**向量语义搜索**,能够识别同义词和深层语境,解决语义鸿沟问题。 +2. **处理逻辑:** + - **传统搜索**本质是**相关性排序器**,将候选文档按相关性得分排序后直接呈现给用户。每个结果相对独立,不进行跨文档的信息融合。 + - **RAG** 的本质是 **信息综合器**,它会将检索到的多个知识碎片(Chunks)喂给 LLM,由模型进行逻辑归纳和跨文档的信息整合。 +3. **结果交付:** + - **传统搜索**提供候选文档列表(线索),需要用户二次阅读过滤; + - **RAG** 提供的是答案,能直接回答复杂指令,并通过引文标注(Citations)兼顾了信息的来源可追溯性。 +4. **时效性与数据范围:** 传统搜索更依赖大规模爬虫和全网索引;RAG 则常用于**私有知识库或垂直领域**,能低成本地让 LLM 获得实时或特定领域的知识补充,无需频繁微调模型。 + +## ⭐️ RAG 的核心优势和局限性分别是什么? + +RAG 的核心优势和局限性可以从**知识管理、工程落地和性能指标**三个维度来分析: + +**核心优势:** + +1. **知识时效性与低维护成本:** 相比微调,RAG 无需重新训练模型。只需更新向量数据库或知识库,模型就能立即获取最新信息,非常适合处理新闻、法规、产品文档等频繁变动的数据。这种即插即用的特性使得知识更新的成本从数千美元降低到几乎为零。 +2. **显著降低幻觉并提供引文追溯:** RAG 将模型从“基于参数化记忆生成”转变为“基于检索证据生成”。每个回答都有明确的信息来源,提供了关键的**可解释性和可验证性**。这对金融合规、医疗诊断、法律咨询等对准确性要求极高的场景至关重要。 +3. **数据安全与细粒度权限控制:** 可以在检索层实现精准的**多租户隔离和访问控制(ACL)**,确保用户只能检索其权限范围内的数据。相比将敏感数据通过微调“烧入”模型参数(存在数据泄露风险),RAG 的架构天然支持数据隔离和合规要求。 +4. **领域适应性强:** 无需针对特定领域重新训练模型,只需构建领域知识库即可快速适配垂直场景,如企业内部知识管理、专业技术支持等。 + +**局限性与工程挑战:** + +1. **严重的检索依赖性:** 遵循 GIGO(Garbage In, Garbage Out)原则。如果输入的信息质量不好,即便下游模型再强,也很难输出正确的结果。这个在 RAG 系统里体现得尤为明显。比如说,如果检索阶段的 embedding 表达不准确,或者分块策略不合理,导致召回的内容跟问题无关,那无论上下游用什么大模型,最终生成的答案也不会靠谱。 +2. **上下文窗口与推理噪声:** 虽然 Context Window 已经卷到了百万级(如 Claude 4.6 Opus 的 1M 上限),但这并不意味着我们可以“暴力喂养”。注入过多无关片段(Noisy Chunks)会造成**注意力稀释**,干扰模型的逻辑推理,且带来**不必要的 Token 开销**。 +3. **首字延迟(TTFT)增加:** 完整链路包括“查询改写 -> 向量化 -> 相似度检索 -> 重排序(Rerank)-> 上下文构建 -> LLM 生成”,每个环节都增加延迟。 +4. **工程复杂度:** 需要维护向量数据库、处理文档更新的增量索引、优化检索策略等,相比纯 LLM 应用复杂度大幅提升。 +5. **长文本 Token 成本:** 虽然省去了训练费,但单次请求携带大量上下文会导致推理成本(Input Tokens)显著高于普通对话。 + +## ⭐️ 更多 RAG 高频面试题 + +上面的内容摘自我的[星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)实战项目教程: [《SpringAI 智能面试平台+RAG 知识库》](https://javaguide.cn/zhuanlan/interview-guide.html)。内容安排如下(已经更完,一共 13w+ 字) + + + +Spring AI 和 RAG 面试题两篇加起来就接近 60 道题目,主打一个全面! + +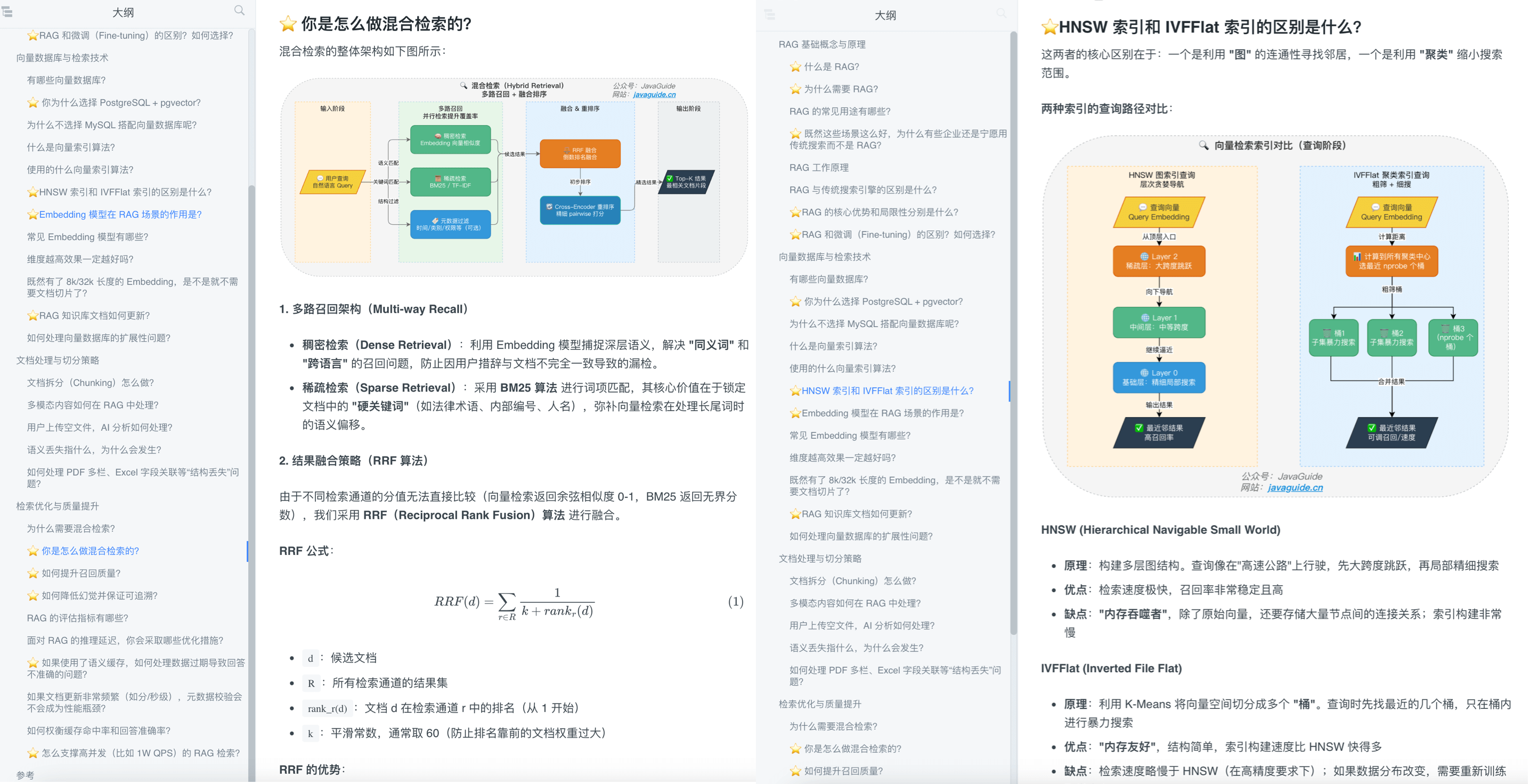 + +**项目地址** (欢迎 Star 鼓励): + +- Github:
diff --git a/docs/books/cs-basics.md b/docs/books/cs-basics.md
index e67ac115964..9e7a76c8674 100644
--- a/docs/books/cs-basics.md
+++ b/docs/books/cs-basics.md
@@ -1,5 +1,6 @@
---
title: 计算机基础必读经典书籍
+description: 计算机基础书籍推荐,操作系统、计算机网络、算法与数据结构、编译原理等核心课程经典教材和学习资源汇总。
category: 计算机书籍
icon: "computer"
head:
diff --git a/docs/books/database.md b/docs/books/database.md
index 87f92d24184..cfdbcac5adf 100644
--- a/docs/books/database.md
+++ b/docs/books/database.md
@@ -1,5 +1,6 @@
---
title: 数据库必读经典书籍
+description: 数据库书籍推荐,MySQL、PostgreSQL、Redis等数据库经典书籍,涵盖入门教程、原理剖析、性能优化等内容。
category: 计算机书籍
icon: "database"
head:
diff --git a/docs/books/distributed-system.md b/docs/books/distributed-system.md
index bb131d6dd65..89c15045e1e 100644
--- a/docs/books/distributed-system.md
+++ b/docs/books/distributed-system.md
@@ -1,5 +1,6 @@
---
title: 分布式必读经典书籍
+description: 分布式系统书籍推荐,DDIA、分布式事务、共识算法、微服务架构等经典书籍,掌握分布式系统设计核心知识。
category: 计算机书籍
icon: "distributed-network"
---
diff --git a/docs/books/java.md b/docs/books/java.md
index b93e77f2e83..be9f36197a0 100644
--- a/docs/books/java.md
+++ b/docs/books/java.md
@@ -1,5 +1,6 @@
---
title: Java 必读经典书籍
+description: Java程序员必读书籍推荐,Java基础、并发编程、JVM虚拟机、Spring/SpringBoot框架、Netty网络编程、性能调优等经典书籍精选。
category: 计算机书籍
icon: "java"
---
diff --git a/docs/books/search-engine.md b/docs/books/search-engine.md
index 50abbd57056..bf5ac35a82f 100644
--- a/docs/books/search-engine.md
+++ b/docs/books/search-engine.md
@@ -1,5 +1,6 @@
---
title: 搜索引擎必读经典书籍
+description: 搜索引擎书籍推荐,Lucene入门、Elasticsearch核心技术与实战、源码解析与优化实战等经典书籍精选。
category: 计算机书籍
icon: "search"
---
diff --git a/docs/books/software-quality.md b/docs/books/software-quality.md
index 5cfce79dfaa..5dccbb4afd1 100644
--- a/docs/books/software-quality.md
+++ b/docs/books/software-quality.md
@@ -1,5 +1,6 @@
---
title: 软件质量必读经典书籍
+description: 软件质量与代码整洁书籍推荐,重构、Clean Code、Effective Java、架构整洁之道等经典书籍,提升代码质量和架构设计能力。
category: 计算机书籍
icon: "highavailable"
head:
diff --git a/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md b/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md
index a55f179aa92..aa116d0d752 100644
--- a/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md
+++ b/docs/cs-basics/algorithms/10-classical-sorting-algorithms.md
@@ -1,5 +1,6 @@
---
title: 十大经典排序算法总结
+description: 系统梳理十大经典排序算法,附复杂度与稳定性对比,覆盖比较类与非比较类排序的核心原理与实现场景,帮助快速选型与优化。
category: 计算机基础
tag:
- 算法
@@ -7,9 +8,6 @@ head:
- - meta
- name: keywords
content: 排序算法,快速排序,归并排序,堆排序,冒泡排序,选择排序,插入排序,希尔排序,桶排序,计数排序,基数排序,时间复杂度,空间复杂度,稳定性
- - - meta
- - name: description
- content: 系统梳理十大经典排序算法,附复杂度与稳定性对比,覆盖比较类与非比较类排序的核心原理与实现场景,帮助快速选型与优化。
---
> 本文转自:连接状态 SYN_RCVD
放入 SYN queue + + C->>K: ACK 第三次握手 + Note over SQ,AQ: 内核收到 ACK 后完成握手
将连接从 SYN queue 迁移到 Accept queue
队列未满才可进入 + Note over AQ: 连接已完成 可被 accept
连接状态 ESTABLISHED + + App->>K: accept + K-->>App: 返回已就绪的 socket + Note over AQ: 该连接从 Accept queue 移除 +``` + +在 TCP 三次握手过程中,服务端内核通常会用两个队列来管理连接请求(不同操作系统/内核版本实现细节可能略有差异,下面以常见 Linux 行为为例): + +1. **半连接队列**(也称 SYN Queue): + - 保存“握手未完成”的请求:服务端收到 SYN 并回 SYN+ACK 后,连接进入 SYN_RCVD,等待客户端最终 ACK。 + - 如果一直收不到 ACK,内核会按重传策略重发 SYN+ACK,最终超时清理。 + - 常见相关参数:`net.ipv4.tcp_max_syn_backlog`;在 SYN Flood 场景下可配合 `net.ipv4.tcp_syncookies`。 +2. **全连接队列**(也称 Accept Queue): + - 保存“握手已完成但应用还没 accept”的连接:服务端收到最终 ACK 后连接变为 `ESTABLISHED`,并进入 全连接队列,等待应用层 `accept()` 取走。 + - 队列容量受 `listen(fd, backlog)` 与系统上限 `net.core.somaxconn` 共同影响;实践中常见有效上限近似为 `min(backlog, somaxconn)`(具体行为与内核版本相关)。 + +总结: + +| 队列 | 作用 | 状态 | 移出条件 | +| -------------------------- | ------------------ | ----------- | ----------------------- | +| 半连接队列(SYN Queue) | 保存未完成握手连接 | SYN_RCVD | 收到 ACK / 超时重传失败 | +| 全连接队列(Accept Queue) | 保存已完成握手连接 | ESTABLISHED | 被应用层 accept() 取出 | -1. **半连接队列**(也称 SYN Queue):当服务端收到客户端的 SYN 请求并回复 SYN+ACK 后,连接会处于 SYN_RECV 状态。此时,这个连接信息会被放入半连接队列。这个队列存储的是尚未完成三次握手的连接。 -2. **全连接队列**(也称 Accept Queue):当服务端收到客户端对 ACK 响应时,意味着三次握手成功完成,服务端会将该连接从半连接队列移动到全连接队列。如果未收到客户端的 ACK 响应,会进行重传,重传的等待时间通常是指数增长的。如果重传次数超过系统规定的最大重传次数,系统将从半连接队列中删除该连接信息。 +当全连接队列满时,`net.ipv4.tcp_abort_on_overflow` 会影响处理策略: -这两个队列的存在是为了处理并发连接请求,确保服务端能够有效地管理新的连接请求。 +- `0`(默认):通常不会立刻让连接快速失败,给应用留缓冲时间(可能表现为客户端重试/超时)。 +- `1`:直接对客户端回复 `RST`,让连接快速失败。 -如果全连接队列满了,新的已完成握手的连接可能会被丢弃,或者触发其他策略。这两个队列的大小都受系统参数控制,它们的容量限制是影响服务器处理高并发连接能力的重要因素,也是 SYN 泛洪攻击(SYN Flood)所针对的目标。 +当半连接队列满时,如果开启了 `tcp_syncookies`,服务端可能不会为该连接在半连接队列中分配常规条目,而是计算并返回一个 **SYN Cookie**。只有当收到合法的最终 `ACK` 时,才“重建”必要的连接信息。这是抵御 **SYN Flood** 的核心手段之一。 ### 为什么要三次握手? @@ -46,23 +83,70 @@ TCP 三次握手的核心目的是为了在客户端和服务器之间建立一 **1. 确认双方的收发能力,并同步初始序列号 (ISN)** -TCP 通信依赖序列号来保证数据的有序和可靠。三次握手是双方交换和确认彼此初始序列号(ISN)的过程,通过这个过程,双方也间接验证了各自的收发能力。 +```mermaid +sequenceDiagram + autonumber + participant C as 客户端 Client + participant S as 服务端 Server -- **第一次握手 (客户端 → 服务器)** :客户端发送 SYN 包。 - - 服务器:能确认客户端的发送能力正常,自己的接收能力正常。 - - 客户端:无法确认任何事。 -- **第二次握手 (服务器 → 客户端)** :服务器回复 SYN+ACK 包。 - - 客户端:能确认自己的发送和接收能力正常,服务器的接收和发送能力正常。 - - 服务端:能确认对方发送能力正常,自己接收能力正常 -- **第三次握手 (客户端 → 服务器)** :客户端发送 ACK 包。 - - 客户端:能确认双方发送和接收能力正常。 - - 服务端:能确认双方发送和接收能力正常。 + Note over C,S: 目标 同步双方 ISN 并确认双向可达 + + C->>S: SYN seq=ISN_C + Note right of S: 服务端确认 客户端到服务端方向可达 + Note right of S: 服务端状态 SYN_RCVD + + S->>C: SYN 加 ACK seq=ISN_S ack=ISN_C+1 + Note left of C: 客户端确认
1 服务端到客户端方向可达
2 服务端已收到客户端 SYN
3 获得 ISN_S + + C->>S: ACK seq=ISN_C+1 ack=ISN_S+1 + Note left of C: 客户端状态 ESTABLISHED + Note right of S: 服务端确认 客户端已收到 SYN 加 ACK
双方 ISN 同步完成 + Note right of S: 服务端状态 ESTABLISHED + + Note over C,S: 连接建立 可以开始传输数据 +``` + +TCP 依赖序列号(SEQ)与确认号(ACK)保证数据**有序、无重复、可重传**。三次握手通过交换并确认双方的 ISN,使两端对“从哪一个序号开始收发数据”达成一致,同时让握手过程形成闭环,避免仅凭单向信息就进入已建立状态。 经过这三次交互,双方都确认了彼此的收发功能完好,并完成了初始序列号的同步,为后续可靠的数据传输奠定了基础。 +三次握手能力确认速记: + +1. C→S:SYN → S 确认:C 能发,S 能收(C→S 通)。 +2. S→C:SYN+ACK → C 确认:S 能发,C 能收,且 S 已收到 C 的 SYN(对方 SEQ + 1)。 +3. C→S:ACK → S 确认:C 已收到 S 的 SYN+ACK,握手闭环,连接建立。 + **2. 防止已失效的连接请求被错误地建立** -这是“为什么不能是两次握手”的关键原因。 +```mermaid +sequenceDiagram + participant C as 客户端 (Client) + participant S as 服务端 (Server) + + Note over C,S: 场景:旧的 SYN 报文在网络中滞留 + + C->>S: 1. 发送 SYN (旧请求 - 滞留中) + Note over C: 客户端超时,放弃该请求 + + C->>S: 2. 发送 SYN (新请求) + S-->>C: 3. 建立连接并正常释放... + + rect rgb(255, 240, 240) + Note right of S: 此时,旧的 SYN 终于到达服务端 + S->>C: 4. 发送 SYN+ACK (针对旧请求) + + alt 如果是【两次握手】 + Note right of S: (假设服务端在回复 SYN+ACK 后即认为连接建立) + Note right of S: ❌ 错误建立连接 (Ghost Connection)
分配内存/资源,造成浪费 + else 如果是【三次握手】 + Note left of C: 客户端无该连接状态 / 非期望报文 + C->>S: 5. 发送 RST (重置报文) 或 直接丢弃 + + Note right of S: 【服务端结果】
收到 RST 立即清理;
或未收到 ACK 则重传并最终超时清理 + Note right of S: ✅ 避免错误建连,保护资源 + end + end +``` 设想一个场景:客户端发送的第一个连接请求(SYN1)因网络延迟而滞留,于是客户端重发了第二个请求(SYN2)并成功建立了连接,数据传输完毕后连接被释放。此时,延迟的 SYN1 才到达服务端。 @@ -73,7 +157,9 @@ TCP 通信依赖序列号来保证数据的有序和可靠。三次握手是双 ### 第 2 次握手传回了 ACK,为什么还要传回 SYN? -服务端传回发送端所发送的 ACK 是为了告诉客户端:“我接收到的信息确实就是你所发送的信号了”,这表明从客户端到服务端的通信是正常的。回传 SYN 则是为了建立并确认从服务端到客户端的通信。 +第二次握手里的 ACK 是为了确认“服务端确实收到了客户端的 SYN”(即确认 C→S 的请求到达)。而同时携带 SYN 是为了把服务端自己的 ISN 也同步给客户端,并要求客户端对其进行确认(即建立并确认 S→C 方向的建立过程)。只有双方的 ISN 都同步完成,后续的可靠传输(按序、重传、去重)才有共同起点。 + +简言之:ACK 用于“我收到了你的 SYN”,SYN 用于“我也要发起我的同步,请你确认”。 > SYN 同步序列编号(Synchronize Sequence Numbers) 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务端之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务端使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement)消息响应。这样在客户机和服务端之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务端之间传递。 @@ -94,26 +180,60 @@ TCP 通信依赖序列号来保证数据的有序和可靠。三次握手是双 3. **第三次挥手 (FIN)**:当服务端确认所有待发送的数据都已发送完毕后,它也会向客户端发送一个 **FIN** 报文段,表示自己也准备关闭连接。该报文段同样包含一个序列号 seq=y。发送后,服务端进入 **LAST-ACK** 状态,等待客户端的最终确认。 4. **第四次挥手**:客户端收到服务端的 FIN 报文段后,会回复一个最终的 **ACK** 确认报文段,确认号为 ack=y+1。发送后,客户端进入 **TIME-WAIT** 状态。服务端在收到这个 ACK 后,立即进入 **CLOSED** 状态,完成连接关闭。客户端则会在 **TIME-WAIT** 状态下等待 **2MSL**(Maximum Segment Lifetime,报文段最大生存时间)后,才最终进入 **CLOSED** 状态。 -**只要四次挥手没有结束,客户端和服务端就可以继续传输数据!** +四次挥手期间连接可能处于**半关闭(Half-Close)**:**先发送 FIN 的一方不再发送应用数据**,但**另一方仍可继续发送剩余数据**,直到它也发送 FIN 并完成后续 ACK。 ### 为什么要四次挥手? -TCP 是全双工通信,可以双向传输数据。任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了 TCP 连接。 +TCP 是全双工通信:两端的发送方向彼此独立。断开连接时,往往需要“我不发了”与“你也不发了”分别被对方确认,因此通常表现为四个报文段(FIN/ACK/FIN/ACK)。这也对应了现实世界的“双方分别确认挂断”的过程。 举个例子:A 和 B 打电话,通话即将结束后。 -1. **第一次挥手**:A 说“我没啥要说的了” -2. **第二次挥手**:B 回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话 -3. **第三次挥手**:于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了” -4. **第四次挥手**:A 回答“知道了”,这样通话才算结束。 +1. **第一次挥手**:A 说“我没啥要说的了”(A 发 FIN) +2. **第二次挥手**:B 回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话(B 回 ACK,但可能还有话要说) +3. **第三次挥手**:于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”(B 发 FIN) +4. **第四次挥手**:A 回答“知道了”,这样通话才算结束(A 回 ACK)。 ### 为什么不能把服务端发送的 ACK 和 FIN 合并起来,变成三次挥手? -因为服务端收到客户端断开连接的请求时,可能还有一些数据没有发完,这时先回复 ACK,表示接收到了断开连接的请求。等到数据发完之后再发 FIN,断开服务端到客户端的数据传送。 +```mermaid +sequenceDiagram + autonumber + participant C as 客户端 + participant K as 服务端内核 + participant A as 服务端应用 + + Note over C,K: 客户端发起关闭 + C->>K: FIN + Note right of K: 内核立即回复 ACK 用于确认对端 FIN + K-->>C: ACK + Note right of K: 服务端状态变为 CLOSE_WAIT + + Note over K,A: 应用处理阶段 + K->>A: 通知本端应用对端已关闭发送方向 例如 read 返回 0 + A->>A: 读取和处理剩余数据 + A->>A: 发送最后响应 + A->>K: 调用 close 或 shutdown + + Note right of K: 发送本端 FIN 并进入 LAST_ACK + K-->>C: FIN + Note left of C: 客户端回复 ACK 并进入 TIME_WAIT + C->>K: ACK + Note right of K: 服务端收到最终 ACK 后进入 CLOSED + + +``` + +关键原因是:**回复 ACK** 与 **发送 FIN** 的触发时机往往不同步。 + +- 当服务端收到客户端 FIN 时,内核协议栈会立即回 ACK,用于确认“我收到了你要关闭的请求”。此时服务端进入 CLOSE_WAIT,等待本端应用把剩余事情处理完。 +- 只有当服务端应用处理完毕并调用 `close()/shutdown()` 后,内核才会发送本端的 FIN。 +- 因此“内核自动回 ACK”和“应用决定发 FIN”在时间上是解耦的,通常无法合并。只有在服务端恰好也准备立即关闭时,才可能出现 FIN+ACK 合并在一个报文段中的情况。 ### 如果第二次挥手时服务端的 ACK 没有送达客户端,会怎样? -客户端在发送 FIN 后会启动一个重传计时器。如果在计时器超时之前没有收到服务端的 ACK,客户端会认为 FIN 报文丢失,并重新发送 FIN 报文。 +- **客户端状态**:客户端发送第一次 `FIN` 后进入 **FIN_WAIT_1** 并启动重传计时器。 +- **重传逻辑**:若在超时时间内未收到对端对该 `FIN` 的确认 `ACK`,客户端会重传 `FIN`。 +- **服务端处理**:服务端若收到重复 `FIN`,通常会再次发送 `ACK`。如果由于网络问题 ACK 一直到不了,客户端在达到一定重试/超时阈值后可能报错或放弃(具体由实现与参数如 `tcp_retries2` 等影响)。 ### 为什么第四次挥手客户端需要等待 2\*MSL(报文段最长寿命)时间后才进入 CLOSED 状态? @@ -124,11 +244,8 @@ TCP 是全双工通信,可以双向传输数据。任何一方都可以在数 ## 参考 - 《计算机网络(第 7 版)》 - - 《图解 HTTP》 - - TCP and UDP Tutorial:
数据库管理系统"] + + subgraph define["数据定义"] + DDL["📐 DDL
Data Definition Language"] + DDL_Items["• 创建/修改/删除对象
• 定义表结构
• 定义视图、索引
• 定义触发器
• 定义存储过程"] + end + + subgraph operate["数据操作"] + DML["⚡ DML
Data Manipulation Language"] + CRUD["CRUD 操作
• Create 创建
• Read 读取
• Update 更新
• Delete 删除"] + end + + subgraph control["数据控制"] + DCL["🔐 数据控制功能"] + Control_Items["• 并发控制
• 事务管理
• 完整性约束
• 权限控制
• 安全性限制"] + end + + subgraph maintain["数据库维护"] + Maintenance["🛠️ 维护功能"] + Maintain_Items["• 数据导入/导出
• 备份与恢复
• 性能监控与分析
• 系统日志管理"] + end + + DBMS --> DDL + DBMS --> DML + DBMS --> DCL + DBMS --> Maintenance + + DDL --> DDL_Items + DML --> CRUD + DCL --> Control_Items + Maintenance --> Maintain_Items + + style DBMS fill:#005D7B,stroke:#00838F,stroke-width:4px,color:#fff + + style DDL fill:#4CA497,stroke:#00838F,stroke-width:3px,color:#fff + style DDL_Items fill:#f0fffe,stroke:#4CA497,stroke-width:2px,color:#333 + + style DML fill:#E99151,stroke:#C44545,stroke-width:3px,color:#fff + style CRUD fill:#fff5e6,stroke:#E99151,stroke-width:2px,color:#333 + + style DCL fill:#00838F,stroke:#005D7B,stroke-width:3px,color:#fff + style Control_Items fill:#e6f7ff,stroke:#00838F,stroke-width:2px,color:#333 + + style Maintenance fill:#C44545,stroke:#8B0000,stroke-width:3px,color:#fff + style Maintain_Items fill:#ffe6e6,stroke:#C44545,stroke-width:2px,color:#333 + + style define fill:#E4C189,stroke:#E99151,stroke-width:2px,stroke-dasharray: 5 5,opacity:0.3 + style operate fill:#E4C189,stroke:#E99151,stroke-width:2px,stroke-dasharray: 5 5,opacity:0.3 + style control fill:#E4C189,stroke:#E99151,stroke-width:2px,stroke-dasharray: 5 5,opacity:0.3 + style maintain fill:#E4C189,stroke:#E99151,stroke-width:2px,stroke-dasharray: 5 5,opacity:0.3 +``` + DBMS 通常提供四大核心功能: 1. **数据定义:** 这是 DBMS 的基础。它提供了一套数据定义语言(Data Definition Language - DDL),让我们能够创建、修改和删除数据库中的各种对象。这不仅仅是定义表的结构(比如字段名、数据类型),还包括定义视图、索引、触发器、存储过程等。 @@ -63,7 +122,7 @@ DBMS 通常提供四大核心功能: ### NewSQL 数据库 -由于 NoSQL 不支持事务,很多对于数据安全要去非常高的系统(比如财务系统、订单系统、交易系统)就不太适合使用了。不过,这类系统往往有存储大量数据的需求。 +由于 NoSQL 不支持事务,很多对于数据安全要求非常高的系统(比如财务系统、订单系统、交易系统)就不太适合使用了。不过,这类系统往往有存储大量数据的需求。 这些系统往往只能通过购买性能更强大的计算机,或者通过数据库中间件来提高存储能力。不过,前者的金钱成本太高,后者的开发成本太高。 @@ -86,13 +145,60 @@ NewSQL 数据库代表:Google 的 F1/Spanner、阿里的 [OceanBase](https://o ## 什么是元组, 码, 候选码, 主码, 外码, 主属性, 非主属性? -- **元组**:元组(tuple)是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为行。 -- **码**:码就是能唯一标识实体的属性,对应表中的列。 -- **候选码**:若关系中的某一属性或属性组的值能唯一的标识一个元组,而其任何、子集都不能再标识,则称该属性组为候选码。例如:在学生实体中,“学号”是能唯一的区分学生实体的,同时又假设“姓名”、“班级”的属性组合足以区分学生实体,那么{学号}和{姓名,班级}都是候选码。 -- **主码** : 主码也叫主键。主码是从候选码中选出来的。 一个实体集中只能有一个主码,但可以有多个候选码。 -- **外码** : 外码也叫外键。如果一个关系中的一个属性是另外一个关系中的主码则这个属性为外码。 -- **主属性**:候选码中出现过的属性称为主属性。比如关系 工人(工号,身份证号,姓名,性别,部门). 显然工号和身份证号都能够唯一标示这个关系,所以都是候选码。工号、身份证号这两个属性就是主属性。如果主码是一个属性组,那么属性组中的属性都是主属性。 -- **非主属性:** 不包含在任何一个候选码中的属性称为非主属性。比如在关系——学生(学号,姓名,年龄,性别,班级)中,主码是“学号”,那么其他的“姓名”、“年龄”、“性别”、“班级”就都可以称为非主属性。 +在关系型数据库理论中,理解元组、码、候选码、主码、外码、主属性和非主属性这些核心概念,对于数据库设计和规范化至关重要。这些概念构成了关系数据库的理论基础。 + +```mermaid +graph TD + A[关系数据库概念] --> B[数据组织] + A --> C[码的类型] + A --> D[属性分类] + + B --> B1[元组
表中的行记录] + B --> B2[属性
表中的列] + + C --> C1[码
唯一标识] + C1 --> C2[候选码
最小唯一标识集] + C2 --> C3[主码
选定的候选码] + C1 --> C4[外码
引用其他表主码] + + D --> D1[主属性
候选码中的属性] + D --> D2[非主属性
不在候选码中的属性] + + C3 -.关联.-> C4 + C2 -.构成.-> D1 + + style A fill:#4CA497,stroke:#00838F,stroke-width:3px,color:#fff + style B fill:#00838F,stroke:#005D7B,stroke-width:2px,color:#fff + style C fill:#E99151,stroke:#005D7B,stroke-width:2px,color:#fff + style D fill:#005D7B,stroke:#00838F,stroke-width:2px,color:#fff + + style B1 fill:#E4C189,stroke:#00838F,stroke-width:1px + style B2 fill:#E4C189,stroke:#00838F,stroke-width:1px + + style C1 fill:#E4C189,stroke:#E99151,stroke-width:1px + style C2 fill:#E4C189,stroke:#E99151,stroke-width:1px + style C3 fill:#C44545,stroke:#005D7B,stroke-width:2px,color:#fff + style C4 fill:#E4C189,stroke:#E99151,stroke-width:1px + + style D1 fill:#E4C189,stroke:#005D7B,stroke-width:1px + style D2 fill:#E4C189,stroke:#005D7B,stroke-width:1px +``` + +### 基础概念 + +- **元组(Tuple):** 元组是关系数据库中的基本单位,在二维表中对应一行记录。每个元组包含了一个实体的完整信息。例如,在学生表中,每个学生的完整信息(学号、姓名、年龄等)构成一个元组。 +- **码(Key):** 码是能够唯一标识关系中元组的一个或多个属性的集合。码的主要作用是保证数据的唯一性和完整性。 + +### 码的分类 + +- **候选码(Candidate Key):** 候选码是能够唯一标识元组的最小属性集合,其任何真子集都不能唯一标识元组。一个关系可能有多个候选码。例如,在学生表中,如果"学号"能唯一标识学生,同时"身份证号"也能唯一标识学生,那么{学号}和{身份证号}都是候选码。 +- **主码/主键(Primary Key):** 主码是从候选码中选择的一个,用于唯一标识关系中的元组。每个关系只能有一个主码,但可以有多个候选码。选择主码时通常考虑:简单性、稳定性、无业务含义等因素。 +- **外码/外键(Foreign Key):** 外码是一个关系中的属性或属性组,它对应另一个关系的主码。外码用于建立和维护两个关系之间的联系,是实现参照完整性的重要机制。例如,在选课表中的"学号"如果引用学生表的主码"学号",则选课表中的"学号"就是外码。 + +### 属性分类 + +- **主属性(Prime Attribute):** 主属性是包含在任何一个候选码中的属性。如果一个关系有多个候选码,那么这些候选码中出现的所有属性都是主属性。例如,工人关系(工号,身份证号,姓名,性别,部门)中,如果{工号}和{身份证号}都是候选码,那么"工号"和"身份证号"都是主属性。 +- **非主属性(Non-prime Attribute):** 非主属性是不包含在任何候选码中的属性。这些属性完全依赖于候选码来确定其值。在上述工人关系中,"姓名"、"性别"、"部门"都是非主属性。 ## 什么是 ER 图? @@ -108,7 +214,37 @@ ER 图由下面 3 个要素组成: 下图是一个学生选课的 ER 图,每个学生可以选若干门课程,同一门课程也可以被若干人选择,所以它们之间的关系是多对多(M: N)。另外,还有其他两种实体之间的关系是:1 对 1(1:1)、1 对多(1: N)。 -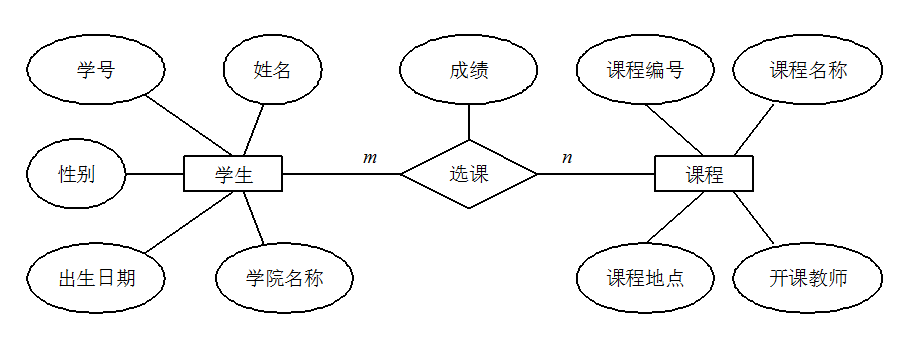 +```mermaid +erDiagram + STUDENT { + string student_id PK "学号" + string name "姓名" + string gender "性别" + date birth_date "出生日期" + string department "学院名称" + } + + COURSE { + string course_id PK "课程编号" + string course_name "课程名称" + string location "课程地点" + string instructor "开课教师" + float credits "成绩" + } + + ENROLLMENT { + string student_id FK "学号" + string course_id FK "课程编号" + float grade "成绩" + } + + STUDENT ||--o{ ENROLLMENT : "选课" + COURSE ||--o{ ENROLLMENT : "被选" + + style STUDENT fill:#4CA497,stroke:#00838F,stroke-width:2px + style COURSE fill:#005D7B,stroke:#00838F,stroke-width:2px + style ENROLLMENT fill:#E99151,stroke:#C44545,stroke-width:2px +``` ## 数据库范式了解吗? @@ -144,7 +280,7 @@ ER 图由下面 3 个要素组成: 从定义和属性上看,它们的区别是: - **主键 (Primary Key):** 它的核心作用是唯一标识表中的每一行数据。因此,主键列的值必须是唯一的 (Unique) 且不能为空 (Not Null)。一张表只能有一个主键。主键保证了实体完整性。 -- **外键 (Foreign Key):** 它的核心作用是建立并强制两张表之间的关联关系。一张表中的外键列,其值必须对应另一张表中某行的主键值(或者是一个 NULL 值)。因此,外键的值可以重复,也可以为空。一张表可以有多个外键,分别关联到不同的表。外键保证了引用完整性。 +- **外键 (Foreign Key):** 它的核心作用是建立并强制两张表之间的关联关系。一张表中的外键列,其值必须对应另一张表中某行的候选键值(通常是主键,也可以是唯一键),或者是一个 NULL 值。因此,外键的值可以重复,也可以为空。一张表可以有多个外键,分别关联到不同的表。外键保证了引用完整性。 用一个简单的电商例子来说明:假设我们有两张表:`users` (用户表) 和 `orders` (订单表)。 @@ -181,53 +317,239 @@ ER 图由下面 3 个要素组成: ## 什么是存储过程? -我们可以把存储过程看成是一些 SQL 语句的集合,中间加了点逻辑控制语句。存储过程在业务比较复杂的时候是非常实用的,比如很多时候我们完成一个操作可能需要写一大串 SQL 语句,这时候我们就可以写有一个存储过程,这样也方便了我们下一次的调用。存储过程一旦调试完成通过后就能稳定运行,另外,使用存储过程比单纯 SQL 语句执行要快,因为存储过程是预编译过的。 +```mermaid +graph LR + A[存储过程] --> B[定义特征] + A --> C[优势] + A --> D[劣势] + A --> E[应用现状] -存储过程在互联网公司应用不多,因为存储过程难以调试和扩展,而且没有移植性,还会消耗数据库资源。 + B --> B1[SQL语句集合] + B --> B2[包含逻辑控制] + B --> B3[预编译机制] -阿里巴巴 Java 开发手册里要求禁止使用存储过程。 + C --> C1[执行速度快] + C --> C2[运行稳定] + C --> C3[简化复杂操作] + + D --> D1[调试困难] + D --> D2[扩展性差] + D --> D3[无移植性] + D --> D4[占用数据库资源] + + E --> E1[传统企业
使用较多] + E --> E2[互联网公司
很少使用] + E --> E3[阿里规范
明确禁用] + + style A fill:#4CA497,stroke:#00838F,stroke-width:3px,color:#fff + style B fill:#00838F,stroke:#005D7B,stroke-width:2px,color:#fff + style C fill:#E99151,stroke:#C44545,stroke-width:2px,color:#fff + style D fill:#C44545,stroke:#005D7B,stroke-width:2px,color:#fff + style E fill:#005D7B,stroke:#00838F,stroke-width:2px,color:#fff + + style B1 fill:#E4C189,stroke:#00838F,stroke-width:1px + style B2 fill:#E4C189,stroke:#00838F,stroke-width:1px + style B3 fill:#E4C189,stroke:#00838F,stroke-width:1px + + style C1 fill:#E4C189,stroke:#E99151,stroke-width:1px + style C2 fill:#E4C189,stroke:#E99151,stroke-width:1px + style C3 fill:#E4C189,stroke:#E99151,stroke-width:1px + + style D1 fill:#E4C189,stroke:#C44545,stroke-width:1px + style D2 fill:#E4C189,stroke:#C44545,stroke-width:1px + style D3 fill:#E4C189,stroke:#C44545,stroke-width:1px + style D4 fill:#E4C189,stroke:#C44545,stroke-width:1px + + style E1 fill:#E4C189,stroke:#005D7B,stroke-width:1px + style E2 fill:#E4C189,stroke:#005D7B,stroke-width:1px + style E3 fill:#E4C189,stroke:#005D7B,stroke-width:1px +``` + +存储过程是数据库中预编译的SQL语句集合,它将多条SQL语句和程序逻辑控制语句(如IF-ELSE、WHILE循环等)封装在一起,形成一个可重复调用的数据库对象。 + +**存储过程的优势:** + +在传统企业级应用中,存储过程具有一定的实用价值。当业务逻辑复杂时,需要执行大量SQL语句才能完成一个业务操作,此时可以将这些语句封装成存储过程,简化调用过程。由于存储过程在创建时就已经编译并存储在数据库中,执行时无需重新编译,因此相比动态SQL语句具有更好的执行性能。同时,一旦存储过程调试完成,其运行相对稳定可靠。 + +**存储过程的局限性:** + +然而,在现代互联网架构中,存储过程的使用越来越少。主要原因包括:调试困难,缺乏成熟的调试工具;扩展性差,修改业务逻辑需要直接修改数据库对象;移植性差,不同数据库系统的存储过程语法差异较大;占用数据库资源,增加数据库服务器负担;版本管理困难,不便于进行代码版本控制。 + +**行业规范:** + +基于以上原因,许多互联网公司的开发规范中明确限制或禁止使用存储过程。例如,《阿里巴巴Java开发手册》中明确规定禁止使用存储过程,推荐将业务逻辑放在应用层实现,保持数据库的简单和高效。  -## drop、delete 与 truncate 区别? +## DROP、DELETE、TRUNCATE 有什么区别? -### 用法不同 +在数据库操作中,`DROP`、`DELETE` 和 `TRUNCATE` 是三个常用的数据删除命令,它们在功能、性能和使用场景上存在显著差异。 -- `drop`(丢弃数据): `drop table 表名` ,直接将表都删除掉,在删除表的时候使用。 -- `truncate` (清空数据) : `truncate table 表名` ,只删除表中的数据,再插入数据的时候自增长 id 又从 1 开始,在清空表中数据的时候使用。 -- `delete`(删除数据) : `delete from 表名 where 列名=值`,删除某一行的数据,如果不加 `where` 子句和`truncate table 表名`作用类似。 +**DROP命令:** -`truncate` 和不带 `where`子句的 `delete`、以及 `drop` 都会删除表内的数据,但是 **`truncate` 和 `delete` 只删除数据不删除表的结构(定义),执行 `drop` 语句,此表的结构也会删除,也就是执行`drop` 之后对应的表不复存在。** +- 语法:`DROP TABLE 表名` +- 作用:完全删除整个表,包括表结构、数据、索引、触发器、约束等所有相关对象 +- 使用场景:当表不再需要时使用 -### 属于不同的数据库语言 +**TRUNCATE命令:** -`truncate` 和 `drop` 属于 DDL(数据定义语言)语句,操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。而 `delete` 语句是 DML (数据库操作语言)语句,这个操作会放到 rollback segment 中,事务提交之后才生效。 +- 语法:`TRUNCATE TABLE 表名` +- 作用:清空表中所有数据,但保留表结构 +- 特点:自增长字段(AUTO_INCREMENT)会重置为初始值(通常为1) +- 使用场景:需要快速清空表数据但保留表结构时使用 -**DML 语句和 DDL 语句区别:** +**DELETE命令:** -- DML 是数据库操作语言(Data Manipulation Language)的缩写,是指对数据库中表记录的操作,主要包括表记录的插入、更新、删除和查询,是开发人员日常使用最频繁的操作。 -- DDL (Data Definition Language)是数据定义语言的缩写,简单来说,就是对数据库内部的对象进行创建、删除、修改的操作语言。它和 DML 语言的最大区别是 DML 只是对表内部数据的操作,而不涉及到表的定义、结构的修改,更不会涉及到其他对象。DDL 语句更多的被数据库管理员(DBA)所使用,一般的开发人员很少使用。 +- 语法:`DELETE FROM 表名 WHERE 条件` +- 作用:删除满足条件的数据行,不带WHERE子句时删除所有数据 +- 特点:自增长字段不会重置,继续从之前的值递增 +- 使用场景:需要有选择地删除部分数据时使用 + +`TRUNCATE` 和不带 `WHERE`子句的 `DELETE`、以及 `DROP` 都会删除表内的数据,但是 **`TRUNCATE` 和 `DELETE` 只删除数据不删除表的结构(定义),执行 `DROP` 语句,此表的结构也会删除,也就是执行`DROP` 之后对应的表不复存在。** + +### 对表结构的影响 + +- `DROP`:删除表结构和所有数据,表将不复存在 +- `TRUNCATE`:仅删除数据,保留表结构和定义 +- `DELETE`:仅删除数据,保留表结构和定义 + +### 触发器 + +- `DELETE` 操作会触发相关的DELETE触发器 +- `TRUNCATE` 和 `DROP` 不会触发DELETE触发器 -另外,由于`select`不会对表进行破坏,所以有的地方也会把`select`单独区分开叫做数据库查询语言 DQL(Data Query Language)。 +### 事务和回滚 -### 执行速度不同 +- `DROP` 和 `TRUNCATE` 属于DDL操作,执行后立即生效,不能回滚 +- `DELETE` 属于DML操作,可以回滚(在事务中) -一般来说:`drop` > `truncate` > `delete`(这个我没有实际测试过)。 +### 执行速度 -- `delete`命令执行的时候会产生数据库的`binlog`日志,而日志记录是需要消耗时间的,但是也有个好处方便数据回滚恢复。 -- `truncate`命令执行的时候不会产生数据库日志,因此比`delete`要快。除此之外,还会把表的自增值重置和索引恢复到初始大小等。 -- `drop`命令会把表占用的空间全部释放掉。 +一般来说:`DROP` > `TRUNCATE` > `DELETE`(这个我没有实际测试过)。 + +- `DELETE`命令执行的时候会产生数据库的`binlog`日志,而日志记录是需要消耗时间的,但是也有个好处方便数据回滚恢复。 +- `TRUNCATE`命令执行的时候不会产生数据库日志,因此比`DELETE`要快。除此之外,还会把表的自增值重置和索引恢复到初始大小等。 +- `DROP`命令会把表占用的空间全部释放掉。 Tips:你应该更多地关注在使用场景上,而不是执行效率。 +## DML 语句和 DDL 语句区别是? + +- DML 是数据库操作语言(Data Manipulation Language)的缩写,是指对数据库中表记录的操作,主要包括表记录的插入、更新、删除和查询,是开发人员日常使用最频繁的操作。 +- DDL (Data Definition Language)是数据定义语言的缩写,简单来说,就是对数据库内部的对象进行创建、删除、修改的操作语言。它和 DML 语言的最大区别是 DML 只是对表内部数据的操作,而不涉及到表的定义、结构的修改,更不会涉及到其他对象。DDL 语句更多的被数据库管理员(DBA)所使用,一般的开发人员很少使用。 + +另外,由于`SELECT`不会对表进行破坏,所以有的地方也会把`SELECT`单独区分开叫做数据库查询语言 DQL(Data Query Language)。 + ## 数据库设计通常分为哪几步? -1. **需求分析** : 分析用户的需求,包括数据、功能和性能需求。 -2. **概念结构设计** : 主要采用 E-R 模型进行设计,包括画 E-R 图。 -3. **逻辑结构设计** : 通过将 E-R 图转换成表,实现从 E-R 模型到关系模型的转换。 -4. **物理结构设计** : 主要是为所设计的数据库选择合适的存储结构和存取路径。 -5. **数据库实施** : 包括编程、测试和试运行 -6. **数据库的运行和维护** : 系统的运行与数据库的日常维护。 +```mermaid +graph TD + A[数据库设计流程] --> B[1.需求分析] + B --> C[2.概念结构设计] + C --> D[3.逻辑结构设计] + D --> E[4.物理结构设计] + E --> F[5.数据库实施] + F --> G[6.运行和维护] + + B --> B1[数据需求
功能需求
性能需求] + C --> C1[E-R建模
实体关系图] + D --> D1[关系模型
表结构设计
规范化] + E --> E1[存储结构
索引设计
分区策略] + F --> F1[编程开发
测试部署
数据迁移] + G --> G1[性能监控
备份恢复
优化调整] + + G -.反馈.-> B + + style A fill:#4CA497,stroke:#00838F,stroke-width:3px,color:#fff + style B fill:#00838F,stroke:#005D7B,stroke-width:2px,color:#fff + style C fill:#E99151,stroke:#005D7B,stroke-width:2px,color:#fff + style D fill:#005D7B,stroke:#00838F,stroke-width:2px,color:#fff + style E fill:#C44545,stroke:#005D7B,stroke-width:2px,color:#fff + style F fill:#E99151,stroke:#005D7B,stroke-width:2px,color:#fff + style G fill:#00838F,stroke:#005D7B,stroke-width:2px,color:#fff + + style B1 fill:#E4C189,stroke:#00838F,stroke-width:1px + style C1 fill:#E4C189,stroke:#E99151,stroke-width:1px + style D1 fill:#E4C189,stroke:#005D7B,stroke-width:1px + style E1 fill:#E4C189,stroke:#C44545,stroke-width:1px + style F1 fill:#E4C189,stroke:#E99151,stroke-width:1px + style G1 fill:#E4C189,stroke:#00838F,stroke-width:1px +``` + +### 1. 需求分析阶段 + +**目标:** 深入了解和分析用户需求,明确系统边界 +**主要工作:** + +- 收集和分析数据需求:确定需要存储哪些数据,数据量大小,数据更新频率 +- 明确功能需求:系统需要支持哪些业务操作,各操作的优先级 +- 定义性能需求:响应时间要求,并发用户数,数据吞吐量 +- 确定安全需求:数据访问权限,加密要求,审计要求 + **产出物:** 需求规格说明书、数据字典初稿 + +### 2. 概念结构设计阶段 + +**目标:** 将需求转化为信息世界的概念模型 +**主要工作:** + +- 识别实体:确定系统中的主要对象 +- 定义属性:明确每个实体的特征 +- 建立联系:确定实体之间的关系(一对一、一对多、多对多) +- 绘制E-R图(实体-关系图) + **产出物:** E-R图、概念数据模型文档 + +### 3. 逻辑结构设计阶段 + +**目标:** 将概念模型转换为特定DBMS支持的逻辑模型 +**主要工作:** + +- E-R图向关系模型转换:将实体转换为表,属性转换为字段 +- 规范化处理:通过范式化消除数据冗余和更新异常(通常达到3NF) +- 定义完整性约束:主键、外键、唯一性约束、检查约束 +- 优化模型:根据性能需求进行适当的反规范化 + **产出物:** 逻辑数据模型、表结构设计文档 + +### 4. 物理结构设计阶段 + +**目标:** 确定数据的物理存储方案和访问方法 +**主要工作:** + +- 选择存储引擎:如MySQL的InnoDB、MyISAM等 +- 设计索引策略:确定需要建立的索引类型和字段 +- 分区设计:对大表进行分区以提高性能 +- 确定存储参数:表空间大小、数据文件位置、缓冲区配置 +- 制定备份策略:全量备份、增量备份的频率和方式 + **产出物:** 物理设计文档、索引设计方案 + +### 5. 数据库实施阶段 + +**目标:** 将设计转化为实际运行的数据库系统 +**主要工作:** + +- 创建数据库和表结构:编写和执行DDL语句 +- 开发存储过程和触发器(如需要) +- 编写应用程序接口 +- 导入初始数据 +- 系统集成测试:功能测试、性能测试、压力测试 +- 用户培训和文档编写 + **产出物:** 数据库脚本、测试报告、用户手册 + +### 6. 运行和维护阶段 + +**目标:** 确保数据库系统稳定高效运行 +**主要工作:** + +- 日常监控:性能监控、空间监控、错误日志分析 +- 性能优化:查询优化、索引调整、参数调优 +- 数据备份和恢复:定期备份、恢复演练 +- 安全管理:权限管理、安全补丁更新、审计 +- 容量规划:预测数据增长,提前扩容 +- 变更管理:需求变更的评估和实施 + **产出物:** 运维报告、优化方案、变更记录 + +### 设计原则 + +在整个设计过程中应遵循:数据独立性原则、完整性原则、安全性原则、可扩展性原则和标准化原则。 ## 参考 diff --git a/docs/database/character-set.md b/docs/database/character-set.md index 9a0969a2770..2e65c74a5b6 100644 --- a/docs/database/character-set.md +++ b/docs/database/character-set.md @@ -1,15 +1,13 @@ --- title: 字符集详解 +description: 详解字符集与字符编码原理,深入分析ASCII、GB2312、GBK、UTF-8、UTF-16等常见编码,解释MySQL中utf8与utf8mb4的区别以及emoji存储问题的解决方案。 category: 数据库 tag: - 数据库基础 head: - - meta - name: keywords - content: 字符集,编码,UTF-8,UTF-16,GBK,utf8mb4,emoji,存储与传输 - - - meta - - name: description - content: 从编码与字符集原理入手,解释 utf8 与 utf8mb4 差异与 emoji 存储问题,指导数据库与应用的正确配置。 + content: 字符集,字符编码,UTF-8,UTF-16,GBK,GB2312,utf8mb4,ASCII,Unicode,MySQL字符集,emoji存储 --- MySQL 字符编码集中有两套 UTF-8 编码实现:**`utf8`** 和 **`utf8mb4`**。 diff --git a/docs/database/elasticsearch/elasticsearch-questions-01.md b/docs/database/elasticsearch/elasticsearch-questions-01.md index 4b1599bea3a..2db51f16d7a 100644 --- a/docs/database/elasticsearch/elasticsearch-questions-01.md +++ b/docs/database/elasticsearch/elasticsearch-questions-01.md @@ -1,5 +1,6 @@ --- title: Elasticsearch常见面试题总结(付费) +description: Elasticsearch常见面试题总结,涵盖ES核心概念、倒排索引原理、分片与副本机制、查询DSL、聚合分析、集群调优等高频面试知识点。 category: 数据库 tag: - NoSQL @@ -7,10 +8,7 @@ tag: head: - - meta - name: keywords - content: Elasticsearch 面试,索引,分片,倒排,查询,聚合,调优 - - - meta - - name: description - content: 收录 Elasticsearch 高频面试题与实践要点,围绕索引/分片/倒排与聚合查询,形成系统复习清单。 + content: Elasticsearch面试题,ES索引,倒排索引,分片副本,全文搜索,聚合查询,Lucene,ELK --- **Elasticsearch** 相关的面试题为我的[知识星球](../../about-the-author/zhishixingqiu-two-years.md)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](../../zhuanlan/java-mian-shi-zhi-bei.md)中。 diff --git a/docs/database/mongodb/mongodb-questions-01.md b/docs/database/mongodb/mongodb-questions-01.md index 2799ff984f2..f60be69b0fb 100644 --- a/docs/database/mongodb/mongodb-questions-01.md +++ b/docs/database/mongodb/mongodb-questions-01.md @@ -1,5 +1,6 @@ --- title: MongoDB常见面试题总结(上) +description: MongoDB常见面试题总结上篇,详解MongoDB基础概念、存储结构、数据类型、副本集高可用、分片集群水平扩展等核心知识点,助力后端面试准备。 category: 数据库 tag: - NoSQL @@ -7,10 +8,7 @@ tag: head: - - meta - name: keywords - content: MongoDB 面试,文档存储,无模式,副本集,分片,索引,一致性 - - - meta - - name: description - content: 汇总 MongoDB 基础与架构高频题,涵盖文档模型、索引、副本集与分片,强调高可用与一致性实践。 + content: MongoDB面试题,文档数据库,BSON,副本集,分片集群,MongoDB索引,WiredTiger,聚合管道 --- > 少部分内容参考了 MongoDB 官方文档的描述,在此说明一下。 diff --git a/docs/database/mongodb/mongodb-questions-02.md b/docs/database/mongodb/mongodb-questions-02.md index f652801fc39..4a7af767d16 100644 --- a/docs/database/mongodb/mongodb-questions-02.md +++ b/docs/database/mongodb/mongodb-questions-02.md @@ -1,5 +1,6 @@ --- title: MongoDB常见面试题总结(下) +description: MongoDB常见面试题总结下篇,深入讲解MongoDB各类索引(单字段、复合、多键、文本、地理位置、TTL)的原理、使用场景和查询优化技巧。 category: 数据库 tag: - NoSQL @@ -7,10 +8,7 @@ tag: head: - - meta - name: keywords - content: MongoDB 索引,复合索引,多键索引,文本索引,地理索引,查询优化 - - - meta - - name: description - content: 讲解 MongoDB 常见索引类型与适用场景,结合查询优化与写入开销权衡,提升检索性能与稳定性。 + content: MongoDB索引,复合索引,多键索引,文本索引,地理位置索引,TTL索引,MongoDB查询优化,索引设计 --- ## MongoDB 索引 diff --git a/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md b/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md index ec06b4d60e7..b62c108458b 100644 --- a/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md +++ b/docs/database/mysql/a-thousand-lines-of-mysql-study-notes.md @@ -1,15 +1,13 @@ --- title: 一千行 MySQL 学习笔记 +description: 一千行MySQL学习笔记精华总结,涵盖数据库操作、表管理、SQL语法、索引、视图、存储过程、触发器等核心知识点,适合快速查阅和复习。 category: 数据库 tag: - MySQL head: - - meta - name: keywords - content: MySQL 笔记,调优,索引,事务,工具,经验总结,实践 - - - meta - - name: description - content: 整理 MySQL 学习与实践的千行笔记,凝练调优思路、索引与事务要点及工具使用,便于快速查阅与复盘。 + content: MySQL学习笔记,MySQL命令大全,SQL语法,数据库操作,表操作,索引,视图,存储过程,触发器 --- > 原文地址:
(my_stream) + participant CG as Consumer Group
(group_a) + participant C1 as Consumer-1 + participant C2 as Consumer-2 + + %% 生产消息 + P->>R: XADD my_stream * field value + R-->>P: 返回 ID = 1001 + + %% 消费新消息 + C1->>R: XREADGROUP GROUP group_a consumer-1
STREAMS my_stream > + R-->>C1: 返回消息 1001 + + Note over CG: 1️⃣ last_delivered_id 推进到 1001 + Note over CG: 2️⃣ 1001 进入 PEL (Pending Entries List) + + %% 正常消费 + alt 正常处理完成 + C1->>R: XACK my_stream group_a 1001 + R-->>C1: OK + Note over CG: 1001 从 PEL 移除 + else 消费者崩溃 + Note over C1: 未 ACK,连接断开 + Note over CG: 1001 仍在 PEL 中
idle time 持续增长 + + C2->>R: XPENDING my_stream group_a + R-->>C2: 返回 1001 + idle time + + C2->>R: XCLAIM my_stream group_a consumer-2 60000 1001 + R-->>C2: 返回 1001 + + Note over CG: 1001 转移到 consumer-2 + + C2->>R: XACK my_stream group_a 1001 + R-->>C2: OK + end + +``` + +总的来说,`Stream` 已经可以满足一个消息队列的基本要求了。不过,`Stream` 在实际使用中需要注意以下几点: + +1. **持久化限制**:Redis 5.0 的 Stream 依赖 RDB/AOF 异步持久化,在故障恢复时可能丢失最近未持久化的消息(取决于 `appendfsync` 配置)。AOF 的 `everysec` 模式下通常最多丢失 1 秒数据。 +2. **消息堆积受限**:Redis Stream 的数据存储在内存中,受服务器内存容量限制。相比 Kafka 基于磁盘的存储,Redis Stream 不适合海量堆积场景。 +3. **消费组管理**:Consumer Group 的状态信息(如 `last_delivered_id`)需要定期维护,长时间未处理的 Pending 消息会占用内存。 + +下面这张表格是 Redis Stream 和常见 MQ 的对比: + +| 维度 | Redis Stream | RabbitMQ | Kafka | 内存队列 | +| :------------- | :------------------------- | :------------------------------- | :---------------------------------- | :----------------------- | +| **吞吐量** | 高(十万级 QPS) | 中(万级 QPS) | **极高(百万级,靠分区水平扩展)** | 极高(受限于 CPU/内存) | +| **延迟** | **极低(亚毫秒级)** | **低(微秒/毫秒级,实时性强)** | 中(毫秒级,受批处理影响) | 极低(纳秒/微秒级) | +| **持久化** | 支持(RDB/AOF 异步) | 支持(磁盘) | **强支持(原生磁盘顺序写)** | 无 | +| **消息堆积** | 一般(受内存限制) | 中(堆积多时性能下降明显) | **极强(TB 级磁盘存储,性能稳定)** | 差(易 OOM) | +| **消息回溯** | 支持(按 ID/时间) | **不支持(传统队列模式下)** | **强支持(按 Offset/时间)** | 不支持 | +| **可靠性** | 中(AOF 丢数据风险) | **高(Confirm/确认机制成熟)** | **极高(多副本 + 强一致性配置)** | 低 | +| **运维复杂度** | 低(运维 Redis 即可) | 中(Erlang 环境,集群管理) | 高(依赖 ZK 或 KRaft) | 极低 | +| **适用场景** | 轻量级、低延迟、已有 Redis | **复杂路由、高可靠性、金融业务** | **大数据、日志聚合、高吞吐流处理** | 进程内解耦、极致性能要求 | + +### 总结 + +**回到最初的问题:Redis 到底能不能做 MQ?** + +- **如果业务简单、量小、追求极致性能**,且能容忍极小概率的数据丢失,使用 **Redis Stream** 是最优解,因为它省去了部署维护 MQ 的成本,可以复用现有的 Redis 组件(大部分需要用到 MQ 的项目,通常都会需要 Redis)。 +- **如果是金融级业务、海量数据、需要严格保证不丢消息**,必须选择 **Kafka、RabbitMQ** 等更成熟的 MQ。 + +更多 Redis 高频知识点和面试题总结,可以阅读笔者写的这几篇文章: + +- [Redis 常见面试题总结(上)](https://javaguide.cn/database/redis/redis-questions-01.html "Redis 常见面试题总结(上)")(Redis 基础、应用、数据类型、持久化机制、线程模型等) +- [Redis 常见面试题总结(下)](https://javaguide.cn/database/redis/redis-questions-02.html "Redis 常见面试题总结(下)")(Redis 事务、性能优化、生产问题、集群、使用规范等) +- [如何基于Redis实现延时任务](https://javaguide.cn/database/redis/redis-delayed-task.html "如何基于Redis实现延时任务") +- [Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html "Redis 5 种基本数据类型详解") +- [Redis 3 种特殊数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-02.html "Redis 3 种特殊数据类型详解") +- [Redis为什么用跳表实现有序集合](https://javaguide.cn/database/redis/redis-skiplist.html "Redis为什么用跳表实现有序集合") +- [Redis 持久化机制详解](https://javaguide.cn/database/redis/redis-persistence.html "Redis 持久化机制详解") +- [Redis 内存碎片详解](https://javaguide.cn/database/redis/redis-memory-fragmentation.html "Redis 内存碎片详解") +- [Redis 常见阻塞原因总结](https://javaguide.cn/database/redis/redis-common-blocking-problems-summary.html "Redis 常见阻塞原因总结") + +我的 [《SpringAI 智能面试平台+RAG 知识库》](https://javaguide.cn/zhuanlan/interview-guide.html)项目就是用的 Redis Stream 作为消息队列。在我的项目的场景下,它几乎是最合适的选择,完全够用了。 + + + + diff --git a/docs/database/sql/sql-questions-01.md b/docs/database/sql/sql-questions-01.md index fe1a7c2f28b..b61d0f07c1e 100644 --- a/docs/database/sql/sql-questions-01.md +++ b/docs/database/sql/sql-questions-01.md @@ -1,5 +1,6 @@ --- title: SQL常见面试题总结(1) +description: SQL常见面试题总结第一篇,涵盖SELECT检索数据、WHERE条件过滤、ORDER BY排序、DISTINCT去重、LIMIT分页等基础查询操作及牛客真题解析。 category: 数据库 tag: - 数据库基础 @@ -7,10 +8,7 @@ tag: head: - - meta - name: keywords - content: SQL 面试题,查询,分组,排序,连接,子查询,聚合 - - - meta - - name: description - content: 收录 SQL 基础高频题与解法,涵盖查询/分组/排序/连接等典型场景,强调可读性与性能的兼顾。 + content: SQL面试题,SELECT查询,WHERE条件,ORDER BY排序,DISTINCT去重,LIMIT分页,SQL基础 --- > 题目来源于:[牛客题霸 - SQL 必知必会](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=298) diff --git a/docs/database/sql/sql-questions-02.md b/docs/database/sql/sql-questions-02.md index 11d1a1068df..b0ce5fa2499 100644 --- a/docs/database/sql/sql-questions-02.md +++ b/docs/database/sql/sql-questions-02.md @@ -1,5 +1,6 @@ --- title: SQL常见面试题总结(2) +description: SQL常见面试题总结第二篇,详解INSERT、UPDATE、DELETE等DML数据操作语句,包括批量插入、从其他表导入、带更新的插入等实战技巧。 category: 数据库 tag: - 数据库基础 @@ -7,10 +8,7 @@ tag: head: - - meta - name: keywords - content: SQL 面试题,增删改,批量插入,导入,替换插入,约束 - - - meta - - name: description - content: 聚焦增删改等基础操作的题目解析,总结批量插入/导入与替换插入等技巧与注意事项。 + content: SQL面试题,INSERT插入,UPDATE更新,DELETE删除,批量插入,REPLACE INTO,数据操作 --- > 题目来源于:[牛客题霸 - SQL 进阶挑战](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240) diff --git a/docs/database/sql/sql-questions-03.md b/docs/database/sql/sql-questions-03.md index 6979bb69146..a445fef8280 100644 --- a/docs/database/sql/sql-questions-03.md +++ b/docs/database/sql/sql-questions-03.md @@ -1,5 +1,6 @@ --- title: SQL常见面试题总结(3) +description: SQL常见面试题总结第三篇,深入讲解聚合函数COUNT、SUM、AVG、MAX、MIN的使用,以及GROUP BY分组、HAVING过滤、截断平均值计算等进阶技巧。 category: 数据库 tag: - 数据库基础 @@ -7,10 +8,7 @@ tag: head: - - meta - name: keywords - content: SQL 面试题,聚合函数,截断平均,窗口,难题解析,性能 - - - meta - - name: description - content: 围绕聚合函数与复杂统计题型,讲解截断平均等解法与实现要点,兼顾性能与正确性。 + content: SQL面试题,聚合函数,COUNT,SUM,AVG,MAX,MIN,GROUP BY,HAVING,截断平均值 --- > 题目来源于:[牛客题霸 - SQL 进阶挑战](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240) diff --git a/docs/database/sql/sql-questions-04.md b/docs/database/sql/sql-questions-04.md index b9b2ee04543..8dd989cd9b0 100644 --- a/docs/database/sql/sql-questions-04.md +++ b/docs/database/sql/sql-questions-04.md @@ -1,5 +1,6 @@ --- title: SQL常见面试题总结(4) +description: SQL常见面试题总结第四篇,详解MySQL 8.0窗口函数ROW_NUMBER、RANK、DENSE_RANK、NTILE、LAG、LEAD等的用法和应用场景。 category: 数据库 tag: - 数据库基础 @@ -7,10 +8,7 @@ tag: head: - - meta - name: keywords - content: SQL 面试题,窗口函数,ROW_NUMBER,排名,分组,MySQL 8 - - - meta - - name: description - content: 总结 MySQL 8 引入的窗口函数用法,包含排序与分组统计场景的高频题与实现技巧。 + content: SQL面试题,窗口函数,ROW_NUMBER,RANK,DENSE_RANK,NTILE,LAG,LEAD,MySQL 8.0 --- > 题目来源于:[牛客题霸 - SQL 进阶挑战](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240) diff --git a/docs/database/sql/sql-questions-05.md b/docs/database/sql/sql-questions-05.md index e11c14979c5..39171bfe08f 100644 --- a/docs/database/sql/sql-questions-05.md +++ b/docs/database/sql/sql-questions-05.md @@ -1,5 +1,6 @@ --- title: SQL常见面试题总结(5) +description: SQL常见面试题总结第五篇,详解NULL空值处理技巧,包括IFNULL、COALESCE函数,以及使用CASE WHEN进行条件统计和完成率计算。 category: 数据库 tag: - 数据库基础 @@ -7,10 +8,7 @@ tag: head: - - meta - name: keywords - content: SQL 面试题,空值处理,统计,未完成率,CASE,聚合 - - - meta - - name: description - content: 解析空值处理与统计类题目,结合 CASE 与聚合函数给出稳健实现,避免常见陷阱。 + content: SQL面试题,NULL空值处理,IFNULL,COALESCE,CASE WHEN,条件统计,完成率计算 --- > 题目来源于:[牛客题霸 - SQL 进阶挑战](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240) diff --git a/docs/database/sql/sql-syntax-summary.md b/docs/database/sql/sql-syntax-summary.md index ef4be0bd88d..679c1b59255 100644 --- a/docs/database/sql/sql-syntax-summary.md +++ b/docs/database/sql/sql-syntax-summary.md @@ -1,5 +1,6 @@ --- title: SQL语法基础知识总结 +description: SQL语法基础知识总结,系统讲解DDL数据定义、DML数据操作、DQL数据查询、DCL数据控制语言,涵盖表操作、约束、索引、事务、连接查询等核心知识点。 category: 数据库 tag: - 数据库基础 @@ -7,10 +8,7 @@ tag: head: - - meta - name: keywords - content: SQL 语法,DDL,DML,DQL,约束,事务,索引,范式 - - - meta - - name: description - content: 系统整理 SQL 基础语法与术语,覆盖 DDL/DML/DQL、约束与事务索引,形成入门到实践的知识路径。 + content: SQL语法,DDL,DML,DQL,DCL,CREATE,SELECT,INSERT,UPDATE,DELETE,JOIN连接,子查询 --- > 本文整理完善自下面这两份资料: diff --git a/docs/distributed-system/api-gateway.md b/docs/distributed-system/api-gateway.md index e9b9f27e6dd..0a4486db0a0 100644 --- a/docs/distributed-system/api-gateway.md +++ b/docs/distributed-system/api-gateway.md @@ -1,21 +1,47 @@ --- title: API网关基础知识总结 category: 分布式 +description: API网关基础知识详解,涵盖网关核心功能(路由转发、身份认证、限流熔断、负载均衡)、工作原理及Zuul、Spring Cloud Gateway、Nginx等常见网关选型对比。 +tag: + - API网关 +head: + - - meta + - name: keywords + content: API网关,网关,微服务网关,Spring Cloud Gateway,Zuul,限流熔断,负载均衡,网关面试题 --- ## 什么是网关? -微服务背景下,一个系统被拆分为多个服务,但是像安全认证,流量控制,日志,监控等功能是每个服务都需要的,没有网关的话,我们就需要在每个服务中单独实现,这使得我们做了很多重复的事情并且没有一个全局的视图来统一管理这些功能。 +API 网关(API Gateway)是位于客户端与后端服务之间的**统一入口**,所有客户端请求先经过网关,再由网关路由到具体的目标服务。 + +### 核心价值 + +在微服务架构下,一个系统被拆分为多个服务。像**安全认证、流量控制、日志、监控**等功能是每个服务都需要的。如果没有网关,我们需要在每个服务中单独实现这些功能,导致: + +- **代码重复**:相同逻辑在多个服务中冗余实现 +- **管理分散**:缺乏统一的配置和监控视图 +- **维护成本高**:功能变更需要修改所有服务 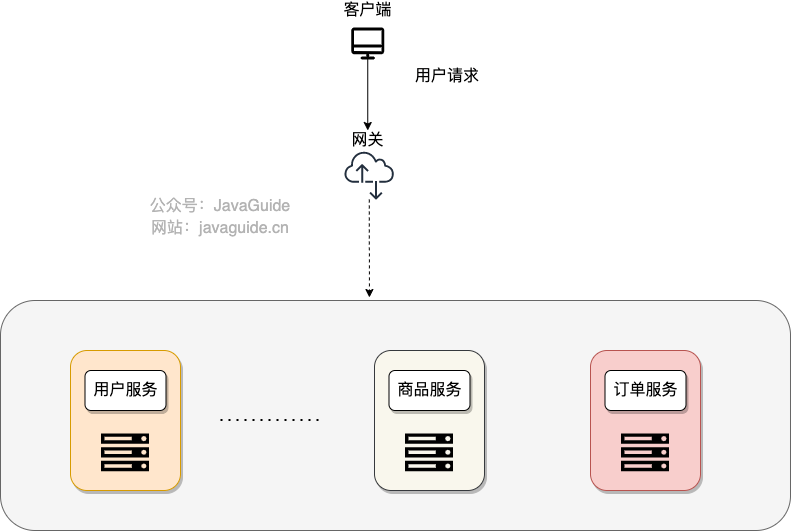 -一般情况下,网关可以为我们提供请求转发、安全认证(身份/权限认证)、流量控制、负载均衡、降级熔断、日志、监控、参数校验、协议转换等功能。 +### 核心职责 + +网关的功能虽然繁多,但核心可以概括为两件事: + +| 职责 | 说明 | 典型功能 | +| ------------ | ----------------------------------- | -------------------------------------- | +| **请求转发** | 将客户端请求路由到正确的目标服务 | 动态路由、负载均衡、协议转换 | +| **请求过滤** | 在请求到达后端服务前/后进行拦截处理 | 身份认证、权限校验、限流熔断、日志记录 | -上面介绍了这么多功能,实际上,网关主要做了两件事情:**请求转发** + **请求过滤**。 +网关可以提供请求转发、安全认证(身份/权限认证)、流量控制、负载均衡、降级熔断、日志、监控、参数校验、协议转换等功能。 -由于引入网关之后,会多一步网络转发,因此性能会有一点影响(几乎可以忽略不计,尤其是内网访问的情况下)。 另外,我们需要保障网关服务的高可用,避免单点风险。 +**网关在微服务架构中的位置**:所有客户端请求先到达网关,网关负责统一的认证鉴权、流量控制、路由分发,后端服务专注于业务逻辑处理。 -如下图所示,网关服务外层通过 Nginx(其他负载均衡设备/软件也行) 进⾏负载转发以达到⾼可⽤。Nginx 在部署的时候,尽量也要考虑高可用,避免单点风险。 +### 高可用部署 + +引入网关后会增加一次网络转发(性能损耗在内网环境下通常可忽略),但同时也引入了新的单点风险。因此,网关服务本身必须保障高可用: + +如下图所示,网关服务外层通过 Nginx(或其他负载均衡设备/软件)进行负载转发以达到高可用。Nginx 在部署时也应考虑高可用,避免单点风险。  @@ -75,20 +101,40 @@ Zuul 主要通过过滤器(类似于 AOP)来过滤请求,从而实现网  +> **重要提示**:Spring Cloud 官方已在 **Hoxton 版之后将 Zuul 1.x 移除**。尽管 Netflix 开源了 Zuul 2.x,但 Zuul 2.x 并未被集成到 Spring Cloud 主流版本中。对于 Spring Cloud 技术栈的新项目,**严禁选用 Zuul 1.x**,推荐直接使用 Spring Cloud Gateway。 + - GitHub 地址:
Partition Tolerance]:::cap + P -->|网络分区发生| Choice{分区时权衡 C 与 A}:::caution + Choice -->|倾向 C| CP[一致性优先
牺牲可用性]:::cp + Choice -->|倾向 A| AP[可用性优先
牺牲一致性]:::ap + + CP --> ZK[ ZooKeeper
etcd ]:::cp + CP --> UseCP[应用场景:
分布式锁、配置管理]:::cp + + AP --> Eureka[ Eureka
Cassandra ]:::ap + AP --> UseAP[应用场景:
服务注册中心、社交动态]:::ap + + CA[仅单机系统
可实现 CA]:::danger -.->|有分区时不可行| Choice + + linkStyle default stroke-width:2px,stroke:#333333,opacity:0.8 +``` + +这里需要引入 **PACELC 理论**(CAP 的扩展)来更全面地解释: + +Daniel J. Abadi 提出的 PACELC 理论指出:**如果存在分区(P),必须在可用性(A)和一致性(C)之间选择;否则(E,Else),必须在延迟(L)和一致性(C)之间选择。** + +```mermaid +flowchart TB + %% 核心语义配色 + classDef question fill:#95A5A6,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef choice fill:#E99151,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef consistency fill:#3498DB,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef availability fill:#27AE60,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef latency fill:#9B59B6,color:#FFFFFF,stroke:none,rx:10,ry:10 + + Q{是否存在分区 P?}:::question + + Q -->|是 Partition| PAC[权衡 A 与 C]:::choice + Q -->|否 Else| ELC[权衡 L 与 C]:::choice + + PAC --> PA[选择可用性 A
Cassandra AP]:::availability + PAC --> PC[选择一致性 C
ZooKeeper CP]:::consistency + + ELC --> LC[选择低延迟 L
MySQL 异步复制]:::latency + ELC --> EC[选择强一致 C
MySQL 半同步复制]:::consistency + + linkStyle default stroke-width:2px,stroke:#333333,opacity:0.8 +``` + +实际意义:即使无网络分区,分布式系统仍需在低延迟(异步复制)和强一致(同步复制)之间权衡。例如: + +- **Cassandra**:可通过调整读写一致性级别(ONE/QUORUM/ALL)在延迟与一致性间权衡 +- **MySQL 主从**:可选择异步复制(低延迟)或半同步复制(强一致) + +比如 ZooKeeper、HBase 就是 CP 架构,Cassandra、Eureka 就是 AP 架构,Nacos 不仅支持 CP 架构也支持 AP 架构。 + +**选择 CP 还是 AP 的关键在于当前的业务场景,没有定论**:比如对于需要确保强一致性的场景如分布式锁、配置管理会选择 CP;对于高可用优先的场景如微服务注册中心会选择 AP。 + +**另外,需要补充说明的一点**:在无分区时,可以同时做到线性一致与「会响应」的 CAP-可用性;但工程上通常还要在延迟与一致性之间权衡(这便是 PACELC 理论中 ELC 部分讨论的内容)。 -大部分人解释这一定律时,常常简单的表述为:“一致性、可用性、分区容忍性三者你只能同时达到其中两个,不可能同时达到”。实际上这是一个非常具有误导性质的说法,而且在 CAP 理论诞生 12 年之后,CAP 之父也在 2012 年重写了之前的论文。 +### CAP 理论的适用范围 -> **当发生网络分区的时候,如果我们要继续服务,那么强一致性和可用性只能 2 选 1。也就是说当网络分区之后 P 是前提,决定了 P 之后才有 C 和 A 的选择。也就是说分区容错性(Partition tolerance)我们是必须要实现的。** +**重要结论**:CAP 理论主要讨论单个数据对象在副本复制场景下的一致性与可用性权衡。 + +| 更贴近 CAP 讨论模型 | 需要拆分到分片/对象/操作级别分析 | +| ------------------- | ------------------------------------ | +| Redis 主从/哨兵集群 | 业务系统(无状态服务) | +| MySQL 主从/多主集群 | Redis-Cluster(每个 shard 仍有副本) | +| MongoDB 副本集 | MongoDB-Cluster(分片 + 副本并存) | +| ZooKeeper、etcd | 分库分表(跨分片事务需额外协调) | +| Kafka、RocketMQ | 大多数微服务应用\* | + +**说明**: + +- **CAP 讨论模型**:单个读写寄存器(single register)的副本复制语义 +- **复杂系统**:需要拆解到「每个对象/分区/操作」的一致性语义讨论 +- **分片 + 副本**:分片系统每个 shard 通常仍有副本复制,一致性与可用性权衡仍在 + +> **业务系统与 CAP 的深度关联**: +> +> 业务系统本身虽不涉及副本同步,但**深受底层组件 CAP 属性的影响**。忽视这一点会导致系统在遭遇网络分区时发生级联雪崩(Cascading Failure)。 +> +> **受 CAP 属性影响的业务场景**: +> +> | 业务场景 | 底层组件 | CP 组件的影响 | AP 组件的影响 | +> | -------- | ---------------------------- | -------------------------- | ------------------------------ | +> | RPC 路由 | 注册中心(如 Nacos CP 模式) | 注册期间不可用,请求被拒绝 | 可能路由到已下线实例,需要重试 | +> | 分布式锁 | Redis(AP)/ ZooKeeper(CP) | 性能较低但可靠 | 性能高但可能锁失效 | +> | 限流熔断 | Redis 计数器 | 可能读到旧计数,限流失效 | 同左 | +> | 缓存更新 | Redis 主从 | 主从切换时可能丢数据 | 同左 | +> | 消息消费 | Kafka | 消费进度同步慢,重复消费 | 同左 | +> +> **实践建议**:业务开发者虽然不需要「实践」CAP 理论,但**必须理解 CAP 理论**,以便: > -> 简而言之就是:CAP 理论中分区容错性 P 是一定要满足的,在此基础上,只能满足可用性 A 或者一致性 C。 +> - 为不同业务场景选择合适的组件(CP 或 AP) +> - 理解所选组件在网络分区时的行为特征 +> - 设计符合业务需求的容错机制(重试、熔断、降级) + +很多开发者认为自己在「实践 CAP 理论」,实际上只是站在已有组件上做选择(用 CP 还是 AP),而非真正实践该理论。真正需要实践 CAP 的是研发 Redis、MySQL 这类分布式存储组件的工程师。 + +### 在业务中应用 CAP 思想 + +除研发分布式存储组件外,业务开发中更多是**选择**合适的架构,而非实践 CAP 理论本身: + +| 场景 | 偏向 CP 的选择 | 偏向 AP 的选择 | 业务权衡 | +| -------------- | ---------------------------- | ------------------------ | ------------------------ | +| 数据库主从复制 | 同步复制(强一致) | 异步复制(高性能) | 数据一致性 vs 响应速度 | +| 分布式锁实现 | ZooKeeper(强一致) | Redis(高性能) | 锁的可靠性 vs 获取速度 | +| 服务注册中心 | ZooKeeper、Consul(CP 模式) | Eureka、Nacos(AP 模式) | 注册准确性 vs 发现可用性 | +| 限流计数器 | Redis(强一致命令) | Redis(允许过期) | 限流精度 vs 性能 | + +**选型原则**: + +- **关注性能**:倾向选择允许异步复制的组件,写入主节点即可返回成功,响应快;但存在数据丢失/读取到旧数据的风险,需配合重试机制 +- **关注数据安全**:倾向选择要求多数派确认的组件,写入需等待 quorum 节点确认,响应慢;但能降低数据丢失风险 + +**注意**:数据丢失与否更取决于持久化、复制确认策略、故障模型,不能简单地用「CP/AP 标签」来判断。 -因此,**分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。** 比如 ZooKeeper、HBase 就是 CP 架构,Cassandra、Eureka 就是 AP 架构,Nacos 不仅支持 CP 架构也支持 AP 架构。 +**级联雪崩案例**: -**为啥不可能选择 CA 架构呢?** 举个例子:若系统出现“分区”,系统中的某个节点在进行写操作。为了保证 C, 必须要禁止其他节点的读写操作,这就和 A 发生冲突了。如果为了保证 A,其他节点的读写操作正常的话,那就和 C 发生冲突了。 +一个典型的忽视 CAP 导致的级联雪崩场景: -**选择 CP 还是 AP 的关键在于当前的业务场景,没有定论,比如对于需要确保强一致性的场景如银行一般会选择保证 CP 。** +```mermaid +flowchart TB + %% 核心语义配色 + classDef start fill:#95A5A6,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef process fill:#3498DB,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef warning fill:#F39C12,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef danger fill:#C44545,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef solution fill:#27AE60,color:#FFFFFF,stroke:none,rx:10,ry:10 -另外,需要补充说明的一点是:**如果网络分区正常的话(系统在绝大部分时候所处的状态),也就说不需要保证 P 的时候,C 和 A 能够同时保证。** + Start[网络分区发生]:::start --> P1[Redis 集群主从分离
AP 架构数据不一致]:::process + P1 --> P2[限流计数器读到旧值
以为未限流]:::warning + P2 --> P3[大量请求同时打到后端]:::warning + P3 --> P4[服务线程池耗尽]:::danger + P4 --> P5[RPC 调用超时堆积]:::danger + P5 --> P6[整个调用链路雪崩]:::danger + + P2 -.->|理解 CAP 属性| S1[选择合适组件]:::solution + P3 -.->|多层防护| S2[本地缓存 + 熔断降级]:::solution + P4 -.->|超时重试| S3[合理设置超时时间]:::solution + P5 -.->|隔离机制| S4[不同业务隔离实例]:::solution + + linkStyle default stroke-width:2px,stroke:#333333,opacity:0.8 +``` + +**防护措施**: + +1. **理解底层组件的 CAP 属性**:知道在网络分区时组件的行为 +2. **多层防护**:不只依赖单一组件,结合本地缓存、熔断、降级 +3. **超时与重试**:合理设置超时时间,避免无限等待 +4. **隔离机制**:不同业务使用不同的底层组件实例,避免故障扩散 ### CAP 实际应用案例 我这里以注册中心来探讨一下 CAP 的实际应用。考虑到很多小伙伴不知道注册中心是干嘛的,这里简单以 Dubbo 为例说一说。 -下图是 Dubbo 的架构图。**注册中心 Registry 在其中扮演了什么角色呢?提供了什么服务呢?** +下图是 Dubbo 的架构图。**注册中心 Registry 在其中扮演什么角色呢?提供了什么服务呢?** 注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小。 @@ -67,25 +235,77 @@ CAP 理论的提出者布鲁尔在提出 CAP 猜想的时候,并没有详细 常见的可以作为注册中心的组件有:ZooKeeper、Eureka、Nacos...。 -1. **ZooKeeper 保证的是 CP。** 任何时刻对 ZooKeeper 的读请求都能得到一致性的结果,但是, ZooKeeper 不保证每次请求的可用性比如在 Leader 选举过程中或者半数以上的机器不可用的时候服务就是不可用的。 -2. **Eureka 保证的则是 AP。** Eureka 在设计的时候就是优先保证 A (可用性)。在 Eureka 中不存在什么 Leader 节点,每个节点都是一样的、平等的。因此 Eureka 不会像 ZooKeeper 那样出现选举过程中或者半数以上的机器不可用的时候服务就是不可用的情况。 Eureka 保证即使大部分节点挂掉也不会影响正常提供服务,只要有一个节点是可用的就行了。只不过这个节点上的数据可能并不是最新的。 -3. **Nacos 不仅支持 CP 也支持 AP。** +#### ZooKeeper 3.8.x(CP 架构) -**🐛 修正(参见:[issue#1906](https://github.com/Snailclimb/JavaGuide/issues/1906))**: +ZooKeeper 倾向 **CP 架构**。ZooKeeper 3.x 通过 ZAB 协议提供 **Linearizable Writes(线性化写入)**,但读取行为需区分: -ZooKeeper 通过可线性化(Linearizable)写入、全局 FIFO 顺序访问等机制来保障数据一致性。多节点部署的情况下, ZooKeeper 集群处于 Quorum 模式。Quorum 模式下的 ZooKeeper 集群, 是一组 ZooKeeper 服务器节点组成的集合,其中大多数节点必须同意任何变更才能被视为有效。 +- **Sync 读取**:强制与 Leader 同步,保证线性一致性(Linearizability)。 +- **普通读取**:默认提供 **顺序一致性(Sequential Consistency)**,保证全局更新操作的顺序,同一会话内客户端视图绝不会发生回退,但可能读到稍旧数据(存在读取滞后)。 -由于 Quorum 模式下的读请求不会触发各个 ZooKeeper 节点之间的数据同步,因此在某些情况下还是可能会存在读取到旧数据的情况,导致不同的客户端视图上看到的结果不同,这可能是由于网络延迟、丢包、重传等原因造成的。ZooKeeper 为了解决这个问题,提供了 Watcher 机制和版本号机制来帮助客户端检测数据的变化和版本号的变更,以保证数据的一致性。 +> **重要区别**:顺序一致性 ≠ 最终一致性。ZooKeeper 的普通读取保证所有客户端看到相同的**更新顺序**(全局 zxid 顺序),只是存在读取滞后;而最终一致性不保证全局顺序,仅保证最终收敛。ZK 的默认读更像是「stale-but-ordered」的读(顺序/会话保证很强),而不是 Dynamo 系那种 eventual consistency 语境。 -### 总结 +在 Leader 选举期间或 Follower 节点数不足 Quorum(N/2+1)时,ZooKeeper 会拒绝服务以维持一致性,表现为不可用(牺牲 A)。 + +在多节点部署下,集群采用 Quorum 模式:多数派节点(n/2+1)必须同意变更才有效。 + +ZooKeeper 提供 Watcher 机制(异步通知变更)和版本号机制(zxid 校验新鲜度)以缓解读取滞后问题。 + +失败路径与状态机表现: + +| 故障场景 | 系统状态 | 客户端表现 | +| ------------------------------- | ------------------------------- | ------------------------------------------------------------ | +| Quorum 失效(半数以上节点故障) | **LOOKING** 状态,Leader 选举中 | 写入请求拒绝,读取请求可能返回旧数据或超时 | +| Follower 与 Leader 分区 | Follower 进入 **ELECTION** 状态 | 该 Follower 无法参与投票,但可响应读取(滞后数据) | +| Leader 与多数派分区 | Leader 自动降级,集群重新选举 | 原Leader的写入丢失,需客户端重试(检测到 zxid 回退) | +| Watcher 丢失 | 网络抖动或 GC 压力导致 | 客户端需重试(指数退避 + Jitter),监控 `Watches` 队列防背压 | + +#### Eureka(AP 架构) + +Eureka 采用 AP 架构:节点对等,通过 Peer 复制/同步(定期全量拉取 + 增量更新)保持数据一致,无 Leader 选举。**注意**:Spring Cloud 生态中历史上更常见 1.x 依赖形态;Netflix/eureka 的 2.x 仍在维护并持续发布。 + +失败路径与状态机表现: + +| 故障场景 | 系统状态 | 客户端表现 | 自我保护机制 | +| ---------------------------- | ---------------------------------------- | ----------------------------------------------------------------------------------------------- | --------------------------------------------------------------------- | +| 网络分区(脑裂) | 分区两侧**独立运行**,均可读写 | 客户端可能读到旧注册信息(不一致窗口 = 心跳间隔 30s + gossip 传播延迟,10 节点拓扑中 P99 <60s) | 当续约阈值 < 85% 时触发**自我保护**,暂停实例剔除,避免"误杀"健康实例 | +| 半数节点故障 | 剩余节点继续服务,但数据可能分叉 | 读操作正常,写入可能仅存于少数派节点 | 自我保护触发,待节点恢复后通过 gossip 自动合并 | +| 节点短暂重启 | 从 Peer 批量拉取注册表(Registry Fetch) | 服务发现短暂不可用(< 1min),缓存起作用 | 正常模式,自动恢复 | +| 注册风暴(大量实例同时注册) | 写队列堆积,可能导致请求丢弃 | 部分注册请求超时,需客户端重试 | 可配置限流与背压(如 Ribbon 重试策略) | + +**自我保护机制详细说明**: -在进行分布式系统设计和开发时,我们不应该仅仅局限在 CAP 问题上,还要关注系统的扩展性、可用性等等 +Eureka Server 通过以下逻辑判断是否进入自我保护: -在系统发生“分区”的情况下,CAP 理论只能满足 CP 或者 AP。要注意的是,这里的前提是系统发生了“分区” +``` +每分钟期望续约数 E = 当前实例数 N × (60 / 心跳间隔秒数) +阈值 T = E × 0.85 +若最近 1 分钟实际续约数 R < T,则进入自我保护:暂停剔除(eviction) +(E/T 会按固定周期根据 N 更新,常见周期约 15 分钟) +``` -如果系统没有发生“分区”的话,节点间的网络连接通信正常的话,也就不存在 P 了。这个时候,我们就可以同时保证 C 和 A 了。 +默认心跳间隔为 30 秒时,每分钟期望续约数 = 实例数 × 2。 -总结:**如果系统发生“分区”,我们要考虑选择 CP 还是 AP。如果系统没有发生“分区”的话,我们要思考如何保证 CA 。** +当 `实际续约率 < 85%` 时: + +1. 进入 **SELF PRESERVATION** 模式 +2. 停止剔除过期实例(EvictionTask 暂停) +3. 日志输出:`ENTER SELF PRESERVATION MODE` + +**设计权衡**:宁可保留「僵尸」实例,也不误杀健康实例——因为在微服务场景下,短暂的服务降级好过大规模服务不可用。客户端通常配置重试与熔断来处理不可用实例。 + +#### 总结 + +选择 CP 或 AP 取决于场景:ZooKeeper 适合强一致需求,如配置管理;Eureka 适合高可用注册,如微服务发现。 + +Nacos 不仅支持 CP 也支持 AP。 + +### 总结 + +CAP 理论指导我们:在分布式系统可能出现网络分区(P)的前提下,我们必须在强一致性(C)和高可用性(A)之间做出权衡。 + +- **CP 架构**:牺牲可用性,保证强一致性。适用于对数据一致性要求极高的场景(如金融交易、分布式锁)。 +- **AP 架构**:牺牲一致性,保证高可用性。适用于对系统可用性要求较高,能容忍短暂数据不一致的场景(如社交动态、商品搜索)。 +- **PACELC**:在无分区(E)时,需在延迟(L)和一致性(C)之间权衡。 ### 推荐阅读 @@ -95,27 +315,76 @@ ZooKeeper 通过可线性化(Linearizable)写入、全局 FIFO 顺序访问 ## BASE 理论 -[BASE 理论](https://dl.acm.org/doi/10.1145/1394127.1394128)起源于 2008 年, 由 eBay 的架构师 Dan Pritchett 在 ACM 上发表。 +[BASE 理论](https://dl.acm.org/doi/10.1145/1394127.1394128)起源于 2008 年,由 eBay 的架构师 Dan Pritchett 在 ACM 上发表,论文标题为《Base: An ACID Alternative》。 + +> **关键洞察**:从论文标题可以看出,**BASE 首先是 ACID 的替代品**。但同时需要注意,BASE 与 CAP 理论也存在密切关系——**最终一致性正是 CAP 中 AP 架构在工程实践中达到系统收敛的指导原则**。 ### 简介 -**BASE** 是 **Basically Available(基本可用)**、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论是对 CAP 中一致性 C 和可用性 A 权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。 +**BASE** 是 **Basically Available(基本可用)**、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论来源于对大规模互联网系统分布式实践的总结。 + +### BASE 与 ACID 的关系 + +要理解 BASE 理论,首先需要回顾 ACID 理论中的 **一致性(Consistency)**: + +**ACID 的一致性定义**:事务执行前后,数据库只能从一个一致状态转变为另一个一致状态。 + +以转账为例:小竹向熊猫转账 1000W。 + +- **初始态**:小竹 1001W,熊猫 888W,合计 1889W +- **结果态**:小竹 1W,熊猫 1888W,合计 1889W -### BASE 理论的核心思想 +无论事务成功或失败,整体数据的变化必须一致——类似于能量守恒定律。 -即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。 +**分布式场景的挑战**: -> 也就是牺牲数据的一致性来满足系统的高可用性,系统中一部分数据不可用或者不一致时,仍需要保持系统整体“主要可用”。 +在分布式系统中,商品服务和订单服务分离部署,[扣减库存、创建订单]需要通过网络调用,这中间必然存在时间差: -**BASE 理论本质上是对 CAP 的延伸和补充,更具体地说,是对 CAP 中 AP 方案的一个补充。** +``` +时刻 T1:库存 8888 → 8887(扣减成功) +时刻 T2:网络调用订单服务... +时刻 T3:订单创建成功 +``` -**为什么这样说呢?** +在 T1~T3 期间,系统处于 **中间态**:库存已减,订单未创建。跨服务后无法用单库 ACID 事务保证整体原子提交与隔离,系统会客观存在中间态;BASE 接受中间态并通过补偿/重试让状态最终收敛。 -CAP 理论这节我们也说过了: +**BASE 理论的解决方案**: -> 如果系统没有发生“分区”的话,节点间的网络连接通信正常的话,也就不存在 P 了。这个时候,我们就可以同时保证 C 和 A 了。因此,**如果系统发生“分区”,我们要考虑选择 CP 还是 AP。如果系统没有发生“分区”的话,我们要思考如何保证 CA 。** +BASE 理论承认并允许这种中间态的存在: -因此,AP 方案只是在系统发生分区的时候放弃一致性,而不是永远放弃一致性。在分区故障恢复后,系统应该达到最终一致性。这一点其实就是 BASE 理论延伸的地方。 +- **Soft-state(软状态)**:允许系统存在中间态,且该中间态不影响系统整体可用性 +- **Eventually consistent(最终一致性)**:中间态最终会演变成终态(要么成功,要么回滚) + +下面通过一个对比图来直观理解 ACID 和 BASE 在事务处理上的不同模式: + +```mermaid +flowchart LR + %% 核心语义配色 + classDef acid fill:#3498DB,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef base fill:#27AE60,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef state fill:#95A5A6,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef success fill:#4CA497,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef fail fill:#C44545,color:#FFFFFF,stroke:none,rx:10,ry:10 + + subgraph ACID [ACID 模式:无中间态] + direction TB + A1[初始态
小竹1001W + 熊猫888W]:::state + A1 -->|事务执行| A2[终态:成功
小竹1W + 熊猫1888W]:::success + A1 -->|事务失败| A3[终态:失败
小竹1001W + 熊猫888W]:::fail + end + + subgraph BASE [BASE 模式:允许中间态] + direction TB + B1[初始态
库存8888]:::state + B1 -->|扣减成功| B2[中间态
库存8887 订单未创建]:::base + B2 -->|订单创建成功| B3[终态:成功
库存8887 订单已创建]:::success + B2 -->|订单创建失败| B4[终态:失败
库存回滚到8888]:::fail + end + + linkStyle default stroke-width:2px,stroke:#333333,opacity:0.8 +``` + +因此,**BASE 理论是 ACID 在分布式场景中的替代品**,而非 CAP 理论的补充。 ### BASE 理论三要素 @@ -127,35 +396,133 @@ CAP 理论这节我们也说过了: **什么叫允许损失部分可用性呢?** -- **响应时间上的损失**: 正常情况下,处理用户请求需要 0.5s 返回结果,但是由于系统出现故障,处理用户请求的时间变为 3 s。 +- **响应时间上的损失**:正常情况下,处理用户请求需要 0.5s 返回结果,但是由于系统出现故障,处理用户请求的时间变为 3s。 - **系统功能上的损失**:正常情况下,用户可以使用系统的全部功能,但是由于系统访问量突然剧增,系统的部分非核心功能无法使用。 #### 软状态 -软状态指允许系统中的数据存在中间状态(**CAP 理论中的数据不一致**),并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。 +软状态(Soft State)是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性。 + +> **与 ACID 的区别**:ACID 理论要求事务执行后立即进入终态(成功或失败),不允许中间态;而 BASE 理论承认中间态是分布式系统的客观存在,只要中间态最终会演变成终态即可。 + +举例说明: + +- **ACID 模式**:银行转账事务中,扣款和入账必须同时成功或同时失败,不允许「扣款成功但入账未完成」的中间态 +- **BASE 模式**:电商下单事务中,允许「库存已减但订单未创建」的中间态存在,只要最终会达到一致(要么订单创建成功,要么库存回滚) #### 最终一致性 -最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。 +最终一致性(Eventual Consistency)强调:**若系统在一段时间内无新的更新操作,则所有副本最终收敛到相同值。** -> 分布式一致性的 3 种级别: -> -> 1. **强一致性**:系统写入了什么,读出来的就是什么。 -> 2. **弱一致性**:不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。 -> 3. **最终一致性**:弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。 -> -> **业界比较推崇是最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。** +需要注意的是,「最终一致性」这个词在两个不同语境下有不同含义: + +| 语境 | 含义 | 典型场景 | +| ------------------------------ | ------------------------ | -------------------------- | +| **副本式存储(CAP 语境)** | 数据副本最终同步一致 | Cassandra 数据复制 | +| **事务状态(BASE/ACID 语境)** | 事务中间态最终演变成终态 | 分布式事务(如 TCC、Saga) | + +**副本式存储的最终一致性**: + +「一段时间」是未界定的——可能是毫秒级(局域网同步)或分钟级(跨地域复制)。生产环境中需通过 **Read Repair(读修复)**、**Anti-Entropy(反熵/后台同步)** 或 **Quorum 写入** 主动加速收敛。 -那实现最终一致性的具体方式是什么呢? [《分布式协议与算法实战》](http://gk.link/a/10rZM) 中是这样介绍: +**事务状态的最终一致性**: -> - **读时修复** : 在读取数据时,检测数据的不一致,进行修复。比如 Cassandra 的 Read Repair 实现,具体来说,在向 Cassandra 系统查询数据的时候,如果检测到不同节点的副本数据不一致,系统就自动修复数据。 -> - **写时修复** : 在写入数据,检测数据的不一致时,进行修复。比如 Cassandra 的 Hinted Handoff 实现。具体来说,Cassandra 集群的节点之间远程写数据的时候,如果写失败 就将数据缓存下来,然后定时重传,修复数据的不一致性。 -> - **异步修复** : 这个是最常用的方式,通过定时对账检测副本数据的一致性,并修复。 +以分布式事务为例:[扣减库存、创建订单、扣减余额] -比较推荐 **写时修复**,这种方式对性能消耗比较低。 +- 时刻 T1:库存已减(中间态) +- 时刻 T2:订单已创建(中间态) +- 时刻 T3:余额已扣(终态:事务成功) + +或在失败场景: + +- 时刻 T1:库存已减(中间态) +- 时刻 T2:订单创建失败(触发回滚) +- 时刻 T3:库存回滚(终态:事务失败) + +系统会保证在一定时间内达到数据一致的状态,而不需要实时保证系统数据的强一致性。 + +分布式一致性的 3 种级别: + +1. **强一致性**:系统写入了什么,读出来的就是什么。 +2. **弱一致性**:不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。 +3. **最终一致性**:弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。 + +**业界比较推崇最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。** + +那实现最终一致性的具体方式是什么呢? + +- **读时修复(Read Repair)**:在读取数据时,检测数据的不一致,进行修复。适合读多写少场景。 +- **写时修复(Hinted Handoff)**:在写入数据时,如果目标节点不可用,将数据缓存下来,待节点恢复后重传。**写时修复** 优化了写入延迟,但增加了读取时的不一致风险(数据可能还在缓存队列中未落盘到目标节点)。 +- **异步修复(Anti-Entropy/反熵)**:通过后台比对副本数据差异并修复。工程实现中关键挑战是**高效检测数据差异**——暴力逐条比对(O(n))在大规模数据集下不可行,生产系统采用**默克尔树(Merkle Tree)**实现低开销差异定位。 + +**选择建议**: + +- **写时修复**:适合写多读少,优化写入性能,但牺牲一致性窗口。 +- **读时修复**:适合读多写少,保证读取数据的准确性。 +- **Anti-Entropy**:后台兜底保障,适合数据规模大但对最终一致性要求高的场景。 + +### 为什么很多人把 BASE 当作 CAP 的补充? + +这是一个**部分正确但表述不够精确**的说法。更准确的理解是: + +1. **BASE 首先是 ACID 的替代品**:从论文标题[《Base: An ACID Alternative》](https://spawn-queue.acm.org/doi/10.1145/1394127.1394128)可以看出,BASE 理论的初衷是解决分布式事务场景下 ACID 过于严格的问题。 + +2. **BASE 与 CAP 的 AP 架构存在内在联系**: + + - 选择 AP 架构意味着放弃强一致性(C) + - 放弃强一致性后,系统如何达到收敛?答案是**最终一致性** + - 因此,BASE 理论(特别是最终一致性)是 AP 架构在工程实践中**必须采用**的指导原则 + +3. **误解产生的根源**:很多人把"BASE 与 AP 相关"误解为"BASE 是 CAP 的补充"。实际上: + - **BASE 不是对 CAP 理论的补充或修正** + - **BASE 是 AP 架构选择的工程实践指南**——当你选择了 AP,BASE 告诉你如何在工程实践中让系统最终达到一致 + +**正确的理解**: + +```mermaid +flowchart TB + %% 核心语义配色 + classDef cap fill:#E99151,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef base fill:#27AE60,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef acid fill:#3498DB,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef relation fill:#9B59B6,color:#FFFFFF,stroke:none,rx:10,ry:10 + + CAP[CAP 理论
分布式存储系统设计约束]:::cap + ACID[ACID 理论
数据库事务完整性]:::acid + BASE[BASE 理论
ACID 的分布式替代品]:::base + + CAP -->|AP 架构放弃强一致性| BASE + ACID -->|分布式场景放宽| BASE + + CAP -->|约束:不能同时满足 C+A| R1[实践意义]:::relation + BASE -->|实现:如何达到最终一致| R1 + + R1 --> Result[CAP 告诉我们限制
BASE 告诉我们做法]:::relation + + linkStyle default stroke-width:2px,stroke:#333333,opacity:0.8 +``` + +| 维度 | CAP 理论 | BASE 理论 | +| ---------- | ------------------------ | ------------------------------------------------ | +| 关注领域 | 分布式存储系统(带副本) | 所有分布式系统 | +| 一致性含义 | 数据一致性(副本同步) | 状态一致性(事务终态) | +| 可用性含义 | 节点故障时系统可用 | 部分节点故障时部分功能可用 | +| 核心关系 | - | ① ACID 的分布式替代品
② AP 架构的工程实践指南 | + +> **实践意义**:CAP 告诉我们在 AP 架构下无法保证强一致性,BASE 告诉我们在 AP 架构下如何通过最终一致性让系统达到收敛——两者是**约束与实现**的关系,而非补充关系。 + +如果说 CAP 是分布式存储系统的设计约束(告诉我们不能做什么),那么 BASE 就是分布式系统(尤其是业务系统)的实践指导(告诉我们如何做)——它告诉我们:**绝大多数应用场景不需要强一致性,通过接受中间态并最终达到一致性,是更务实的选择。** ### 总结 -**ACID 是数据库事务完整性的理论,CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸。** +**ACID 是数据库事务完整性的理论,CAP 是分布式存储系统的设计理论,BASE 是 ACID 在分布式场景中的替代品,同时也是 AP 架构的工程实践指南。** + +> **关键对应关系**: +> +> - **CAP 的一致性** = 数据一致性(副本节点间的数据同步) +> - **BASE 的一致性** = 状态一致性(事务终态的一致)= ACID 的一致性 +> - **CAP 的可用性** = 主从集群的可用性(节点故障时系统仍可用) +> - **BASE 的可用性** = 分片式集群的可用性(部分节点故障只影响部分用户) +> - **CAP 与 BASE 的关系**:选择 AP 架构后,BASE 理论指导如何在工程实践中通过最终一致性达到系统收敛 diff --git a/docs/distributed-system/protocol/consistent-hashing.md b/docs/distributed-system/protocol/consistent-hashing.md index c4de5bac2d2..5f219da0138 100644 --- a/docs/distributed-system/protocol/consistent-hashing.md +++ b/docs/distributed-system/protocol/consistent-hashing.md @@ -1,9 +1,14 @@ --- title: 一致性哈希算法详解 category: 分布式 +description: 一致性哈希算法原理详解,讲解哈希环、虚拟节点机制、数据倾斜问题解决方案,以及在分布式缓存(Redis/Memcached)、负载均衡、分库分表中的应用场景。 tag: - 分布式协议&算法 - 哈希算法 +head: + - - meta + - name: keywords + content: 一致性哈希,哈希环,虚拟节点,分布式缓存,负载均衡,数据倾斜,哈希算法,分布式算法,分库分表 --- 开始之前,先说两个常见的场景: @@ -110,7 +115,7 @@ hash(服务器ip)% 2^32 如下图所示,Node1、Node2、Node3、Node4 这 4 个节点都对应 3 个虚拟节点(下图只是为了演示,实际情况节点分布不会这么有规律)。 - + 对于上图来说,每个节点最终负责的数据情况如下: diff --git a/docs/distributed-system/protocol/gossip-protocl.md b/docs/distributed-system/protocol/gossip-protocl.md deleted file mode 100644 index 5590401a9b6..00000000000 --- a/docs/distributed-system/protocol/gossip-protocl.md +++ /dev/null @@ -1,145 +0,0 @@ ---- -title: Gossip 协议详解 -category: 分布式 -tag: - - 分布式协议&算法 - - 共识算法 ---- - -## 背景 - -在分布式系统中,不同的节点进行数据/信息共享是一个基本的需求。 - -一种比较简单粗暴的方法就是 **集中式发散消息**,简单来说就是一个主节点同时共享最新信息给其他所有节点,比较适合中心化系统。这种方法的缺陷也很明显,节点多的时候不光同步消息的效率低,还太依赖与中心节点,存在单点风险问题。 - -于是,**分散式发散消息** 的 **Gossip 协议** 就诞生了。 - -## Gossip 协议介绍 - -Gossip 直译过来就是闲话、流言蜚语的意思。流言蜚语有什么特点呢?容易被传播且传播速度还快,你传我我传他,然后大家都知道了。 - - - -**Gossip 协议** 也叫 Epidemic 协议(流行病协议)或者 Epidemic propagation 算法(疫情传播算法),别名很多。不过,这些名字的特点都具有 **随机传播特性** (联想一下病毒传播、癌细胞扩散等生活中常见的情景),这也正是 Gossip 协议最主要的特点。 - -Gossip 协议最早是在 ACM 上的一篇 1987 年发表的论文 [《Epidemic Algorithms for Replicated Database Maintenance》](https://dl.acm.org/doi/10.1145/41840.41841)中被提出的。根据论文标题,我们大概就能知道 Gossip 协议当时提出的主要应用是在分布式数据库系统中各个副本节点同步数据。 - -正如 Gossip 协议其名一样,这是一种随机且带有传染性的方式将信息传播到整个网络中,并在一定时间内,使得系统内的所有节点数据一致。 - -在 Gossip 协议下,没有所谓的中心节点,每个节点周期性地随机找一个节点互相同步彼此的信息,理论上来说,各个节点的状态最终会保持一致。 - -下面我们来对 Gossip 协议的定义做一个总结:**Gossip 协议是一种允许在分布式系统中共享状态的去中心化通信协议,通过这种通信协议,我们可以将信息传播给网络或集群中的所有成员。** - -## Gossip 协议应用 - -NoSQL 数据库 Redis 和 Apache Cassandra、服务网格解决方案 Consul 等知名项目都用到了 Gossip 协议,学习 Gossip 协议有助于我们搞清很多技术的底层原理。 - -我们这里以 Redis Cluster 为例说明 Gossip 协议的实际应用。 - -我们经常使用的分布式缓存 Redis 的官方集群解决方案(3.0 版本引入) Redis Cluster 就是基于 Gossip 协议来实现集群中各个节点数据的最终一致性。 - -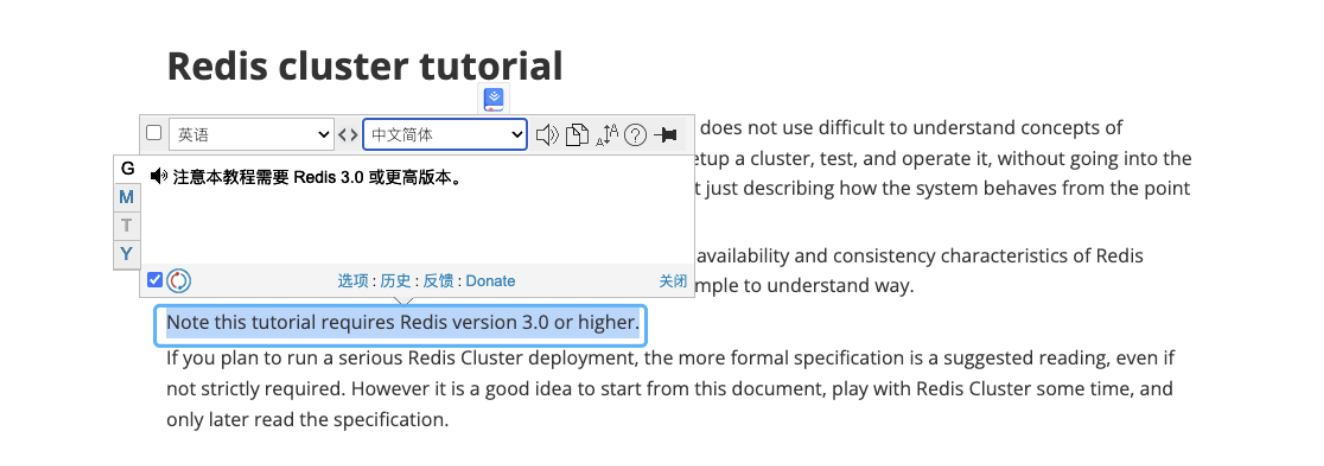 - -Redis Cluster 是一个典型的分布式系统,分布式系统中的各个节点需要互相通信。既然要相互通信就要遵循一致的通信协议,Redis Cluster 中的各个节点基于 **Gossip 协议** 来进行通信共享信息,每个 Redis 节点都维护了一份集群的状态信息。 - -Redis Cluster 的节点之间会相互发送多种 Gossip 消息: - -- **MEET**:在 Redis Cluster 中的某个 Redis 节点上执行 `CLUSTER MEET ip port` 命令,可以向指定的 Redis 节点发送一条 MEET 信息,用于将其添加进 Redis Cluster 成为新的 Redis 节点。 -- **PING/PONG**:Redis Cluster 中的节点都会定时地向其他节点发送 PING 消息,来交换各个节点状态信息,检查各个节点状态,包括在线状态、疑似下线状态 PFAIL 和已下线状态 FAIL。 -- **FAIL**:Redis Cluster 中的节点 A 发现 B 节点 PFAIL ,并且在下线报告的有效期限内集群中半数以上的节点将 B 节点标记为 PFAIL,节点 A 就会向集群广播一条 FAIL 消息,通知其他节点将故障节点 B 标记为 FAIL 。 -- …… - -下图就是主从架构的 Redis Cluster 的示意图,图中的虚线代表的就是各个节点之间使用 Gossip 进行通信 ,实线表示主从复制。 - - - -有了 Redis Cluster 之后,不需要专门部署 Sentinel 集群服务了。Redis Cluster 相当于是内置了 Sentinel 机制,Redis Cluster 内部的各个 Redis 节点通过 Gossip 协议共享集群内信息。 - -关于 Redis Cluster 的详细介绍,可以查看这篇文章 [Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html) 。 - -## Gossip 协议消息传播模式 - -Gossip 设计了两种可能的消息传播模式:**反熵(Anti-Entropy)** 和 **传谣(Rumor-Mongering)**。 - -### 反熵(Anti-entropy) - -根据维基百科: - -> 熵的概念最早起源于[物理学](https://zh.wikipedia.org/wiki/物理学),用于度量一个热力学系统的混乱程度。熵最好理解为不确定性的量度而不是确定性的量度,因为越随机的信源的熵越大。 - -在这里,你可以把反熵中的熵理解为节点之间数据的混乱程度/差异性,反熵就是指消除不同节点中数据的差异,提升节点间数据的相似度,从而降低熵值。 - -具体是如何反熵的呢?集群中的节点,每隔段时间就随机选择某个其他节点,然后通过互相交换自己的所有数据来消除两者之间的差异,实现数据的最终一致性。 - -在实现反熵的时候,主要有推、拉和推拉三种方式: - -- 推方式,就是将自己的所有副本数据,推给对方,修复对方副本中的熵。 -- 拉方式,就是拉取对方的所有副本数据,修复自己副本中的熵。 -- 推拉就是同时修复自己副本和对方副本中的熵。 - -伪代码如下: - - - -在我们实际应用场景中,一般不会采用随机的节点进行反熵,而是可以设计成一个闭环。这样的话,我们能够在一个确定的时间范围内实现各个节点数据的最终一致性,而不是基于随机的概率。像 InfluxDB 就是这样来实现反熵的。 - - - -1. 节点 A 推送数据给节点 B,节点 B 获取到节点 A 中的最新数据。 -2. 节点 B 推送数据给 C,节点 C 获取到节点 A,B 中的最新数据。 -3. 节点 C 推送数据给 A,节点 A 获取到节点 B,C 中的最新数据。 -4. 节点 A 再推送数据给 B 形成闭环,这样节点 B 就获取到节点 C 中的最新数据。 - -虽然反熵很简单实用,但是,节点过多或者节点动态变化的话,反熵就不太适用了。这个时候,我们想要实现最终一致性就要靠 **谣言传播(Rumor mongering)** 。 - -### 谣言传播(Rumor mongering) - -谣言传播指的是分布式系统中的一个节点一旦有了新数据之后,就会变为活跃节点,活跃节点会周期性地联系其他节点向其发送新数据,直到所有的节点都存储了该新数据。 - -如下图所示(下图来自于[INTRODUCTION TO GOSSIP](https://managementfromscratch.wordpress.com/2016/04/01/introduction-to-gossip/) 这篇文章): - - - -伪代码如下: - - - -谣言传播比较适合节点数量比较多的情况,不过,这种模式下要尽量避免传播的信息包不能太大,避免网络消耗太大。 - -### 总结 - -- 反熵(Anti-Entropy)会传播节点的所有数据,而谣言传播(Rumor-Mongering)只会传播节点新增的数据。 -- 我们一般会给反熵设计一个闭环。 -- 谣言传播(Rumor-Mongering)比较适合节点数量比较多或者节点动态变化的场景。 - -## Gossip 协议优势和缺陷 - -**优势:** - -1、相比于其他分布式协议/算法来说,Gossip 协议理解起来非常简单。 - -2、能够容忍网络上节点的随意地增加或者减少,宕机或者重启,因为 Gossip 协议下这些节点都是平等的,去中心化的。新增加或者重启的节点在理想情况下最终是一定会和其他节点的状态达到一致。 - -3、速度相对较快。节点数量比较多的情况下,扩散速度比一个主节点向其他节点传播信息要更快(多播)。 - -**缺陷** : - -1、消息需要通过多个传播的轮次才能传播到整个网络中,因此,必然会出现各节点状态不一致的情况。毕竟,Gossip 协议强调的是最终一致,至于达到各个节点的状态一致需要多长时间,谁也无从得知。 - -2、由于拜占庭将军问题,不允许存在恶意节点。 - -3、可能会出现消息冗余的问题。由于消息传播的随机性,同一个节点可能会重复收到相同的消息。 - -## 总结 - -- Gossip 协议是一种允许在分布式系统中共享状态的通信协议,通过这种通信协议,我们可以将信息传播给网络或集群中的所有成员。 -- Gossip 协议被 Redis、Apache Cassandra、Consul 等项目应用。 -- 谣言传播(Rumor-Mongering)比较适合节点数量比较多或者节点动态变化的场景。 - -## 参考 - -- 一万字详解 Redis Cluster Gossip 协议:
提议者
发起提案] + Acc[Acceptor
接受者
投票表决] + Lear[Learner
学习者
获取结果] + end + + Prop -->|Prepare| Acc + Acc -->|Promise| Prop + Prop -->|Accept| Acc + Acc -->|Accepted| Prop + Prop -->|通知选定| Lear - + style Roles fill:#F5F7FA,color:#333,stroke:#005D7B,stroke-width:2px + classDef role fill:#E99151,color:#FFFFFF,stroke:none,rx:10,ry:10 + + class Prop,Acc,Lear role +``` 为了减少实现该算法所需的节点数,一个节点可以身兼多个角色。并且,一个提案被选定需要被半数以上的 Acceptor 接受。这样的话,Basic Paxos 算法还具备容错性,在少于一半的节点出现故障时,集群仍能正常工作。 -## Multi Paxos 思想 +### 执行流程 + +Basic Paxos 通过两个阶段达成共识:**Prepare/Promise(准备/承诺)阶段**和 **Accept/Accepted(接受/已接受)阶段**。 + +```mermaid +sequenceDiagram + participant P as Proposer + participant A1 as Acceptor 1 + participant A2 as Acceptor 2 + participant A3 as Acceptor 3 + + note over P, A3: Phase 1: 准备阶段 (Prepare) - 争夺锁与获取历史 + P->>A1: Prepare(ID=N) + P->>A2: Prepare(ID=N) + P->>A3: Prepare(ID=N) + + A1-->>P: Promise(ID=N, 已接受值=null) + A2-->>P: Promise(ID=N, 已接受值=null) + note right of A3: 假设 A3 网络延迟未响应 + + note over P, A3: Phase 2: 接受阶段 (Accept) - 提交决议 + P->>A1: Accept(ID=N, Value="Set X=1") + P->>A2: Accept(ID=N, Value="Set X=1") + + A1-->>P: Accepted(ID=N) + A2-->>P: Accepted(ID=N) + note over P: 收到多数派 (2个) Accepted,决议达成 (Chosen) +``` + +#### Phase 1: Prepare/Promise(准备/承诺阶段) + +Proposer 选择一个提案编号 n(必须全局唯一且递增),向超过半数的 Acceptor 发送 `Prepare(n)` 请求。 + +**Acceptor 的处理逻辑**(对每个提案编号 n 的处理逻辑): + +- 若 n > 该 Acceptor 见过的最大提案编号 max_n + - 返回 `Promise(n, max_v)`,其中 max_v 是之前接受过的最大编号提案的值(若有) + - 承诺不再接受编号 < n 的提案 +- 若 n ≤ max_n + - 拒绝或忽略该请求 + +**目的**:让 Proposer 了解当前系统中已被接受或准备接受的提案,避免提出冲突的值。 + +#### Phase 2: Accept/Accepted(接受/已接受阶段) + +当 Proposer 收到超过半数 Acceptor 的 Promise 响应后,选择响应中 max_v 最大的值(若无则任意选择一个值),向超过半数的 Acceptor 发送 `Accept(n, v)` 请求。 + +**Acceptor 的处理逻辑**: + +- 若 n ≥ 该 Acceptor 在 Phase 1 承诺的 max_n + - 接受该提案,记录 (n, v),并返回 `Accepted(n, v)` +- 否则 + - 拒绝该请求 + +#### 收敛条件 + +当 Proposer 收到超过半数 Acceptor 对 `Accept(n, v)` 的响应时,提案 v 被**选定(chosen)**。Proposer 通知所有 Learner 提案已被选定。 + +### 安全性保证 + +Basic Paxos 保证以下安全性: + +1. **一致性**:一旦某个值被选定,所有后续选定的值都是该值 +2. **可终止性**:若无 Proposer 竞争且通信可靠,最终能选定一个值 + +**核心机制**:通过 Phase 1 收集 Promise,Proposer 只能选择已经被 Acceptors 承诺过的值(或选择新值),保证了不会有冲突的值被选定。 + +### 活性问题 + +Basic Paxos 存在**活锁(Livelock)**风险: + +- 若多个 Proposer 同时发起提案,且提案编号交错递增 +- 可能导致没有提案能获得超过半数的 Accept +- 系统陷入无限竞争,无法达成共识 + +**活锁示例**(Dueling Proposers): + +假设有两个 Proposer P1 和 P2 同时发起提案: + +1. P1 发送 `Prepare(1)`,P2 发送 `Prepare(2)` +2. Acceptor 们承诺给编号较大的 P2 +3. P1 发现编号被超越,发送 `Prepare(3)` +4. P2 发现编号被超越,发送 `Prepare(4)` +5. ... 循环往复,永远无法进入 Phase 2 + +**活锁时序图**: + +```mermaid +sequenceDiagram + participant P1 as Proposer 1 + participant A as Acceptors + participant P2 as Proposer 2 + + Note over P1,P2: 活锁场景:Dueling Proposers + + P1->>A: Prepare(N=1) + P2->>A: Prepare(N=2) + A-->>P1: Promise(拒绝, N=2 更大) + A-->>P2: Promise(接受, N=2) + + Note over P1: 编号被超越,递增 + P1->>A: Prepare(N=3) + A-->>P2: Promise(拒绝, N=3 更大) + A-->>P1: Promise(接受, N=3) + + Note over P2: 编号被超越,递增 + P2->>A: Prepare(N=4) + A-->>P1: Promise(拒绝, N=4 更大) + A-->>P2: Promise(接受, N=4) + + Note over P1,P2: ... 循环往复,永远无法进入 Phase 2 +``` + +**解决方案**:通过 Multi-Paxos 引入稳定的 Leader 机制。 + +**随机退避算法(Randomized Exponential Backoff)**: + +为防止多个 Proposer 竞争导致活锁,生产级实现通常引入随机退避: + +当 Proposer 的 Prepare 请求被拒绝(编号过小)时: + +1. 等待随机时间:`base_delay * random(1, 2^attempt)` +2. 选择更大的提案编号(如:`n = n + k`,`k > 0`) +3. 重试 Prepare 阶段 + +参数示例: + +- `base_delay`: 10ms +- `attempt`: 重试次数(1, 2, 3...) +- 最大退避时间:`max(1s, base_delay * 2^10)` + +这种机制确保竞争者不会同时重试,最终某个 Proposer 能成功完成 Phase 1。 + +**分区处理**:若发生网络分区,多数派一侧可继续选举 Leader 并提交新提案;少数派无法形成法定人数(quorum),只能等待分区恢复。 + +## Multi-Paxos 思想 + +### 核心思想 + +Basic Paxos 算法仅能就单个值达成共识,为了能够对一系列的值达成共识,我们需要用到 Multi-Paxos 思想。 + +Multi-Paxos 的核心优化思想是**复用 Leader**:通过 Basic Paxos 选出一个稳定的 Proposer 作为 Leader,后续提案直接由该 Leader 发起,跳过 Phase 1 的 Prepare/Promise 阶段。 + +### 优化机制 + +#### 1. Leader 稳定选举 + +- 通过 Basic Paxos 选出唯一的 Proposer 作为 Leader +- Leader 崩溃后,通过新一轮 Basic Paxos 选举新 Leader +- 避免多 Proposer 竞争导致的活锁 + +#### 2. 跳过 Phase 1 + +- Leader 稳定后,后续提案直接进入 Phase 2(Accept 阶段) +- 无需每次都执行 Prepare/Promise,减少一轮 RPC +- **延迟优化**:Basic Paxos 每个提案需要 2-RTT(Prepare + Accept),Multi-Paxos 后续提案仅需 1-RTT(仅 Accept),**提案提交延迟降低 50%**(2-RTT → 1-RTT) + +**性能优化对比图**: + +```mermaid +flowchart LR + subgraph Basic["Basic Paxos (首次提案)"] + direction TB + C1[客户端请求] --> P1[Phase 1: Prepare/Promise
1-RTT] + P1 --> P2[Phase 2: Accept/Accepted
1-RTT] + P2 --> D1[提案选定
总延迟: 2-RTT] + end + + subgraph Multi["Multi-Paxos (Leader 稳定后)"] + direction TB + C2[客户端请求] --> A[Phase 2: Accept/Accepted
1-RTT
跳过 Phase 1] + A --> D2[提案选定
总延迟: 1-RTT] + end + + style Basic fill:#FFF5F5,color:#333,stroke:#C44545,stroke-width:2px + style Multi fill:#F0FFF4,color:#333,stroke:#4CA497,stroke-width:2px + classDef phase fill:#F39C12,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef client fill:#00838F,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef done fill:#4CA497,color:#FFFFFF,stroke:none,rx:10,ry:10 + + class C1,C2 client + class P1,P2,A phase + class D1,D2 done +``` + +#### 3. 日志序号 + +- 为每个提案分配递增的**日志索引(log index)** +- 保证全局顺序:Leader 按顺序追加日志,Acceptor 按序号接受 +- 支持**空洞**:某位置的提案可能因 Leader 切换而暂时缺失,后续可补齐 + +#### 4. 日志空洞(gap)与 NOP 填补 + +**问题描述**:当新 Leader 上线时,可能遇到一种棘手场景——前任 Leader 已经在某个日志位置上达成了共识,但新 Leader 不知道这个值。如果新 Leader 试图在该位置提交新值,就会覆盖已经选定的值,破坏一致性。 + +**解决方案:NOP(No-Operation)日志** + +Multi-Paxos 通过引入 NOP 日志来解决这个问题: + +1. **场景检测**:新 Leader 在 Phase 1(Prepare)阶段,收集到 Acceptor 返回的已接受值 +2. **必须复用**:如果发现某位置已有被选定的值,新 Leader **必须**复用该值,不能提出新值 +3. **NOP 占位**:对于空洞位置(无任何已接受值),新 Leader 可以提交特殊值——NOP(空操作) +4. **状态机跳过**:NOP 日志虽然占用日志位置,但状态机回放时会跳过,不执行任何业务逻辑 + +**示例流程**: + +``` +前任 Leader 崩溃前: +Index 1: Value=A (chosen) +Index 2: Value=B (chosen) +Index 3: <空洞> (未完成) + +新 Leader 上线后: +Index 1: 复用 Value=A +Index 2: 复用 Value=B +Index 3: 提交 NOP (填补空洞,不执行业务逻辑) +Index 4: 提交 Value=C (正常业务日志) +``` + +**空洞与已接受值恢复流程**: + +```mermaid +sequenceDiagram + participant OldL as 前任 Leader + participant A1 as Acceptor 1 + participant A2 as Acceptor 2 + participant NewL as 新 Leader + participant SM as 状态机 + + Note over OldL, A2: 前任 Leader 崩溃前 + OldL->>A1: Accept(ID=5, Value="X") + OldL->>A2: Accept(ID=5, Value="X") + A1-->>OldL: Accepted(ID=5) + Note over OldL: 崩溃!未收到 A2 响应
Value="X" 已被 A1 接受 + + Note over NewL, A2: 新 Leader 上线 + NewL->>A1: Prepare(ID=10, index=5) + NewL->>A2: Prepare(ID=10, index=5) + A1-->>NewL: Promise(已接受值="X") + A2-->>NewL: Promise(已接受值=null) + + Note over NewL: 发现 A1 已接受 "X"
必须复用该值 + NewL->>A1: Accept(ID=10, index=5, Value="X") + NewL->>A2: Accept(ID=10, index=5, Value="X") + A1-->>NewL: Accepted(ID=10) + A2-->>NewL: Accepted(ID=10) + + Note over NewL, SM: 提交并回放 + NewL->>SM: Apply Value="X" + Note over SM: 状态机执行 "X"
(空洞/已接受值已安全处理) +``` + +### 执行流程 + +1. **Leader 选举**:通过 Basic Paxos 选出 Leader +2. **日志复制**:Leader 接收客户端请求,追加到本地日志,分配递增索引 +3. **直接 Accept**:Leader 向 Acceptor 发送 `Accept(index, value)`(跳过 Prepare) +4. **响应处理**:Acceptor 按序号接受日志,记录到本地 +5. **提交确认**:当超过半数 Acceptor 接受某位置的日志后,该位置可提交 + +### 容错与恢复 + +- **Leader 崩溃**:新 Leader 通过日志比对找出已提交位置,补齐未提交日志 +- **网络分区**:多数派一侧继续服务,少数派等待恢复 +- **日志空洞**:新 Leader 可填补前任 Leader 未提交的日志位置 + +**新 Leader 恢复流程图**: + +```mermaid +flowchart TB + subgraph Recovery["新 Leader 恢复流程"] + direction TB + Start[新 Leader 上线] --> Phase1[执行 Phase 1: Prepare
收集已接受值] + + Phase1 --> Check{有空洞位置?} + + Check -->|是| NOP[提交 NOP 日志
填补空洞] + Check -->|否| Next[继续下一条] + + NOP --> Next + Next --> More{还有未处理?} + + More -->|是| Phase1 + More -->|否| Done[恢复完成
开始正常服务] + end + + style Recovery fill:#F5F7FA,color:#333,stroke:#005D7B,stroke-width:2px + classDef step fill:#E99151,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef decision fill:#3498DB,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef success fill:#4CA497,color:#FFFFFF,stroke:none,rx:10,ry:10 + + class Start,Phase1,NOP,Next step + class Check,More decision + class Done success +``` + +⚠️ **注意**:Multi-Paxos 只是一种思想,这种思想的核心就是通过多个 Basic Paxos 实例就一系列值达成共识。也就是说,Basic Paxos 是 Multi-Paxos 思想的核心,Multi-Paxos 就是多执行几次 Basic Paxos。 + +由于 Lamport 提出的 Multi-Paxos 思想缺少代码实现的必要细节(比如怎么选举领导者、日志空洞如何处理),所以在理解和实现上比较困难。 + +不过,也不需要担心,我们并不需要自己实现基于 Multi-Paxos 思想的共识算法,业界已经有了比较出名的实现。如 Raft 算法虽非 Paxos 严格变体,但借鉴了其核心思想(Leader 选举、日志复制),并简化了实现细节,变得更容易被理解以及工程实现,实际项目中可以优先考虑 Raft 算法。 + +## Paxos vs Raft + +在 2014 年之后,Raft 算法凭借其极致的可理解性成为了工业界的新宠。必须明确,Raft 并非 Paxos 的变体,两者在底层设计哲学上存在硬性分歧。 + +| **对比维度** | **Multi-Paxos** | **Raft** | **核心工程影响** | +| --------------------- | ----------------------------------------------------------- | --------------------------------------------------------------------------- | ------------------------------------------------------------------------------- | +| **日志流向与约束** | 允许乱序提交,允许出现**日志空洞**。 | 强制按序追加(Append-Only),**绝对不允许日志空洞**。 | Raft 实现简单,状态机回放极其顺滑;Paxos 并发上限更高,但实现难度呈指数级增加。 | +| **Leader 选举与权限** | Leader 仅是一个性能优化手段(省略 Phase 1),非必须角色。 | **强 Leader 模型**。一切数据以 Leader 为准,日志只从 Leader 流向 Follower。 | Raft 通过限制只能选取“日志最完整”的节点当选 Leader,简化了数据恢复逻辑。 | +| **活锁防御** | 需额外引入随机退避或外部选主算法。 | 协议内置基于随机超时(Randomized Timeout)的选主防御机制。 | Raft 的开箱即用性(Out-of-the-box)远高于 Paxos。 | +| **工业级落地代表** | Apache ZooKeeper (基于 ZAB, 类 Multi-Paxos), Google Spanner | etcd, HashiCorp Consul, TiKV | 现代微服务基础设施倾向于选择 Raft。 | + +## 实际应用 + +基于 Paxos 算法或其变体的系统包括: + +- **Google Chubby**:基于 Paxos 实现的分布式锁服务 +- **Apache ZooKeeper 3.8+**:基于 ZAB 协议(类 Multi-Paxos,写入通过 Leader 广播,支持 FIFO 顺序) +- **etcd 3.5+**:基于 Raft 算法(强一致性共识,支持动态成员变更、轻量级事务 Txn) +- **HashiCorp Consul**:基于 Raft 算法(服务发现与配置管理) + +这些系统在分布式协调、配置管理、服务发现等领域发挥着关键作用。 + +> **版本说明**:上述系统随版本演进会有协议优化(如 etcd 3.4 引入租约 Keep-Alive 优化、ZooKeeper 3.5 引入动态重配置),生产部署前建议查阅对应版本的 Release Notes。 + +## 生产落地建议 + +### 可观测性指标(Observability Checklist) + +| 类别 | 关键指标 | 告警阈值建议 | 说明 | +| -------- | ------------------ | ----------------- | ---------------------------- | +| **延迟** | 提案提交延迟 (p99) | > 100ms | 从客户端请求到收到多数派确认 | +| **吞吐** | 提案处理速率 | < 预期 QPS 的 50% | 可能网络分区或节点故障 | +| **选主** | Leader 切换次数 | > 3 次/小时 | 频繁切主说明集群不稳定 | +| **空洞** | 未提交日志位置数 | > 100 | 过多空洞影响状态机回放 | +| **脑裂** | 多 Leader 竞争事件 | = 0 | 绝不允许出现 | + +### 混沌工程建议 + +| 测试场景 | 验证目标 | 推荐工具 | +| --------------- | ------------------------------ | ------------------------ | +| **Leader 崩溃** | 验证快速选主与数据零丢失 | Chaos Mesh, Chaos Monkey | +| **网络分区** | 验证多数派继续服务、少数派等待 | Toxiproxy | +| **网络抖动** | 验证随机退避机制避免活锁 | tc (netem) | +| **时钟漂移** | 验证提案编号唯一性不受影响 | -- | -Basic Paxos 算法的仅能就单个值达成共识,为了能够对一系列的值达成共识,我们需要用到 Multi Paxos 思想。 +### 常见反模式(Anti-Patterns) -⚠️**注意**:Multi-Paxos 只是一种思想,这种思想的核心就是通过多个 Basic Paxos 实例就一系列值达成共识。也就是说,Basic Paxos 是 Multi-Paxos 思想的核心,Multi-Paxos 就是多执行几次 Basic Paxos。 +1. **忽略空洞处理**:状态机回放时遇到空洞位置直接跳过,可能导致客户端请求丢失 +2. **固定提案编号**:使用时间戳或节点 ID 作为提案编号,无法保证全局递增 +3. **无超时机制**:Prepare/Accept 请求无限等待,导致系统挂起 +4. **忽略已接受值**:新 Leader 强制提交自己的值,破坏一致性 -由于兰伯特提到的 Multi-Paxos 思想缺少代码实现的必要细节(比如怎么选举领导者),所以在理解和实现上比较困难。 +## 总结 -不过,也不需要担心,我们并不需要自己实现基于 Multi-Paxos 思想的共识算法,业界已经有了比较出名的实现。像 Raft 算法就是 Multi-Paxos 的一个变种,其简化了 Multi-Paxos 的思想,变得更容易被理解以及工程实现,实际项目中可以优先考虑 Raft 算法。 +- Paxos 算法是 Lamport 在 1990 年提出的分布式共识算法,是强一致性共识的理论基础 +- Basic Paxos 通过两阶段(Prepare/Promise、Accept/Accepted)就单个值达成共识 +- Multi-Paxos 通过复用 Leader 和跳过 Phase 1 优化,实现一系列值的共识(提案延迟从 2-RTT 降至 1-RTT) +- Raft 算法借鉴了 Multi-Paxos 思想但重新设计了实现细节(强 Leader 模型、禁止日志空洞),更易于理解和工程实现 +- 在实际项目中,建议优先选择 Raft、etcd、ZooKeeper 等已完善的实现 ## 参考 +- [《Paxos Made Simple》](http://lamport.azurewebsites.net/pubs/paxos-simple.pdf) - Lamport, 2001 +- [《The Part-Time Parliament》](http://lamport.azurewebsites.net/pubs/lamport-paxos.pdf) - Lamport, 1998 +- [《In Search of an Understandable Consensus Algorithm》](https://raft.github.io/raft.pdf) - Ongaro & Ousterhout, 2014 (Raft 论文) -
劣势:OS 级别上下文切换开销(P99 恶化)、线程池大小难确定、增加 GC 压力 | +| **信号量隔离** | ✅ 轻量级、无线程切换 | ✅ 轻量级 | ✅ SemaphoreBulkhead | 优势:无额外线程开销、内存占用小
劣势:不能做超时控制(依赖业务层)、不支持异步 | + +> **GC 与调度压力**:线程池隔离会创建大量独立线程。在高并发下,真正的瓶颈在于 CPU 在海量线程间进行 **OS 级别的调度唤醒与挂起**。这种频繁的**上下文切换** 会无谓消耗大量 CPU 的 Us/Sy 时间,并直接导致业务请求的 **P99 尾延迟急剧恶化**。锁争用仅是并发争用的表象,真正的杀手是线程调度开销。Resilience4j 的 `FixedThreadPoolBulkhead` 基于 `ArrayBlockingQueue`,极高并发下也存在锁争用,但相比上下文切换开销通常次要。 + +### 系统自适应保护(Sentinel 独有) + +Sentinel 1.8+ 提供**系统自适应保护**(System Rule),其核心是引入类似 **TCP BBR** 的动态容量评估逻辑: + +**隐性核心条件**:`当前并发线程数 > (系统最大 QPS × 最小 RT)` + +| 指标 | 说明 | 典型阈值 | 版本要求 | +| -------------------- | -------------------------- | --------------------- | --------------- | +| **Load(系统负载)** | Linux `load1` 值 | > CPU 核数 × 2 | 全版本 | +| **平均 RT** | 所有入口流量的平均响应时间 | > 500ms(建议用 P99) | 1.8.0+ 支持 P99 | +| **并发线程数** | 当前并发线程数 | > 500 | 全版本 | +| **入口 QPS** | 入口流量的 QPS | > 1000 | 全版本 | + +触发后,系统会自动拒绝部分请求,避免系统崩溃。相比静态阈值,BBR 风格的动态容量评估能防止静态阈值滞后导致的系统崩溃。 + +### 选型建议与迁移 Trade-offs + +| 场景 | 推荐方案 | 迁移 Trade-offs | +| ------------------------------ | -------------------------- | ------------------------------------------ | +| 新项目(Spring Cloud Alibaba) | **Sentinel 1.8.2+** | 无迁移成本 | +| 新项目(响应式/轻量级) | **Resilience4j 1.7.1+** | 需自行实现控制台 | +| 存量项目(Hystrix) | 继续使用 Hystrix,规划迁移 | 迁移成本:API 变更 + 控制台搭建 + 规则迁移 | +| 需要系统自适应保护 | **Sentinel**(独有) | 无替代方案 | + +## 推荐阅读 + +- [Circuit Breaker Pattern - Martin Fowler](https://martinfowler.com/bliki/CircuitBreaker.html) +- [Sentinel 官方文档](https://sentinelguard.io/zh-cn/docs/introduction.html) +- [Release It! - Michael Nygard(生产级降级与熔断实践)](https://www.pragprog.com/titles/mnee2/release-it-second-edition/) +- [PACELC: A Simple Perspective on Latency and Consistency](https://www.cs.berkeley.edu/~brewer/cs262/PACELC.pdf) + +## 参考 + +- [Sentinel 与 Hystrix 的对比](https://github.com/alibaba/Sentinel/wiki/Sentinel-%E4%B8%8E-Hystrix-%E7%9A%84%E5%AF%B9%E6%AF%94) +- [Spring Cloud Alibaba 官方文档](https://spring-cloud-alibaba-group.github.io/github-pages/2022/zh-cn/index.html) +- [高并发之服务降级与熔断](https://suprisemf.github.io/2018/08/03/%E9%AB%98%E5%B9%B6%E5%8F%91%E4%B9%8B%E6%9C%8D%E5%8A%A1%E9%99%8D%E7%BA%A7%E4%B8%8E%E7%86%94%E6%96%AD/) + + diff --git a/docs/high-availability/high-availability-system-design.md b/docs/high-availability/high-availability-system-design.md index f461f93e99b..4f95cf5e32f 100644 --- a/docs/high-availability/high-availability-system-design.md +++ b/docs/high-availability/high-availability-system-design.md @@ -1,71 +1,202 @@ --- title: 高可用系统设计指南 +description: 本文系统讲解高可用系统设计的核心知识,涵盖可用性衡量标准(SLA/多少个9)、常见故障原因(硬件故障/代码缺陷/流量激增/网络攻击)、以及10+种提升系统可用性的方法(集群/限流/熔断/降级/缓存/异步/灰度发布等),助力高可用架构设计与面试。 category: 高可用 icon: design +head: + - - meta + - name: keywords + content: 高可用,系统可用性,SLA,可用性指标,限流,熔断,降级,集群,灰度发布,高可用架构,系统稳定性 --- ## 什么是高可用?可用性的判断标准是啥? -高可用描述的是一个系统在大部分时间都是可用的,可以为我们提供服务的。高可用代表系统即使在发生硬件故障或者系统升级的时候,服务仍然是可用的。 +**高可用(High Availability,简称 HA)** 描述的是一个系统在大部分时间都是可用的,可以为我们提供服务的。高可用代表系统即使在发生硬件故障或者系统升级的时候,服务仍然是可用的。 -一般情况下,我们使用多少个 9 来评判一个系统的可用性,比如 99.9999% 就是代表该系统在所有的运行时间中只有 0.0001% 的时间是不可用的,这样的系统就是非常非常高可用的了!当然,也会有系统如果可用性不太好的话,可能连 9 都上不了。 +一般情况下,我们使用 **多少个 9** 来评判一个系统的可用性,比如 99.9999% 就是代表该系统在所有的运行时间中只有 0.0001% 的时间是不可用的,这样的系统就是非常非常高可用的了!当然,也会有系统如果可用性不太好的话,可能连 9 都上不了。 -除此之外,系统的可用性还可以用某功能的失败次数与总的请求次数之比来衡量,比如对网站请求 1000 次,其中有 10 次请求失败,那么可用性就是 99%。 +| 可用性等级 | 可用性百分比 | 年度停机时间 | 典型场景 | +| ---------- | ------------ | ------------ | ------------ | +| 1 个 9 | 90% | 36.5 天 | 个人博客 | +| 2 个 9 | 99% | 3.65 天 | 普通企业系统 | +| 3 个 9 | 99.9% | 8.76 小时 | 在线服务 | +| 4 个 9 | 99.99% | 52.6 分钟 | 金融交易系统 | +| 5 个 9 | 99.999% | 5.26 分钟 | 电信级系统 | + +除此之外,系统的可用性还可以用 **某功能的失败次数与总的请求次数之比** 来衡量,比如对网站请求 1000 次,其中有 10 次请求失败,那么可用性就是 99%。 + +**SLA(Service Level Agreement,服务级别协议)** 是服务提供商与客户之间的正式承诺,通常会明确规定可用性目标。例如,云服务商承诺 99.95% 的 SLA,意味着每月最多允许约 22 分钟的停机时间。 ## 哪些情况会导致系统不可用? -1. 黑客攻击; -2. 硬件故障,比如服务器坏掉。 -3. 并发量/用户请求量激增导致整个服务宕掉或者部分服务不可用。 -4. 代码中的坏味道导致内存泄漏或者其他问题导致程序挂掉。 -5. 网站架构某个重要的角色比如 Nginx 或者数据库突然不可用。 -6. 自然灾害或者人为破坏。 -7. …… +导致系统不可用的原因可以从 **内部因素** 和 **外部因素** 两个维度来分析: + +**内部因素:** + +1. **代码缺陷**:比如内存泄漏、死锁、循环依赖、空指针异常等代码质量问题,是导致线上故障的最常见原因之一。 +2. **架构设计缺陷**:单点故障、缺少限流保护、服务间强耦合等架构问题,会在流量高峰时暴露出来。 +3. **资源耗尽**:CPU、内存、磁盘、连接池等资源耗尽会直接导致服务不可用。 +4. **配置错误**:错误的配置变更(如数据库连接串、超时时间配置不当)可能导致服务异常。 + +**外部因素:** + +1. **硬件故障**:服务器宕机、磁盘损坏、网络设备故障等。 +2. **流量激增**:突发的用户请求量(如秒杀活动)超过系统承载能力。 +3. **网络攻击**:DDoS 攻击、CC 攻击等恶意攻击会耗尽系统资源。 +4. **依赖服务故障**:数据库、缓存、消息队列、第三方 API 等依赖服务不可用。 +5. **自然灾害**:机房停电、火灾、地震等不可抗力因素。 ## 有哪些提高系统可用性的方法? +提高系统可用性的方法可以从 **预防**、**容错**、**恢复** 三个阶段来考虑: + +```mermaid +flowchart TB + subgraph Resilience["🛡️ 系统韧性三阶段
"] + direction TB + + %% ================= 预防 ================= + subgraph Prevention["🧯 预防:把风险前置
"] + direction TB + A["🧹 质量与测试
Review / 静态扫描 / 单元测试"] + B["🧩 高可用架构
多副本 / 多 AZ / 负载均衡"] + C["🧊 缓存与本地化
降延迟 / 减下游压力"] + D["🧪 灰度发布
Canary / 分批 / 快速回滚"] + end + + P2T["⬇️ 从“少出错”到“扛得住”
进入故障控制面"] + + %% ================= 容错 ================= + subgraph Tolerance["🧱 容错:隔离止血,保核心链路
"] + direction TB + E["🚦 限流
令牌桶 / 并发控制"] + F["⏱️ 超时与重试
超时预算 / 指数退避 / 幂等"] + G["🧨 熔断
错误率阈值 / 半开探测"] + H["🪂 降级
兜底返回 / 关非核心"] + I["🧵 异步与队列
削峰填谷 / 解耦 / 最终一致"] + end + + T2R["⬇️ 从“止血”到“恢复”
进入定位与处置"] + + %% ================= 恢复 ================= + subgraph Recovery["🔧 恢复:定位修复,回到 SLO
"] + direction TB + J["📡 可观测与告警
指标 / 日志 / Trace(SLI/SLO)"] + K["⏪ 回滚与灾备
版本回退 / 数据回放 / 切换"] + end + + %% 主链路 + Prevention --> P2T --> Tolerance --> T2R --> Recovery + end + + %% =============== 样式(统一、少而清) =============== + classDef prevent fill:#52B788,stroke:#2E8B57,color:#fff; + classDef tolerate fill:#3498DB,stroke:#2980B9,color:#fff; + classDef recover fill:#F4D03F,stroke:#D35400,color:#333; + classDef pivot fill:#2C3E50,stroke:#1A252F,color:#fff; + + class A,B,C,D prevent; + class E,F,G,H,I tolerate; + class J,K recover; + class P2T,T2R pivot; + + style Prevention fill:#FFF3E0,stroke:#FFCC80,stroke-dasharray: 5 5; + style Tolerance fill:#E3F2FD,stroke:#90CAF9,stroke-dasharray: 5 5; + style Recovery fill:#E8F5E9,stroke:#A5D6A7,stroke-dasharray: 5 5; + + style Resilience fill:#F5F5F5,stroke:#BDBDBD,rx:20,ry:20; +``` + ### 注重代码质量,测试严格把关 -我觉得这个是最最最重要的,代码质量有问题比如比较常见的内存泄漏、循环依赖都是对系统可用性极大的损害。大家都喜欢谈限流、降级、熔断,但是我觉得从代码质量这个源头把关是首先要做好的一件很重要的事情。如何提高代码质量?比较实际可用的就是 CodeReview,不要在乎每天多花的那 1 个小时左右的时间,作用可大着呢! +**代码质量是系统可用性的根基**。代码质量有问题比如比较常见的内存泄漏、循环依赖都是对系统可用性极大的损害。大家都喜欢谈限流、降级、熔断,但是从代码质量这个源头把关是首先要做好的一件很重要的事情。 -另外,安利几个对提高代码质量有实际效果的神器: +如何提高代码质量?比较实际可用的就是 **Code Review**,不要在乎每天多花的那 1 个小时左右的时间,作用可大着呢! -- [Sonarqube](https://www.sonarqube.org/); -- Alibaba 开源的 Java 诊断工具 [Arthas](https://arthas.aliyun.com/doc/); -- [阿里巴巴 Java 代码规范](https://github.com/alibaba/p3c)(Alibaba Java Code Guidelines); +另外,安利几个对提高代码质量有实际效果的工具: + +- [Sonarqube](https://www.sonarqube.org/):静态代码分析平台,可检测代码坏味道、安全漏洞和 Bug。 +- Alibaba 开源的 Java 诊断工具 [Arthas](https://arthas.aliyun.com/doc/):可在线排查 JVM 问题,支持热更新代码。 +- [阿里巴巴 Java 代码规范](https://github.com/alibaba/p3c)(Alibaba Java Code Guidelines):配套 IDEA 插件,实时检查代码规范。 - IDEA 自带的代码分析等工具。 ### 使用集群,减少单点故障 -先拿常用的 Redis 举个例子!我们如何保证我们的 Redis 缓存高可用呢?答案就是使用集群,避免单点故障。当我们使用一个 Redis 实例作为缓存的时候,这个 Redis 实例挂了之后,整个缓存服务可能就挂了。使用了集群之后,即使一台 Redis 实例挂了,不到一秒就会有另外一台 Redis 实例顶上。 +**单点故障(Single Point of Failure,SPOF)** 是高可用的大敌。先拿常用的 Redis 举个例子!我们如何保证我们的 Redis 缓存高可用呢?答案就是使用集群,避免单点故障。 + +当我们使用一个 Redis 实例作为缓存的时候,这个 Redis 实例挂了之后,整个缓存服务可能就挂了。使用了集群之后,即使一台 Redis 实例挂了,不到一秒就会有另外一台 Redis 实例顶上。 + +常见的集群模式: + +- **主从复制(Master-Slave)**:一主多从,主节点负责写,从节点负责读,主节点故障时需要手动或借助哨兵进行故障转移。 +- **哨兵模式(Sentinel)**:在主从复制基础上增加哨兵节点,实现自动故障检测和转移。 +- **分布式集群(Cluster)**:数据分片存储在多个节点,每个分片有主从副本,兼顾高可用和水平扩展。 ### 限流 -流量控制(flow control),其原理是监控应用流量的 QPS 或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。——来自 [alibaba-Sentinel](https://github.com/alibaba/Sentinel "Sentinel") 的 wiki。 +**限流(Rate Limiting)** 是保护系统的第一道防线。其原理是监控应用流量的 QPS 或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。——来自 [alibaba-Sentinel](https://github.com/alibaba/Sentinel "Sentinel") 的 wiki。 + +常见的限流算法包括: + +- **固定窗口计数器**:实现简单,但存在临界点突刺问题。 +- **滑动窗口计数器**:解决了固定窗口的临界问题,更加平滑。 +- **漏桶算法**:以固定速率处理请求,适合流量整形。 +- **令牌桶算法**:允许一定程度的突发流量,更加灵活。 ### 超时和重试机制设置 -一旦用户请求超过某个时间的得不到响应,就抛出异常。这个是非常重要的,很多线上系统故障都是因为没有进行超时设置或者超时设置的方式不对导致的。我们在读取第三方服务的时候,尤其适合设置超时和重试机制。一般我们使用一些 RPC 框架的时候,这些框架都自带的超时重试的配置。如果不进行超时设置可能会导致请求响应速度慢,甚至导致请求堆积进而让系统无法再处理请求。重试的次数一般设为 3 次,再多次的重试没有好处,反而会加重服务器压力(部分场景使用失败重试机制会不太适合)。 +一旦用户请求超过某个时间的得不到响应,就抛出异常。这个是非常重要的,很多线上系统故障都是因为 **没有进行超时设置或者超时设置的方式不对** 导致的。 + +我们在读取第三方服务的时候,尤其适合设置超时和重试机制。一般我们使用一些 RPC 框架的时候,这些框架都自带的超时重试的配置。如果不进行超时设置可能会导致请求响应速度慢,甚至导致请求堆积进而让系统无法再处理请求。 + +**重试的次数一般设为 3 次**,再多次的重试没有好处,反而会加重服务器压力(部分场景使用失败重试机制会不太适合)。同时,重试需要配合 **指数退避** 策略,避免重试风暴。 ### 熔断机制 -超时和重试机制设置之外,熔断机制也是很重要的。 熔断机制说的是系统自动收集所依赖服务的资源使用情况和性能指标,当所依赖的服务恶化或者调用失败次数达到某个阈值的时候就迅速失败,让当前系统立即切换依赖其他备用服务。 比较常用的流量控制和熔断降级框架是 Netflix 的 Hystrix 和 alibaba 的 Sentinel。 +超时和重试机制设置之外,**熔断机制** 也是很重要的。熔断机制说的是系统自动收集所依赖服务的资源使用情况和性能指标,当所依赖的服务恶化或者调用失败次数达到某个阈值的时候就迅速失败,让当前系统立即切换依赖其他备用服务。 + +熔断器有三种状态: + +- **关闭(Closed)**:正常状态,请求正常通过。 +- **打开(Open)**:熔断状态,请求直接失败,不调用下游服务。 +- **半开(Half-Open)**:尝试恢复状态,放行少量请求探测下游服务是否恢复。 + +比较常用的流量控制和熔断降级框架是 Netflix 的 Hystrix 和 alibaba 的 Sentinel。 + +### 降级 + +**降级(Degradation)** 是在系统压力过大或部分服务不可用时,暂时关闭一些非核心功能,保证核心功能的可用性。 + +降级策略包括: + +- **功能降级**:关闭推荐、评论等非核心功能。 +- **数据降级**:返回缓存数据或默认数据,而非实时查询。 +- **页面降级**:返回静态页面或简化版页面。 ### 异步调用 -异步调用的话我们不需要关心最后的结果,这样我们就可以用户请求完成之后就立即返回结果,具体处理我们可以后续再做,秒杀场景用这个还是蛮多的。但是,使用异步之后我们可能需要 **适当修改业务流程进行配合**,比如**用户在提交订单之后,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**。除了可以在程序中实现异步之外,我们常常还使用消息队列,消息队列可以通过异步处理提高系统性能(削峰、减少响应所需时间)并且可以降低系统耦合性。 +异步调用的话我们不需要关心最后的结果,这样我们就可以用户请求完成之后就立即返回结果,具体处理我们可以后续再做,秒杀场景用这个还是蛮多的。 + +但是,使用异步之后我们可能需要 **适当修改业务流程进行配合**,比如 **用户在提交订单之后,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**。 + +除了可以在程序中实现异步之外,我们常常还使用 **消息队列**,消息队列可以通过异步处理提高系统性能(削峰、减少响应所需时间)并且可以降低系统耦合性。 ### 使用缓存 如果我们的系统属于并发量比较高的话,如果我们单纯使用数据库的话,当大量请求直接落到数据库可能数据库就会直接挂掉。使用缓存缓存热点数据,因为缓存存储在内存中,所以速度相当地快! +缓存的典型应用场景: + +- **热点数据缓存**:将访问频繁的数据放入 Redis 等缓存中。 +- **页面缓存**:将渲染后的页面缓存起来,减少服务器压力。 +- **本地缓存**:使用 Caffeine、Guava Cache 等本地缓存,减少网络开销。 + ### 其他 -- **核心应用和服务优先使用更好的硬件** -- **监控系统资源使用情况增加报警设置。** -- **注意备份,必要时候回滚。** -- **灰度发布:** 将服务器集群分成若干部分,每天只发布一部分机器,观察运行稳定没有故障,第二天继续发布一部分机器,持续几天才把整个集群全部发布完毕,期间如果发现问题,只需要回滚已发布的一部分服务器即可 -- **定期检查/更换硬件:** 如果不是购买的云服务的话,定期还是需要对硬件进行一波检查的,对于一些需要更换或者升级的硬件,要及时更换或者升级。 -- …… +- **核心应用和服务优先使用更好的硬件**:核心服务使用更高配置的服务器、SSD 硬盘等。 +- **监控系统资源使用情况增加报警设置**:使用 Prometheus + Grafana 等监控方案,设置合理的告警阈值。 +- **注意备份,必要时候回滚**:数据库定期备份,代码版本可追溯,支持快速回滚。 +- **灰度发布**:将服务器集群分成若干部分,每天只发布一部分机器,观察运行稳定没有故障,第二天继续发布一部分机器,持续几天才把整个集群全部发布完毕,期间如果发现问题,只需要回滚已发布的一部分服务器即可。 +- **定期检查/更换硬件**:如果不是购买的云服务的话,定期还是需要对硬件进行一波检查的,对于一些需要更换或者升级的硬件,要及时更换或者升级。 diff --git a/docs/high-availability/idempotency.md b/docs/high-availability/idempotency.md index f44786fedab..d06e0002fa0 100644 --- a/docs/high-availability/idempotency.md +++ b/docs/high-availability/idempotency.md @@ -1,5 +1,6 @@ --- title: 接口幂等方案总结(付费) +description: 接口幂等性设计详解,涵盖幂等性概念、常见实现方案及在支付、订单等场景中的应用实践。 category: 高可用 icon: security-fill --- diff --git a/docs/high-availability/limit-request.md b/docs/high-availability/limit-request.md index 22db662eedf..0123a4711f5 100644 --- a/docs/high-availability/limit-request.md +++ b/docs/high-availability/limit-request.md @@ -1,5 +1,6 @@ --- title: 服务限流详解 +description: 服务限流原理与实现详解,涵盖固定窗口、滑动窗口、令牌桶、漏桶等主流限流算法的原理与应用。 category: 高可用 icon: limit_rate --- diff --git a/docs/high-availability/performance-test.md b/docs/high-availability/performance-test.md index 47201441d7e..0cccfec6a91 100644 --- a/docs/high-availability/performance-test.md +++ b/docs/high-availability/performance-test.md @@ -1,7 +1,12 @@ --- title: 性能测试入门 +description: 本文系统讲解性能测试核心知识,涵盖响应时间分位值(P90/P99/P999)、QPS/TPS、Little's Law 与曲棍球棒曲线、背压与自愈验证、性能测试分类(负载/压力/稳定性)、压测工具(JMeter/Gatling/ab)选型及性能优化策略。 category: 高可用 icon: et-performance +head: + - - meta + - name: keywords + content: 性能测试,压力测试,负载测试,QPS,TPS,RT响应时间,P99分位值,并发数,吞吐量,背压,利特尔法则,JMeter,Gatling,性能优化 --- 性能测试一般情况下都是由测试这个职位去做的,那还需要我们开发学这个干嘛呢?了解性能测试的指标、分类以及工具等知识有助于我们更好地去写出性能更好的程序,另外作为开发这个角色,如果你会性能测试的话,相信也会为你的履历加分不少。 @@ -12,22 +17,22 @@ icon: et-performance ### 用户 -当用户打开一个网站的时候,最关注的是什么?当然是网站响应速度的快慢。比如我们点击了淘宝的主页,淘宝需要多久将首页的内容呈现在我的面前,我点击了提交订单按钮需要多久返回结果等等。 +当用户打开一个网站的时候,最关注的是什么?当然是 **网站响应速度的快慢**。比如我们点击了淘宝的主页,淘宝需要多久将首页的内容呈现在我的面前,我点击了提交订单按钮需要多久返回结果等等。 所以,用户在体验我们系统的时候往往根据你的响应速度的快慢来评判你的网站的性能。 ### 开发人员 -用户与开发人员都关注速度,这个速度实际上就是我们的系统**处理用户请求的速度**。 +用户与开发人员都关注速度,这个速度实际上就是我们的系统 **处理用户请求的速度**。 -开发人员一般情况下很难直观的去评判自己网站的性能,我们往往会根据网站当前的架构以及基础设施情况给一个大概的值,比如: +开发人员一般情况下很难直观的去评判自己网站的性能,我们往往会根据网站当前的架构以及基础设施情况给一个大概的值,比如: 1. 项目架构是分布式的吗? 2. 用到了缓存和消息队列没有? 3. 高并发的业务有没有特殊处理? 4. 数据库设计是否合理? 5. 系统用到的算法是否还需要优化? -6. 系统是否存在内存泄露的问题? +6. 系统是否存在内存泄漏的问题? 7. 项目使用的 Redis 缓存多大?服务器性能如何?用的是机械硬盘还是固态硬盘? 8. …… @@ -42,7 +47,7 @@ icon: et-performance ### 运维人员 -运维人员会倾向于根据基础设施和资源的利用率来判断网站的性能,比如我们的服务器资源使用是否合理、数据库资源是否存在滥用的情况、当然,这是传统的运维人员,现在 Devops 火起来后,单纯干运维的很少了。我们这里暂且还保留有这个角色。 +运维人员会倾向于根据 **基础设施和资源的利用率** 来判断网站的性能,比如我们的服务器资源使用是否合理、数据库资源是否存在滥用的情况、当然,这是传统的运维人员,现在 Devops 火起来后,单纯干运维的很少了。我们这里暂且还保留有这个角色。 ## 性能测试需要注意的点 @@ -50,7 +55,9 @@ icon: et-performance ### 了解系统的业务场景 -**性能测试之前更需要你了解当前的系统的业务场景。** 对系统业务了解的不够深刻,我们很容易犯测试方向偏执的错误,从而导致我们忽略了对系统某些更需要性能测试的地方进行测试。比如我们的系统可以为用户提供发送邮件的功能,用户配置成功邮箱后只需输入相应的邮箱之后就能发送,系统每天大概能处理上万次发邮件的请求。很多人看到这个可能就直接开始使用相关工具测试邮箱发送接口,但是,发送邮件这个场景可能不是当前系统的性能瓶颈,这么多人用我们的系统发邮件, 还可能有很多人一起发邮件,单单这个场景就这么人用,那用户管理可能才是性能瓶颈吧! +**性能测试之前更需要你了解当前的系统的业务场景。** 对系统业务了解的不够深刻,我们很容易犯测试方向偏执的错误,从而导致我们忽略了对系统某些更需要性能测试的地方进行测试。 + +比如我们的系统可以为用户提供发送邮件的功能,用户配置成功邮箱后只需输入相应的邮箱之后就能发送,系统每天大概能处理上万次发邮件的请求。很多人看到这个可能就直接开始使用相关工具测试邮箱发送接口,但是,发送邮件这个场景可能不是当前系统的性能瓶颈,这么多人用我们的系统发邮件,还可能有很多人一起发邮件,单单这个场景就这么人用,那用户管理可能才是性能瓶颈吧! ### 历史数据非常有用 @@ -60,87 +67,142 @@ icon: et-performance ## 常见性能指标 +性能指标是衡量系统性能的核心度量标准,理解各指标之间的关系对于性能分析至关重要。 + +```mermaid +flowchart LR + subgraph Input["输入参数"] + style Input fill:#F5F7FA,color:#333333,stroke:#005D7B,stroke-width:2px + A["并发数
Concurrency"] + end + + subgraph Process["处理过程"] + style Process fill:#F5F7FA,color:#333333,stroke:#005D7B,stroke-width:2px + B["响应时间
RT"] + end + + subgraph Output["输出指标"] + style Output fill:#F5F7FA,color:#333333,stroke:#005D7B,stroke-width:2px + C["QPS/TPS
吞吐量"] + end + + A -->|"请求"| B + B -->|"计算"| C + + D["QPS = 并发数 / RT"] + + classDef core fill:#4CA497,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef process fill:#00838F,color:#FFFFFF,stroke:none,rx:10,ry:10 + classDef highlight fill:#E99151,color:#FFFFFF,stroke:none,rx:10,ry:10 + + class A core + class B process + class C,D highlight + + linkStyle default stroke-width:2px,stroke:#333333,opacity:0.8 +``` + ### 响应时间 -**响应时间 RT(Response-time)就是用户发出请求到用户收到系统处理结果所需要的时间。** +**响应时间 RT(Response Time)** 是用户发出请求到收到系统处理结果所需的时间,包括网络传输、服务端处理与客户端渲染等环节。 -RT 是一个非常重要且直观的指标,RT 数值大小直接反应了系统处理用户请求速度的快慢。 +**响应时间指标(Latency Percentiles)**:生产环境中看平均 RT 毫无意义,必须监控 **P90、P99 和 P999** 分位值。例如 P99 = 500ms 意味着 99% 的请求在 500ms 内返回。那 1% 的长尾慢调用(可能由 Cache Miss、慢 SQL 或 GC STW 引起)在极高并发下会发生排队效应,瞬间打满网关或 RPC 框架的底层工作线程池,直接引发雪崩。大量超快响应会拉低平均值,掩盖致命的长尾问题,此为典型的 **"均值陷阱"**。 + +分位值参考标准如下: + +| 分位值 | RT 范围(示例) | 说明 | +| ------ | --------------- | ------------------------ | +| P90 | < 200ms | 90% 的请求在此时间内返回 | +| P99 | < 500ms | 重点关注,长尾用户体感 | +| P999 | < 1s | 极端场景,易触发雪崩 | + +> **失败模式**:当发生网络偶发抖动时,P999 RT 会急剧飙升。若上游缺乏超时截断机制(Timeout & Circuit Breaking),大量并发请求将被挂起,导致上游节点内存 OOM。 ### 并发数 -**并发数可以简单理解为系统能够同时供多少人访问使用也就是说系统同时能处理的请求数量。** +**并发数可以简单理解为系统能够同时供多少人访问使用,也就是说系统同时能处理的请求数量。** -并发数反应了系统的负载能力。 +并发数反应了系统的 **负载能力**。需要注意区分以下概念: -### QPS 和 TPS +- **并发用户数**:同时在线的用户数量。 +- **并发请求数**:同一时刻系统正在处理的请求数量。 +- **最大并发数**:系统能够承受的最大并发请求数,超过此值系统可能出现性能下降或崩溃。 -- **QPS(Query Per Second)** :服务器每秒可以执行的查询次数; -- **TPS(Transaction Per Second)** :服务器每秒处理的事务数(这里的一个事务可以理解为客户发出请求到收到服务器的过程); +### QPS 和 TPS -书中是这样描述 QPS 和 TPS 的区别的。 +- **QPS(Query Per Second)**:服务器每秒可执行的查询次数; +- **TPS(Transaction Per Second)**:服务器每秒处理的事务数(一次完整业务操作)。 -> QPS vs TPS:QPS 基本类似于 TPS,但是不同的是,对于一个页面的一次访问,形成一个 TPS;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“QPS”之中。如,访问一个页面会请求服务器 2 次,一次访问,产生一个“T”,产生 2 个“Q”。 +> QPS vs TPS:一次页面访问形成 1 个 TPS,但可能产生多次对服务器的请求(计入 QPS)。**TPS 偏向业务视角,QPS 偏向技术视角。** ### 吞吐量 -**吞吐量指的是系统单位时间内系统处理的请求数量。** +**吞吐量** 指系统单位时间内处理的请求数量。TPS、QPS 是常用量化指标。 -一个系统的吞吐量与请求对系统的资源消耗等紧密关联。请求对系统资源消耗越多,系统吞吐能力越低,反之则越高。 +**Little's Law(利特尔法则)**:在系统未饱和的稳态下,`并发数 = QPS × RT`,亦即 `QPS = 并发数 / RT`。该公式仅在系统处于线性响应区间时成立。随着并发用户数持续增加,CPU 调度消耗、锁争用(Lock Contention)加剧,RT 会呈现 **指数级上升**,吞吐量达到拐点后急速下降,形成典型的 **"曲棍球棒曲线"(Hockey Stick Curve)**。下图直观展示「为什么不能用公式硬算」:拐点之后 QPS 不升反降,系统已进入非线性区。 -TPS、QPS 都是吞吐量的常用量化指标。 +```mermaid +xychart-beta + title "QPS vs 并发数(曲棍球棒曲线)" + x-axis "并发数" [200, 500, 1000, 1500, 2000, 2500, 3000, 3500, 4000] + y-axis "QPS" 0 --> 5000 + line [1200, 2800, 4200, 4800, 5000, 4750, 3800, 2400, 1200] +``` -- **QPS(TPS)** = 并发数/平均响应时间(RT) -- **并发数** = QPS \* 平均响应时间(RT) +因此,绝不能仅靠公式推算生产容量,必须通过全链路压测验证真实极限。 ## 系统活跃度指标 -### PV(Page View) +### PV(Page View) -访问量, 即页面浏览量或点击量,衡量网站用户访问的网页数量;在一定统计周期内用户每打开或刷新一个页面就记录 1 次,多次打开或刷新同一页面则浏览量累计。UV 从网页打开的数量/刷新的次数的角度来统计的。 +**访问量**,即页面浏览量或点击量,衡量网站用户访问的网页数量;在一定统计周期内用户每打开或刷新一个页面就记录 1 次,多次打开或刷新同一页面则浏览量累计。PV 从网页打开的数量/刷新的次数的角度来统计的。 -### UV(Unique Visitor) +### UV(Unique Visitor) -独立访客,统计 1 天内访问某站点的用户数。1 天内相同访客多次访问网站,只计算为 1 个独立访客。UV 是从用户个体的角度来统计的。 +**独立访客**,统计 1 天内访问某站点的用户数。1 天内相同访客多次访问网站,只计算为 1 个独立访客。UV 是从用户个体的角度来统计的。 -### DAU(Daily Active User) +### DAU(Daily Active User) -日活跃用户数量。 +**日活跃用户数量**,指一天内登录或使用产品的用户数(去重)。 -### MAU(monthly active users) +### MAU(Monthly Active Users) -月活跃用户人数。 +**月活跃用户人数**,指一个月内登录或使用产品的用户数(去重)。 -举例:某网站 DAU 为 1200w, 用户日均使用时长 1 小时,RT 为 0.5s,求并发量和 QPS。 +### 实战计算示例 -平均并发量 = DAU(1200w)\* 日均使用时长(1 小时,3600 秒) /一天的秒数(86400)=1200w/24 = 50w +> **生产级容量评估**:绝不能用 DAU 乘以固定系数去估算峰值。真实峰值往往来自特定业务场景(如整点秒杀、大促开抢)。随着并发用户数(Virtual Users)持续增加,系统 CPU 调度消耗、锁争用加剧,RT 会呈现指数级上升,此时吞吐量会达到拐点并急速下降。必须通过 **全链路压测**(结合真实流量录制与回放,如 [GoReplay](https://goreplay.org/))来摸底真实的吞吐量极限,而非纸上公式推算。 -真实并发量(考虑到某些时间段使用人数比较少) = DAU(1200w)\* 日均使用时长(1 小时,3600 秒) /一天的秒数-访问量比较小的时间段假设为 8 小时(57600)=1200w/16 = 75w - -峰值并发量 = 平均并发量 \* 6 = 300w +## 性能测试分类 -QPS = 真实并发量/RT = 75W/0.5=150w/s +| 测试类型 | 目的 | 测试方法 | +| -------------- | -------------------------- | --------------------------------------- | +| **性能测试** | 验证系统性能是否满足预期 | 在已知性能指标下验证 | +| **负载测试** | 找到系统的性能上限 | 逐步加压直到资源饱和 | +| **压力测试** | 测试极限、背压与自愈能力 | 持续加压验证崩溃后行为(429/503、自愈) | +| **稳定性测试** | 验证系统长时间运行的稳定性 | 模拟真实场景持续运行 | -## 性能测试分类 +**负载测试 vs 压力测试的水位边界**:二者区别在于「加压到哪里为止」。下图帮助建立直观水位线:负载测试在**资源饱和线**止步(找到上限);压力测试继续加压**越过饱和线**,直到崩溃并验证背压与自愈。 ### 性能测试 性能测试方法是通过测试工具模拟用户请求系统,目的主要是为了测试系统的性能是否满足要求。通俗地说,这种方法就是要在特定的运行条件下验证系统的能力状态。 -性能测试是你在对系统性能已经有了解的前提之后进行的,并且有明确的性能指标。 +性能测试是你在 **对系统性能已经有了解的前提之后** 进行的,并且有明确的性能指标。 ### 负载测试 对被测试的系统继续加大请求压力,直到服务器的某个资源已经达到饱和了,比如系统的缓存已经不够用了或者系统的响应时间已经不满足要求了。 -负载测试说白点就是测试系统的上限。 +**负载测试说白点就是测试系统的上限。** ### 压力测试 -不去管系统资源的使用情况,对系统继续加大请求压力,直到服务器崩溃无法再继续提供服务。 +不去管系统资源的使用情况,对系统持续加大请求压力,**直到系统崩溃**。压力测试的核心目的不仅是寻找崩溃点,更是验证系统在过载状态下的 **背压(Backpressure)容错性**。当并发数超越承载极限时,必须验证系统能否主动阻断流量(如返回 HTTP 429 Too Many Requests、503 Service Unavailable),避免节点假死。同时,需验证在撤除越线流量后,系统是否能自动释放挂起的连接并恢复至正常吞吐能力(**自愈性**)。这种"崩溃后行为"的验证是混沌工程与高可用架构的最佳实践。 ### 稳定性测试 -模拟真实场景,给系统一定压力,看看业务是否能稳定运行。 +模拟真实场景,给系统一定压力,看看业务是否能稳定运行。稳定性测试通常需要运行较长时间(如 7×24 小时),观察系统是否存在 **内存泄漏、连接泄漏** 等问题。 ## 常用性能测试工具 @@ -150,17 +212,25 @@ QPS = 真实并发量/RT = 75W/0.5=150w/s 推荐 4 个比较常用的性能测试工具: -1. **Jmeter** :Apache JMeter 是 JAVA 开发的性能测试工具。 -2. **LoadRunner**:一款商业的性能测试工具。 -3. **Galtling** :一款基于 Scala 开发的高性能服务器性能测试工具。 -4. **ab** :全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。 +| 工具 | 开发语言 | 特点 | 适用场景 | +| -------------- | -------- | ------------------------------------- | ------------------------ | +| **JMeter** | Java | 功能全面,支持 GUI 和命令行,插件丰富 | 复杂场景测试、企业级应用 | +| **Gatling** | Scala | 基于 Akka,代码驱动,报告美观 | 高并发场景、CI/CD 集成 | +| **ab** | C | 轻量简单,Apache 自带 | 快速接口测试、基准测试 | +| **LoadRunner** | - | 商业软件,功能强大 | 企业级大规模测试 | 没记错的话,除了 **LoadRunner** 其他几款性能测试工具都是开源免费的。 +**选型建议:** + +- **快速验证**:使用 `ab` 或 `wrk` 进行简单的接口压测。 +- **复杂场景**:使用 `JMeter`,支持录制脚本、参数化、断言等功能。 +- **代码驱动**:使用 `Gatling`,适合开发人员,易于版本控制和 CI 集成。 + ### 前端常用 1. **Fiddler**:抓包工具,它可以修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是 Web 调试的利器。 -2. **HttpWatch**: 可用于录制 HTTP 请求信息的工具。 +2. **HttpWatch**:可用于录制 HTTP 请求信息的工具。 ## 常见的性能优化策略 @@ -168,11 +238,14 @@ QPS = 真实并发量/RT = 75W/0.5=150w/s 下面是一些性能优化时,我经常拿来自问的一些问题: -1. 系统是否需要缓存? -2. 系统架构本身是不是就有问题? -3. 系统是否存在死锁的地方? -4. 系统是否存在内存泄漏?(Java 的自动回收内存虽然很方便,但是,有时候代码写的不好真的会造成内存泄漏) -5. 数据库索引使用是否合理? -6. …… +| 优化方向 | 检查项 | +| ---------- | -------------------------------------------------------- | +| **缓存** | 系统是否需要缓存?热点数据是否已缓存? | +| **架构** | 系统架构本身是不是就有问题?是否需要读写分离、分库分表? | +| **并发** | 系统是否存在死锁的地方?锁的粒度是否合理? | +| **内存** | 系统是否存在内存泄漏?GC 是否频繁? | +| **数据库** | 数据库索引使用是否合理?是否存在慢 SQL? | +| **算法** | 核心算法的时间复杂度是否可以优化? | +| **IO** | 是否存在不必要的网络调用?是否可以批量操作? | diff --git a/docs/high-availability/redundancy.md b/docs/high-availability/redundancy.md index 9d14d726675..25b088bad36 100644 --- a/docs/high-availability/redundancy.md +++ b/docs/high-availability/redundancy.md @@ -1,47 +1,197 @@ --- title: 冗余设计详解 +description: 本文系统讲解冗余设计核心知识,涵盖冗余类型(硬件/软件/数据/服务冗余)、RTO/RPO 指标、高可用集群(主备/主主模式)、同城灾备、异地灾备、同城多活、异地多活架构对比及故障转移机制,助力高可用架构设计与面试。 category: 高可用 icon: cluster +head: + - - meta + - name: keywords + content: 冗余设计,高可用集群,同城灾备,异地灾备,同城多活,异地多活,故障转移,RTO,RPO,容灾架构 --- -冗余设计是保证系统和数据高可用的最常的手段。 +## 什么是冗余? -对于服务来说,冗余的思想就是相同的服务部署多份,如果正在使用的服务突然挂掉的话,系统可以很快切换到备份服务上,大大减少系统的不可用时间,提高系统的可用性。 +**冗余(Redundancy)** 是保证系统和数据高可用的最常用手段,其核心思想是 **通过部署多份相同的资源,当某一份资源出现故障时,其他资源可以接管其工作,从而保证系统的持续可用**。 -对于数据来说,冗余的思想就是相同的数据备份多份,这样就可以很简单地提高数据的安全性。 +冗余设计可以从以下几个维度来理解: -实际上,日常生活中就有非常多的冗余思想的应用。 +| 冗余类型 | 说明 | 典型实现 | +| ------------ | ---------------------- | -------------------------------- | +| **硬件冗余** | 关键硬件设备部署多份 | 双电源、双网卡、RAID 磁盘阵列 | +| **软件冗余** | 应用服务部署多个实例 | 集群部署、容器化多副本 | +| **数据冗余** | 数据存储多份副本 | 数据库主从复制、分布式存储多副本 | +| **网络冗余** | 网络链路和设备冗余 | 多运营商接入、双活负载均衡 | +| **地域冗余** | 在不同地理位置部署系统 | 同城灾备、异地多活 | -拿我自己来说,我对于重要文件的保存方法就是冗余思想的应用。我日常所使用的重要文件都会同步一份在 GitHub 以及个人云盘上,这样就可以保证即使电脑硬盘损坏,我也可以通过 GitHub 或者个人云盘找回自己的重要文件。 +对于 **服务** 来说,冗余的思想就是相同的服务部署多份,如果正在使用的服务突然挂掉的话,系统可以很快切换到备份服务上,大大减少系统的不可用时间,提高系统的可用性。 + +对于 **数据** 来说,冗余的思想就是相同的数据备份多份,这样就可以很简单地提高数据的安全性。 + +实际上,日常生活中就有非常多的冗余思想的应用。拿我自己来说,我对于重要文件的保存方法就是冗余思想的应用。我日常所使用的重要文件都会同步一份在 GitHub 以及个人云盘上,这样就可以保证即使电脑硬盘损坏,我也可以通过 GitHub 或者个人云盘找回自己的重要文件。 + +## 容灾核心指标:RTO 和 RPO + +在讨论容灾架构之前,需要先理解两个核心指标: + +```mermaid +flowchart TB + subgraph Timeline["时间线"] + direction LR + A["上次备份"] --> B["故障发生"] --> C["系统恢复"] + end + A -.->|"数据丢失窗口(RPO)"| B + B -.->|"恢复时间窗口(RTO)"| C + + classDef core fill:#4CA497,color:#fff,rx:10,ry:10 + classDef highlight fill:#E99151,color:#fff,rx:10,ry:10 + + class A,B,C core + + style Timeline fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + +- **RPO(Recovery Point Objective,恢复点目标)**:可容忍的 **最大数据丢失量**,即从上次备份到故障发生之间的数据。RPO = 0 表示不允许丢失任何数据。 +- **RTO(Recovery Time Objective,恢复时间目标)**:可容忍的 **最大恢复时间**,即从故障发生到系统恢复正常服务的时间。RTO = 0 表示服务不能中断。 + +| 架构方案 | RPO | RTO | 成本 | +| ---------- | -------------- | ----------- | ---- | +| 单机无备份 | 可能全部丢失 | 不可预估 | 低 | +| 本地备份 | 取决于备份周期 | 小时级 | 低 | +| 同城灾备 | 分钟级 | 分钟~小时级 | 中 | +| 异地灾备 | 分钟~小时级 | 小时级 | 中高 | +| 同城多活 | 秒级 | 秒级 | 高 | +| 异地多活 | 秒级 | 秒级 | 很高 | + +## 冗余架构方案对比 高可用集群(High Availability Cluster,简称 HA Cluster)、同城灾备、异地灾备、同城多活和异地多活是冗余思想在高可用系统设计中最典型的应用。 -- **高可用集群** : 同一份服务部署两份或者多份,当正在使用的服务突然挂掉的话,可以切换到另外一台服务,从而保证服务的高可用。 -- **同城灾备**:一整个集群可以部署在同一个机房,而同城灾备中相同服务部署在同一个城市的不同机房中。并且,备用服务不处理请求。这样可以避免机房出现意外情况比如停电、火灾。 -- **异地灾备**:类似于同城灾备,不同的是,相同服务部署在异地(通常距离较远,甚至是在不同的城市或者国家)的不同机房中 -- **同城多活**:类似于同城灾备,但备用服务可以处理请求,这样可以充分利用系统资源,提高系统的并发。 -- **异地多活** : 将服务部署在异地的不同机房中,并且,它们可以同时对外提供服务。 +```mermaid +flowchart TB + subgraph Grid["冗余架构方案对比"] + direction LR + style Grid fill:#F0F2F5,stroke:#E0E6ED,stroke-width:1.5px + + subgraph HACluster["高可用集群"] + direction LR + style HACluster fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + A1["主节点"] --> A2["从节点"] + end + + subgraph LocalDR["同城灾备"] + direction LR + style LocalDR fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + B1["主机房
(处理请求)"] -.->|"同步"| B2["备机房
(不处理请求)"] + end + + subgraph RemoteDR["异地灾备"] + direction LR + style RemoteDR fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + C1["主机房
北京"] -.->|"异步同步"| C2["备机房
上海"] + end + + subgraph LocalActive["同城多活"] + direction LR + style LocalActive fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + D1["机房A
(处理请求)"] <-->|"双向同步"| D2["机房B
(处理请求)"] + end + + subgraph RemoteActive["异地多活"] + direction LR + style RemoteActive fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + E1["北京机房
(处理请求)"] <-->|"双向同步"| E2["上海机房
(处理请求)"] + end + end + + classDef core fill:#4CA497,color:#fff,rx:10,ry:10 + classDef external fill:#005D7B,color:#fff,rx:10,ry:10 + + class A1,B1,C1,D1,D2,E1,E2 core + class A2,B2,C2 external + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + +### 高可用集群 + +**高可用集群** 是指同一份服务部署两份或者多份,当正在使用的服务突然挂掉的话,可以切换到另外一台服务,从而保证服务的高可用。 -高可用集群单纯是服务的冗余,并没有强调地域。同城灾备、异地灾备、同城多活和异地多活实现了地域上的冗余。 +高可用集群有两种常见模式: -同城和异地的主要区别在于机房之间的距离。异地通常距离较远,甚至是在不同的城市或者国家。 +| 模式 | 说明 | 优点 | 缺点 | +| ------------------------------ | -------------------------- | ------------------------ | ------------------------------ | +| **主备模式(Active-Standby)** | 主节点提供服务,备节点待命 | 实现简单,数据一致性好 | 资源利用率低,备节点闲置 | +| **主主模式(Active-Active)** | 多个节点同时提供服务 | 资源利用率高,无单点故障 | 数据同步复杂,可能有一致性问题 | -和传统的灾备设计相比,同城多活和异地多活最明显的改变在于“多活”,即所有站点都是同时在对外提供服务的。异地多活是为了应对突发状况比如火灾、地震等自然或者人为灾害。 +高可用集群单纯是服务的冗余,**并没有强调地域**。同城灾备、异地灾备、同城多活和异地多活实现了地域上的冗余。 -光做好冗余还不够,必须要配合上 **故障转移** 才可以! 所谓故障转移,简单来说就是实现不可用服务快速且自动地切换到可用服务,整个过程不需要人为干涉。 +### 同城灾备 -举个例子:哨兵模式的 Redis 集群中,如果 Sentinel(哨兵) 检测到 master 节点出现故障的话, 它就会帮助我们实现故障转移,自动将某一台 slave 升级为 master,确保整个 Redis 系统的可用性。整个过程完全自动,不需要人工介入。我在[《Java 面试指北》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7)的「技术面试题篇」中的数据库部分详细介绍了 Redis 集群相关的知识点&面试题,感兴趣的小伙伴可以看看。 +**同城灾备** 是指一整个集群可以部署在同一个机房,而同城灾备中相同服务部署在 **同一个城市的不同机房** 中。并且,**备用服务不处理请求**。这样可以避免机房出现意外情况比如停电、火灾。 -再举个例子:Nginx 可以结合 Keepalived 来实现高可用。如果 Nginx 主服务器宕机的话,Keepalived 可以自动进行故障转移,备用 Nginx 主服务器升级为主服务。并且,这个切换对外是透明的,因为使用的虚拟 IP,虚拟 IP 不会改变。我在[《Java 面试指北》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7)的「技术面试题篇」中的「服务器」部分详细介绍了 Nginx 相关的知识点&面试题,感兴趣的小伙伴可以看看。 +- **适用场景**:对 RTO 要求较高(分钟级),成本有限的企业。 +- **典型配置**:两个机房距离 30~100 公里,通过专线连接。 -异地多活架构实施起来非常难,需要考虑的因素非常多。本人不才,实际项目中并没有实践过异地多活架构,我对其了解还停留在书本知识。 +### 异地灾备 -如果你想要深入学习异地多活相关的知识,我这里推荐几篇我觉得还不错的文章: +**异地灾备** 类似于同城灾备,不同的是,相同服务部署在 **异地(通常距离较远,甚至是在不同的城市或者国家)的不同机房中**。 -- [搞懂异地多活,看这篇就够了- 水滴与银弹 - 2021](https://mp.weixin.qq.com/s/T6mMDdtTfBuIiEowCpqu6Q) +- **适用场景**:需要防范区域性灾难(地震、洪水)的核心业务系统。 +- **挑战**:网络延迟较大,数据同步通常采用异步方式,可能存在数据丢失。 + +### 同城多活 + +**同城多活** 类似于同城灾备,但 **备用服务可以处理请求**,这样可以充分利用系统资源,提高系统的并发。 + +- **适用场景**:对性能和可用性都有较高要求的系统。 +- **技术要点**:需要解决数据同步、流量调度、会话管理等问题。 + +### 异地多活 + +**异地多活** 将服务部署在 **异地的不同机房** 中,并且,它们可以 **同时对外提供服务**。 + +和传统的灾备设计相比,同城多活和异地多活最明显的改变在于 **"多活"**,即所有站点都是同时在对外提供服务的。异地多活是为了应对突发状况比如火灾、地震等自然或者人为灾害。 + +同城和异地的主要区别在于 **机房之间的距离**。异地通常距离较远,甚至是在不同的城市或者国家。 + +## 故障转移机制 + +光做好冗余还不够,必须要配合上 **故障转移(Failover)** 才可以!所谓故障转移,简单来说就是 **实现不可用服务快速且自动地切换到可用服务,整个过程不需要人为干涉**。 + +故障转移通常包含以下几个步骤: + +1. **故障检测**:通过心跳检测、健康检查等机制发现故障节点。 +2. **故障确认**:避免误判,通常需要多次检测确认。 +3. **故障切换**:将流量切换到备用节点。 +4. **故障通知**:发送告警通知运维人员。 +5. **故障恢复**:故障节点恢复后重新加入集群。 + +### Redis 哨兵模式示例 + +哨兵模式的 Redis 集群中,如果 Sentinel(哨兵)检测到 master 节点出现故障的话,它就会帮助我们实现故障转移,自动将某一台 slave 升级为 master,确保整个 Redis 系统的可用性。整个过程完全自动,不需要人工介入。 + +### Nginx + Keepalived 示例 + +Nginx 可以结合 Keepalived 来实现高可用。如果 Nginx 主服务器宕机的话,Keepalived 可以自动进行故障转移,备用 Nginx 主服务器升级为主服务。并且,这个切换对外是透明的,因为使用的 **虚拟 IP(VIP)**,虚拟 IP 不会改变。 + +## 异地多活的挑战 + +异地多活架构实施起来非常难,需要考虑的因素非常多: + +| 挑战 | 说明 | 解决思路 | +| -------------- | ------------------------------ | ------------------------ | +| **数据一致性** | 多个机房数据如何保持一致 | 最终一致性、冲突解决机制 | +| **网络延迟** | 异地机房之间网络延迟较大 | 就近接入、数据分区 | +| **流量调度** | 如何将用户请求分配到合适的机房 | DNS 智能解析、GSLB | +| **会话管理** | 用户会话如何在多机房之间共享 | 分布式会话、无状态设计 | +| **成本** | 多机房建设和运维成本高 | 按业务重要性分级部署 | + +如果你想要深入学习异地多活相关的知识,推荐以下资料: + +- [搞懂异地多活,看这篇就够了 - 水滴与银弹 - 2021](https://mp.weixin.qq.com/s/T6mMDdtTfBuIiEowCpqu6Q) - [四步构建异地多活](https://mp.weixin.qq.com/s/hMD-IS__4JE5_nQhYPYSTg) - [《从零开始学架构》— 28 | 业务高可用的保障:异地多活架构](http://gk.link/a/10pKZ) -不过,这些文章大多也都是在介绍概念知识。目前,网上还缺少真正介绍具体要如何去实践落地异地多活架构的资料。 - diff --git a/docs/high-availability/timeout-and-retry.md b/docs/high-availability/timeout-and-retry.md index 3c7ba1ac9cd..c2bcabe8144 100644 --- a/docs/high-availability/timeout-and-retry.md +++ b/docs/high-availability/timeout-and-retry.md @@ -1,7 +1,12 @@ --- title: 超时&重试详解 +description: 本文系统讲解超时与重试机制核心知识,涵盖连接超时/读取超时设置原则、重试策略对比(固定间隔/指数退避/抖动退避)、重试风险(重试风暴/雪崩效应)及规避方法、幂等性设计、Java 重试框架(Spring Retry/Resilience4j)选型,助力微服务高可用设计与面试。 category: 高可用 icon: retry +head: + - - meta + - name: keywords + content: 超时机制,重试机制,指数退避,重试风暴,幂等性,连接超时,读取超时,Spring Retry,Resilience4j,微服务高可用 --- 由于网络问题、系统或者服务内部的 Bug、服务器宕机、操作系统崩溃等问题的不确定性,我们的系统或者服务永远不可能保证时刻都是可用的状态。 @@ -16,67 +21,177 @@ icon: retry ### 什么是超时机制? -超时机制说的是当一个请求超过指定的时间(比如 1s)还没有被处理的话,这个请求就会直接被取消并抛出指定的异常或者错误(比如 `504 Gateway Timeout`)。 +**超时机制** 说的是当一个请求超过指定的时间(比如 1s)还没有被处理的话,这个请求就会直接被取消并抛出指定的异常或者错误(比如 `504 Gateway Timeout`)。 我们平时接触到的超时可以简单分为下面 2 种: -- **连接超时(ConnectTimeout)**:客户端与服务端建立连接的最长等待时间。 -- **读取超时(ReadTimeout)**:客户端和服务端已经建立连接,客户端等待服务端处理完请求的最长时间。实际项目中,我们关注比较多的还是读取超时。 +| 超时类型 | 说明 | 建议值 | +| ------------------------------ | ---------------------------------------------------------- | --------------- | +| **连接超时(ConnectTimeout)** | 客户端与服务端建立连接的最长等待时间 | 1000ms ~ 5000ms | +| **读取超时(ReadTimeout)** | 客户端和服务端已建立连接后,等待服务端处理完请求的最长时间 | 1000ms ~ 3000ms | -一些连接池客户端框架中可能还会有获取连接超时和空闲连接清理超时。 +实际项目中,我们关注比较多的还是 **读取超时**。一些连接池客户端框架中可能还会有 **获取连接超时** 和 **空闲连接清理超时**。 -如果没有设置超时的话,就可能会导致服务端连接数爆炸和大量请求堆积的问题。 +### 为什么需要超时机制? + +如果没有设置超时的话,就可能会导致 **服务端连接数爆炸** 和 **大量请求堆积** 的问题。 这些堆积的连接和请求会消耗系统资源,影响新收到的请求的处理。严重的情况下,甚至会拖垮整个系统或者服务。 -我之前在实际项目就遇到过类似的问题,整个网站无法正常处理请求,服务器负载直接快被拉满。后面发现原因是项目超时设置错误加上客户端请求处理异常,导致服务端连接数直接接近 40w+,这么多堆积的连接直接把系统干趴了。 +> 我之前在实际项目就遇到过类似的问题,整个网站无法正常处理请求,服务器负载直接快被拉满。后面发现原因是项目超时设置错误加上客户端请求处理异常,导致服务端连接数直接接近 40w+,这么多堆积的连接直接把系统干趴了。 ### 超时时间应该如何设置? -超时到底设置多长时间是一个难题!超时值设置太高或者太低都有风险。如果设置太高的话,会降低超时机制的有效性,比如你设置超时为 10s 的话,那设置超时就没啥意义了,系统依然可能会出现大量慢请求堆积的问题。如果设置太低的话,就可能会导致在系统或者服务在某些处理请求速度变慢的情况下(比如请求突然增多),大量请求重试(超时通常会结合重试)继续加重系统或者服务的压力,进而导致整个系统或者服务被拖垮的问题。 +超时到底设置多长时间是一个难题!**超时值设置太高或者太低都有风险**: + +| 设置方式 | 风险 | +| ------------ | ------------------------------------------------------------------------------------ | +| **设置太高** | 降低超时机制的有效性,系统依然可能出现大量慢请求堆积的问题 | +| **设置太低** | 在系统处理速度变慢时(如请求突然增多),大量请求超时重试,加重系统压力,可能导致雪崩 | + +通常情况下,我们建议: -通常情况下,我们建议读取超时设置为 **1500ms** ,这是一个比较普适的值。如果你的系统或者服务对于延迟比较敏感的话,那读取超时值可以适当在 **1500ms** 的基础上进行缩短。反之,读取超时值也可以在 **1500ms** 的基础上进行加长,不过,尽量还是不要超过 **1500ms** 。连接超时可以适当设置长一些,建议在 **1000ms ~ 5000ms** 之内。 +- **读取超时**:设置为 **1500ms**,这是一个比较普适的值。如果系统对延迟比较敏感,可以适当缩短;反之也可以加长,但尽量不要超过 **3000ms**。 +- **连接超时**:可以适当设置长一些,建议在 **1000ms ~ 5000ms** 之内。 -没有银弹!超时值具体该设置多大,还是要根据实际项目的需求和情况慢慢调整优化得到。 +**没有银弹!** 超时值具体该设置多大,还是要根据实际项目的需求和情况慢慢调整优化得到。 -更上一层,参考[美团的 Java 线程池参数动态配置](https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html)思想,我们也可以将超时弄成可配置化的参数而不是固定的,比较简单的一种办法就是将超时的值放在配置中心中。这样的话,我们就可以根据系统或者服务的状态动态调整超时值了。 +更上一层,参考 [美团的 Java 线程池参数动态配置](https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html) 思想,我们也可以将超时弄成 **可配置化的参数** 而不是固定的,比较简单的一种办法就是将超时的值放在配置中心中。这样的话,我们就可以根据系统或者服务的状态动态调整超时值了。 ## 重试机制 ### 什么是重试机制? -重试机制一般配合超时机制一起使用,指的是多次发送相同的请求来避免瞬态故障和偶然性故障。 +**重试机制** 一般配合超时机制一起使用,指的是 **多次发送相同的请求来避免瞬态故障和偶然性故障**。 -瞬态故障可以简单理解为某一瞬间系统偶然出现的故障,并不会持久。偶然性故障可以理解为哪些在某些情况下偶尔出现的故障,频率通常较低。 +- **瞬态故障**:某一瞬间系统偶然出现的故障,并不会持久。 +- **偶然性故障**:在某些情况下偶尔出现的故障,频率通常较低。 -重试的核心思想是通过消耗服务器的资源来尽可能获得请求更大概率被成功处理。由于瞬态故障和偶然性故障是很少发生的,因此,重试对于服务器的资源消耗几乎是可以被忽略的。 +重试的核心思想是 **通过消耗服务器的资源来尽可能获得请求更大概率被成功处理**。由于瞬态故障和偶然性故障是很少发生的,因此,重试对于服务器的资源消耗几乎是可以被忽略的。 ### 常见的重试策略有哪些? -常见的重试策略有两种: - -1. **固定间隔时间重试**:每次重试之间都使用相同的时间间隔,比如每隔 1.5 秒进行一次重试。这种重试策略的优点是实现起来比较简单,不需要考虑重试次数和时间的关系,也不需要维护额外的状态信息。但是这种重试策略的缺点是可能会导致重试过于频繁或过于稀疏,从而影响系统的性能和效率。如果重试间隔太短,可能会对目标系统造成过大的压力,导致雪崩效应;如果重试间隔太长,可能会导致用户等待时间过长,影响用户体验。 -2. **梯度间隔重试**:根据重试次数的增加去延长下次重试时间,比如第一次重试间隔为 1 秒,第二次为 2 秒,第三次为 4 秒,以此类推。这种重试策略的优点是能够有效提高重试成功的几率(随着重试次数增加,但是重试依然不成功,说明目标系统恢复时间比较长,因此可以根据重试次数延长下次重试时间),也能通过柔性化的重试避免对下游系统造成更大压力。但是这种重试策略的缺点是实现起来比较复杂,需要考虑重试次数和时间的关系,以及设置合理的上限和下限值。另外,这种重试策略也可能会导致用户等待时间过长,影响用户体验。 - -这两种适合的场景各不相同。固定间隔时间重试适用于目标系统恢复时间比较稳定和可预测的场景,比如网络波动或服务重启。梯度间隔重试适用于目标系统恢复时间比较长或不可预测的场景,比如网络故障和服务故障。 +```mermaid +flowchart TB + A["请求失败"] --> B{"是否可重试?"} + B -->|"否"| C["返回错误"] + B -->|"是"| D{"重试次数
是否超限?"} + D -->|"是"| C + D -->|"否"| E{"选择退避策略"} + + E --> F["固定间隔"] + E --> G["线性退避"] + E --> H["指数退避"] + E --> I["指数退避+抖动"] + + F --> J["等待固定时间"] + G --> K["等待 n × interval"] + H --> L["等待 2^n × interval"] + I --> M["等待 2^n × interval + random"] + + J --> N["重试请求"] + K --> N + L --> N + M --> N + + N --> O{"请求成功?"} + O -->|"是"| P["返回结果"] + O -->|"否"| D + + classDef core fill:#4CA497,color:#fff,rx:10,ry:10 + classDef decision fill:#00838F,color:#fff,rx:10,ry:10 + classDef alert fill:#C44545,color:#fff,rx:10,ry:10 + classDef highlight fill:#E99151,color:#fff,rx:10,ry:10 + + class A,N core + class B,D,E,O decision + class C alert + class P highlight + class F,G,H,I,J,K,L,M core + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + +常见的重试策略对比如下: + +| 策略 | 说明 | 优点 | 缺点 | 适用场景 | +| ----------------- | --------------------------------- | ---------------------- | ---------------- | ------------------------------ | +| **固定间隔重试** | 每次重试间隔相同(如每隔 1s) | 实现简单 | 可能造成重试风暴 | 目标系统恢复时间稳定可预测 | +| **线性退避重试** | 间隔线性增长(如 1s、2s、3s) | 比固定间隔更温和 | 增长速度较慢 | 一般场景 | +| **指数退避重试** | 间隔指数增长(如 1s、2s、4s、8s) | 能有效避免重试风暴 | 等待时间可能过长 | 目标系统恢复时间较长或不可预测 | +| **指数退避+抖动** | 指数退避基础上加随机抖动 | 避免多个客户端同时重试 | 实现稍复杂 | 分布式系统推荐 | + +**大部分情况下,我们更建议使用指数退避+抖动策略**,可以有效避免重试风暴。 ### 重试的次数如何设置? 重试的次数不宜过多,否则依然会对系统负载造成比较大的压力。 -重试的次数通常建议设为 3 次。大部分情况下,我们还是更建议使用梯度间隔重试策略,比如说我们要重试 3 次的话,第 1 次请求失败后,等待 1 秒再进行重试,第 2 次请求失败后,等待 2 秒再进行重试,第 3 次请求失败后,等待 3 秒再进行重试。 +**重试的次数通常建议设为 3 次**。比如说我们要重试 3 次的话: + +- 第 1 次请求失败后,等待 1 秒再进行重试 +- 第 2 次请求失败后,等待 2 秒再进行重试 +- 第 3 次请求失败后,等待 4 秒再进行重试 + +### 重试的风险有哪些? + +重试机制虽然能提高系统的可用性,但使用不当也会带来风险: + +| 风险 | 说明 | 规避方法 | +| ------------ | -------------------------------------------- | ---------------------------- | +| **重试风暴** | 大量客户端同时重试,进一步压垮下游服务 | 使用指数退避+抖动策略 | +| **雪崩效应** | 重试导致上游服务也开始超时重试,形成连锁反应 | 设置重试预算、熔断机制 | +| **重复操作** | 非幂等操作被重复执行,导致数据不一致 | 确保操作幂等性 | +| **资源浪费** | 对永久性故障进行无意义的重试 | 区分可重试错误和不可重试错误 | + +**重试预算(Retry Budget)** 是一种有效的规避策略:限制在一定时间窗口内的重试次数占总请求数的比例,如不超过 10%。 ### 什么是重试幂等? -超时和重试机制在实际项目中使用的话,需要注意保证同一个请求没有被多次执行。 +超时和重试机制在实际项目中使用的话,需要注意保证 **同一个请求没有被多次执行**。 什么情况下会出现一个请求被多次执行呢?客户端等待服务端完成请求完成超时但此时服务端已经执行了请求,只是由于短暂的网络波动导致响应在发送给客户端的过程中延迟了。 -举个例子:用户支付购买某个课程,结果用户支付的请求由于重试的问题导致用户购买同一门课程支付了两次。对于这种情况,我们在执行用户购买课程的请求的时候需要判断一下用户是否已经购买过。这样的话,就不会因为重试的问题导致重复购买了。 +> 举个例子:用户支付购买某个课程,结果用户支付的请求由于重试的问题导致用户购买同一门课程支付了两次。对于这种情况,我们在执行用户购买课程的请求的时候需要判断一下用户是否已经购买过。这样的话,就不会因为重试的问题导致重复购买了。 + +实现幂等的常见方法: + +| 方法 | 说明 | 适用场景 | +| ------------------ | -------------------------------------- | ---------------- | +| **唯一请求 ID** | 每个请求携带唯一 ID,服务端去重 | 通用场景 | +| **数据库唯一约束** | 利用数据库唯一索引防止重复插入 | 创建类操作 | +| **乐观锁** | 通过版本号控制更新 | 更新类操作 | +| **状态机** | 通过状态流转控制,已处理的状态不再处理 | 订单、支付等场景 | ### Java 中如何实现重试? -如果要手动编写代码实现重试逻辑的话,可以通过循环(例如 while 或 for 循环)或者递归实现。不过,一般不建议自己动手实现,有很多第三方开源库提供了更完善的重试机制实现,例如 Spring Retry、Resilience4j、Guava Retrying。 +如果要手动编写代码实现重试逻辑的话,可以通过循环(例如 while 或 for 循环)或者递归实现。不过,一般不建议自己动手实现,有很多第三方开源库提供了更完善的重试机制实现: + +| 框架 | 特点 | 适用场景 | +| ------------------ | ------------------------------------ | -------------------- | +| **Spring Retry** | Spring 生态,注解驱动,配置简单 | Spring 项目 | +| **Resilience4j** | 轻量级,函数式风格,支持熔断、限流等 | 微服务项目 | +| **Guava Retrying** | 灵活的重试策略配置 | 通用 Java 项目 | +| **Failsafe** | 支持异步重试、超时、熔断等 | 需要细粒度控制的场景 | + +使用 Spring Retry 的简单示例: + +```java +@Retryable( + value = {RemoteAccessException.class}, + maxAttempts = 3, + backoff = @Backoff(delay = 1000, multiplier = 2) +) +public String callRemoteService() { + // 调用远程服务 +} + +@Recover +public String recover(RemoteAccessException e) { + // 重试失败后的兜底逻辑 + return "fallback"; +} +``` ## 参考 diff --git a/docs/high-performance/cdn.md b/docs/high-performance/cdn.md index f4ca0eab5f2..1b992be715e 100644 --- a/docs/high-performance/cdn.md +++ b/docs/high-performance/cdn.md @@ -1,50 +1,56 @@ --- title: CDN工作原理详解 +description: 本文详解 CDN(内容分发网络)的核心原理,涵盖 GSLB 全局负载均衡调度机制、CDN 缓存策略(预热/回源/刷新)、命中率与回源率优化,以及 Referer 防盗链与时间戳防盗链等安全机制,帮助你全面掌握 CDN 加速技术。 category: 高性能 head: - - meta - name: keywords - content: CDN,内容分发网络 - - - meta - - name: description - content: CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻服务器以及带宽的负担。 + content: CDN,内容分发网络,GSLB,CDN缓存,CDN回源,CDN预热,防盗链,时间戳防盗链,静态资源加速 --- + + ## 什么是 CDN ? **CDN** 全称是 Content Delivery Network/Content Distribution Network,翻译过的意思是 **内容分发网络** 。 我们可以将内容分发网络拆开来看: -- 内容:指的是静态资源比如图片、视频、文档、JS、CSS、HTML。 -- 分发网络:指的是将这些静态资源分发到位于多个不同的地理位置机房中的服务器上,这样,就可以实现静态资源的就近访问比如北京的用户直接访问北京机房的数据。 +- **内容**:指的是静态资源,包括图片、视频、文档、JS、CSS、HTML 等。 +- **分发网络**:指的是将这些静态资源分发到位于多个不同地理位置机房中的服务器上,从而实现**就近访问**——例如北京的用户直接访问北京机房的数据。 -所以,简单来说,**CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻服务器以及带宽的负担。** +简单来说,**CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻源站服务器以及带宽的负担。** -类似于京东建立的庞大的仓储运输体系,京东物流在全国拥有非常多的仓库,仓储网络几乎覆盖全国所有区县。这样的话,用户下单的第一时间,商品就从距离用户最近的仓库,直接发往对应的配送站,再由京东小哥送到你家。 +类似于京东建立的庞大仓储运输体系,京东物流在全国拥有非常多的仓库,仓储网络几乎覆盖全国所有区县。这样的话,用户下单的第一时间,商品就从距离用户最近的仓库直接发往对应的配送站,再由京东小哥送到你家。  -你可以将 CDN 看作是服务上一层的特殊缓存服务,分布在全国各地,主要用来处理静态资源的请求。 +你可以将 CDN 看作是服务上一层的**特殊缓存服务**,分布在全国各地,主要用来处理静态资源的请求。  -我们经常拿全站加速和内容分发网络做对比,不要把两者搞混了!全站加速(不同云服务商叫法不同,腾讯云叫 ECDN、阿里云叫 DCDN)既可以加速静态资源又可以加速动态资源,内容分发网络(CDN)主要针对的是 **静态资源** 。 +我们经常拿全站加速和内容分发网络做对比,不要把两者搞混了!**全站加速**(不同云服务商叫法不同,腾讯云叫 ECDN、阿里云叫 DCDN)既可以加速静态资源又可以加速动态资源,而**内容分发网络(CDN)** 主要针对的是 **静态资源** 。  绝大部分公司都会在项目开发中使用 CDN 服务,但很少会有自建 CDN 服务的公司。基于成本、稳定性和易用性考虑,建议直接选择专业的云厂商(比如阿里云、腾讯云、华为云、青云)或者 CDN 厂商(比如网宿、蓝汛)提供的开箱即用的 CDN 服务。 +## 为什么不直接将服务部署在多个不同的地方? + 很多朋友可能要问了:**既然是就近访问,为什么不直接将服务部署在多个不同的地方呢?** -- 成本太高,需要部署多份相同的服务。 -- 静态资源通常占用空间比较大且经常会被访问到,如果直接使用服务器或者缓存来处理静态资源请求的话,对系统资源消耗非常大,可能会影响到系统其他服务的正常运行。 +这涉及到**静态资源与动态请求的架构分离**问题: + +1. **成本问题**:多地部署完整服务需要部署多套应用、数据库、中间件,成本极高;而 CDN 只需存储静态资源,成本可控。 +2. **资源特性不同**:静态资源(图片、JS、CSS)具有**体积大、访问频繁、内容不变**的特点,非常适合缓存分发;动态请求需要实时计算,必须回源处理。 +3. **系统资源消耗**:如果用应用服务器直接处理静态资源请求,会大量占用 CPU、内存和带宽资源,可能影响核心业务的正常运行。 +4. **专业优化**:CDN 针对静态资源传输进行了大量优化(如智能压缩、协议优化、边缘计算),这些能力是普通应用服务器不具备的。 -同一个服务在在多个不同的地方部署多份(比如同城灾备、异地灾备、同城多活、异地多活)是为了实现系统的高可用而不是就近访问。 +> **注意**:同一个服务在多个不同地方部署多份(比如同城灾备、异地灾备、同城多活、异地多活)是为了实现系统的**高可用**,而不是就近访问。 ## CDN 工作原理是什么? -搞懂下面 3 个问题也就搞懂了 CDN 的工作原理: +理解 CDN 的工作原理,需要搞懂以下三个核心问题: 1. 静态资源是如何被缓存到 CDN 节点中的? 2. 如何找到最合适的 CDN 节点? @@ -52,79 +58,177 @@ head: ### 静态资源是如何被缓存到 CDN 节点中的? -你可以通过 **预热** 的方式将源站的资源同步到 CDN 的节点中。这样的话,用户首次请求资源可以直接从 CDN 节点中取,无需回源。这样可以降低源站压力,提升用户体验。 +CDN 缓存静态资源的方式主要有两种:**预热**和**回源**。 -如果不预热的话,你访问的资源可能不在 CDN 节点中,这个时候 CDN 节点将请求源站获取资源,这个过程是大家经常说的 **回源**。 +- **预热(Prefetch)**:主动将源站的资源推送到 CDN 节点中。这样用户首次请求资源时可以直接从 CDN 节点获取,无需回源,适用于大促活动、热点内容发布等场景。 -> - 回源:当 CDN 节点上没有用户请求的资源或该资源的缓存已经过期时,CDN 节点需要从原始服务器获取最新的资源内容,这个过程就是回源。当用户请求发生回源的话,会导致该请求的响应速度比未使用 CDN 还慢,因为相比于未使用 CDN 还多了一层 CDN 的调用流程。 -> - 预热:预热是指在 CDN 上提前将内容缓存到 CDN 节点上。这样当用户在请求这些资源时,能够快速地从最近的 CDN 节点获取到而不需要回源,进而减少了对源站的访问压力,提高了访问速度。 +- **回源(Origin Pull)**:当 CDN 节点上没有用户请求的资源或该资源的缓存已过期时,CDN 节点需要从源站获取最新的资源内容。 - +> **注意**:当用户请求触发回源时,该请求的响应速度会比未使用 CDN 还慢,因为相比于直接访问源站,多了一层 CDN 节点的调用流程。因此,提高**缓存命中率**是 CDN 优化的关键目标。 -如果资源有更新的话,你也可以对其 **刷新** ,删除 CDN 节点上缓存的旧资源,并强制 CDN 节点回源站获取最新资源。 +CDN 缓存的完整生命周期如下图所示: + +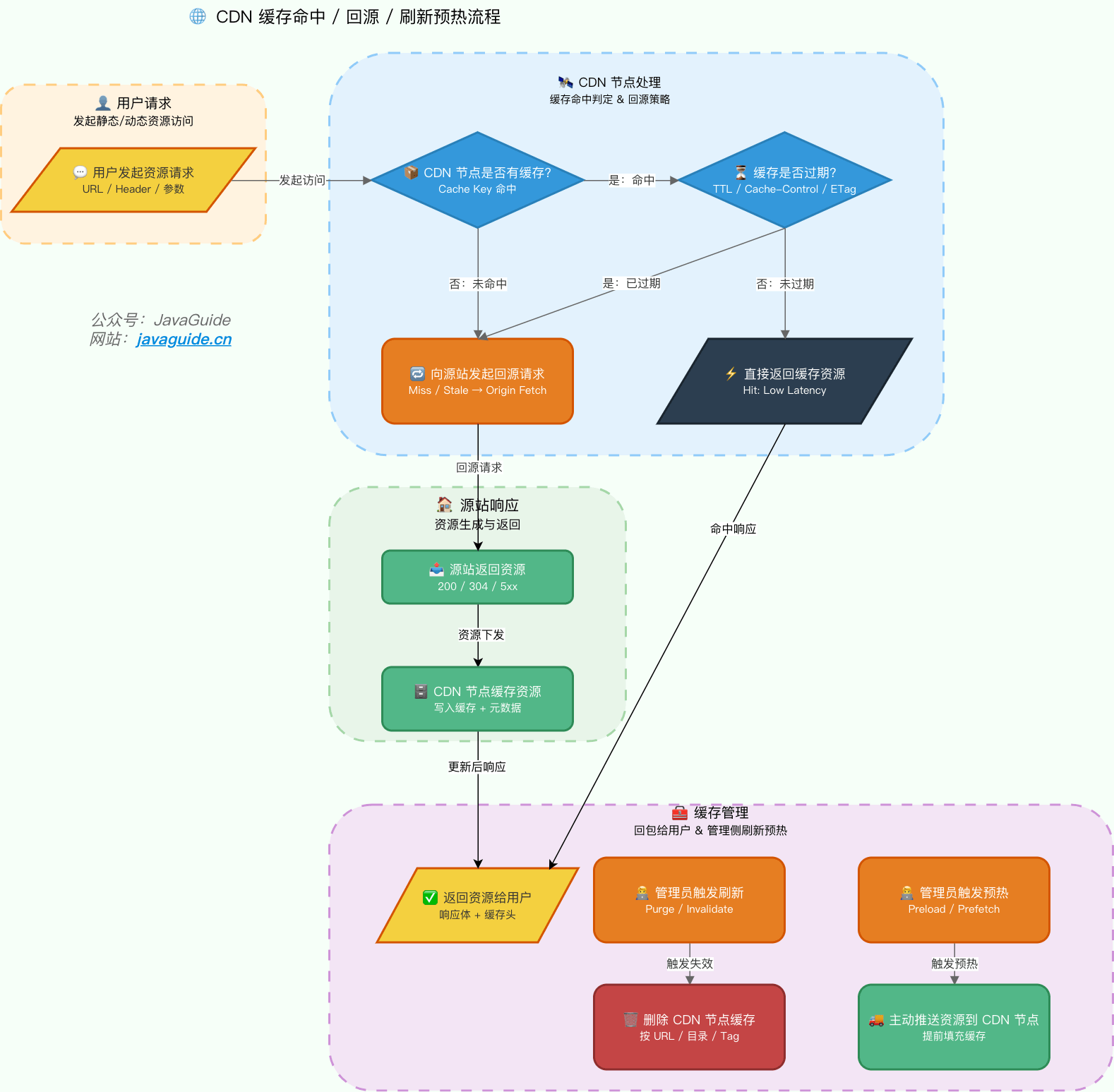 + +如果资源有更新,可以对其进行**刷新**操作,删除 CDN 节点上缓存的旧资源,并强制 CDN 节点在下次请求时回源获取最新资源。 几乎所有云厂商提供的 CDN 服务都具备缓存的刷新和预热功能(下图是阿里云 CDN 服务提供的相应功能):  -**命中率** 和 **回源率** 是衡量 CDN 服务质量两个重要指标。命中率越高越好,回源率越低越好。 +**命中率**和**回源率**是衡量 CDN 服务质量的两个核心指标: + +- **命中率**:用户请求直接由 CDN 节点响应的比例,**越高越好**。 +- **回源率**:用户请求需要回源站获取的比例,**越低越好**。 ### 如何找到最合适的 CDN 节点? -GSLB (Global Server Load Balance,全局负载均衡)是 CDN 的大脑,负责多个 CDN 节点之间相互协作,最常用的是基于 DNS 的 GSLB。 +**GSLB(Global Server Load Balance,全局负载均衡)** 是 CDN 的大脑,负责多个 CDN 节点之间的协调调度,最常用的实现方式是**基于 DNS 的 GSLB**。 + +CDN 请求的完整调度流程如下图所示: + +```mermaid +sequenceDiagram + participant User as 用户浏览器 + participant LocalDNS as 本地 DNS + participant AuthDNS as 权威 DNS + participant GSLB as CDN 全局负载均衡 + participant Edge as CDN 边缘节点 + participant Origin as 源站服务器 + + User->>LocalDNS: 1. 请求解析 cdn.example.com + LocalDNS->>AuthDNS: 2. 查询域名 + AuthDNS-->>LocalDNS: 3. 返回 CNAME 记录指向 CDN + LocalDNS->>GSLB: 4. 请求 CDN 域名解析 + + Note over GSLB: 根据用户 IP、节点负载、
网络状况等选择最优节点 + + GSLB-->>LocalDNS: 5. 返回最优 CDN 节点 IP + LocalDNS-->>User: 6. 返回 CDN 节点 IP + User->>Edge: 7. 请求静态资源 + + alt 缓存命中 + Edge-->>User: 8a. 直接返回缓存资源 + else 缓存未命中 + Edge->>Origin: 8b. 回源请求 + Origin-->>Edge: 9. 返回资源 + Note over Edge: 缓存资源 + Edge-->>User: 10. 返回资源 + end +``` -CDN 会通过 GSLB 找到最合适的 CDN 节点,更具体点来说是下面这样的: +**详细流程说明**: -1. 浏览器向 DNS 服务器发送域名请求; -2. DNS 服务器向根据 CNAME( Canonical Name ) 别名记录向 GSLB 发送请求; -3. GSLB 返回性能最好(通常距离请求地址最近)的 CDN 节点(边缘服务器,真正缓存内容的地方)的地址给浏览器; -4. 浏览器直接访问指定的 CDN 节点。 +1. 用户浏览器向本地 DNS 服务器发送域名解析请求。 +2. 本地 DNS 向权威 DNS 查询,发现该域名配置了 **CNAME(Canonical Name)别名记录**,指向 CDN 服务商的域名。 +3. 本地 DNS 继续向 CDN 的 **GSLB** 发起解析请求。 +4. GSLB 根据**用户 IP 地址、CDN 节点状态(负载、性能、响应时间、带宽)** 等指标,综合判断并返回最优 CDN 节点的 IP 地址。 +5. 用户浏览器直接向该 CDN 节点(边缘服务器)发起资源请求。 +6. CDN 节点检查本地缓存,若命中则直接返回;若未命中或已过期,则回源获取后再返回给用户。 -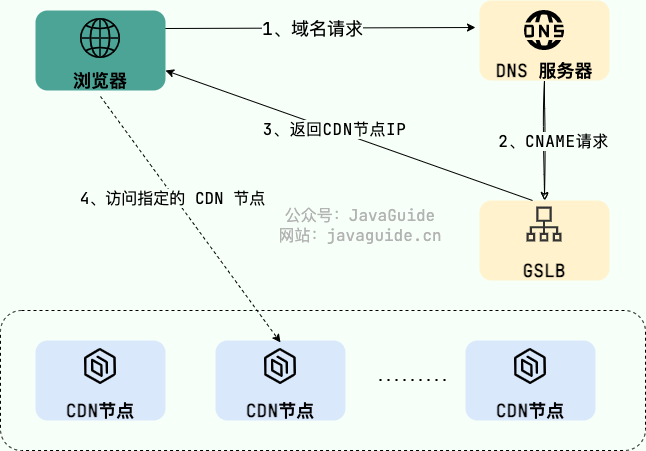 +> **补充说明**:上图做了一定简化。实际上,GSLB 内部可以看作是 **CDN 专用 DNS 服务器**和**负载均衡系统**的组合。CDN 专用 DNS 服务器会返回负载均衡系统的 IP 地址,浏览器通过该 IP 请求负载均衡系统,进而找到对应的 CDN 节点。 -为了方便理解,上图其实做了一点简化。GSLB 内部可以看作是 CDN 专用 DNS 服务器和负载均衡系统组合。CDN 专用 DNS 服务器会返回负载均衡系统 IP 地址给浏览器,浏览器使用 IP 地址请求负载均衡系统进而找到对应的 CDN 节点。 +### 如何防止资源被盗刷? -**GSLB 是如何选择出最合适的 CDN 节点呢?** GSLB 会根据请求的 IP 地址、CDN 节点状态(比如负载情况、性能、响应时间、带宽)等指标来综合判断具体返回哪一个 CDN 节点的地址。 +如果静态资源被其他用户或网站非法盗刷,将会产生大量额外的带宽费用。常见的防盗链机制有以下几种: -### 如何防止资源被盗刷? +| 防盗链机制 | 原理 | 安全强度 | 实现成本 | 绕过难度 | +| ------------------ | --------------------------------------------- | -------- | -------- | -------------------------- | +| **Referer 防盗链** | 根据 HTTP 请求头中的 Referer 字段判断请求来源 | 低 | 低 | 低(可伪造或置空 Referer) | +| **时间戳防盗链** | URL 中携带签名和过期时间,过期后 URL 失效 | 中 | 中 | 中(需要获取签名算法) | +| **IP 黑白名单** | 限制或允许特定 IP 地址访问 | 中 | 低 | 中(可通过代理绕过) | +| **Token 鉴权** | 业务服务器生成 Token,CDN 节点校验 | 高 | 高 | 高 | -如果我们的资源被其他用户或者网站非法盗刷的话,将会是一笔不小的开支。 +#### Referer 防盗链 -解决这个问题最常用最简单的办法设置 **Referer 防盗链**,具体来说就是根据 HTTP 请求的头信息里面的 Referer 字段对请求进行限制。我们可以通过 Referer 字段获取到当前请求页面的来源页面的网站地址,这样我们就能确定请求是否来自合法的网站。 +通过检查 HTTP 请求头中的 **Referer** 字段来判断请求来源是否合法。可以配置允许访问的域名白名单,非白名单来源的请求将被拒绝。 -CDN 服务提供商几乎都提供了这种比较基础的防盗链机制。 +CDN 服务提供商几乎都支持这种基础的防盗链机制: 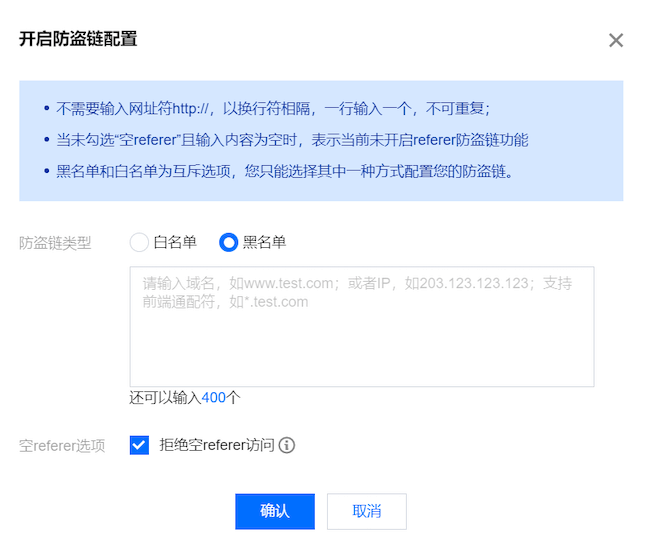 -不过,如果站点的防盗链配置允许 Referer 为空的话,通过隐藏 Referer,可以直接绕开防盗链。 +> **注意**:如果防盗链配置允许 Referer 为空,攻击者可以通过隐藏 Referer 的方式绕过防盗链检查。因此,Referer 防盗链通常需要配合其他机制一起使用。 + +#### 时间戳防盗链 -通常情况下,我们会配合其他机制来确保静态资源被盗用,一种常用的机制是 **时间戳防盗链** 。相比之下,**时间戳防盗链** 的安全性更强一些。时间戳防盗链加密的 URL 具有时效性,过期之后就无法再被允许访问。 +**时间戳防盗链**的安全性更强,其核心原理是:URL 中携带**签名字符串**和**过期时间**,CDN 节点在处理请求时会校验签名并检查是否过期,过期的 URL 将被拒绝访问。 -时间戳防盗链的 URL 通常会有两个参数一个是签名字符串,一个是过期时间。签名字符串一般是通过对用户设定的加密字符串、请求路径、过期时间通过 MD5 哈希算法取哈希的方式获得。 +签名字符串通常通过对**加密密钥 + 请求路径 + 过期时间**进行 MD5 哈希计算得到。 时间戳防盗链 URL 示例: ```plain -http://cdn.wangsu.com/4/123.mp3? wsSecret=79aead3bd7b5db4adeffb93a010298b5&wsTime=1601026312 +http://cdn.example.com/video/123.mp4?wsSecret=79aead3bd7b5db4adeffb93a010298b5&wsTime=1601026312 ``` -- `wsSecret`:签名字符串。 -- `wsTime`: 过期时间。 +- `wsSecret`:签名字符串,由服务端根据密钥和请求信息计算生成。 +- `wsTime`:过期时间戳(Unix 时间戳格式)。 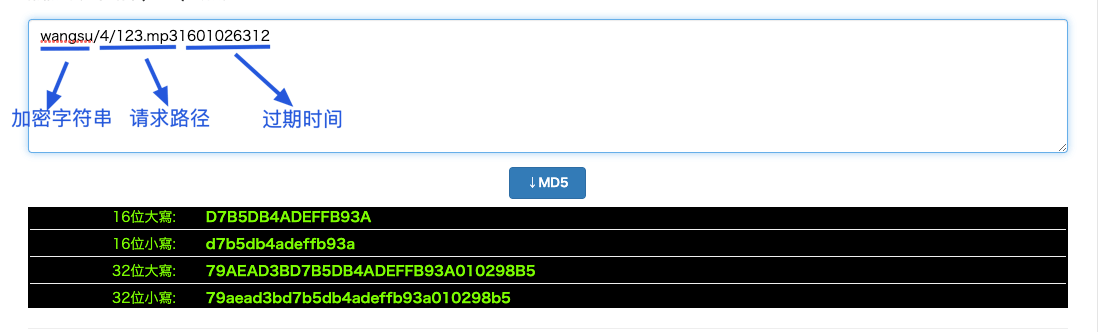 -时间戳防盗链的实现也比较简单,并且可靠性较高,推荐使用。并且,绝大部分 CDN 服务提供商都提供了开箱即用的时间戳防盗链机制。 +绝大部分 CDN 服务提供商都支持开箱即用的时间戳防盗链机制:  -除了 Referer 防盗链和时间戳防盗链之外,你还可以 IP 黑白名单配置、IP 访问限频配置等机制来防盗刷。 +> **推荐实践**:生产环境建议采用 **Referer 防盗链 + 时间戳防盗链**的组合方案,兼顾安全性与实现成本。对于安全性要求极高的场景(如付费内容),可进一步引入 Token 鉴权机制。 + +## CDN 如何加速动态资源? + +传统的 CDN 主要针对静态资源(如图片、CSS、JS)进行缓存加速,而对于**动态资源**(如 API 接口、实时查询、支付请求、`.jsp`/`.asp`/`.php` 等动态页面),内容实时变化无法缓存,传统 CDN 往往直接回源,加速效果有限。 + +**动态加速(Dynamic Content Acceleration)** 正是为了解决这一问题而设计。它不缓存内容,而是通过智能路由、协议优化等技术,提升动态请求的传输速度和稳定性。 + +动态加速主要通过以下三种技术手段实现: + +1. **智能路由选路(最优链路探测)**:动态请求从用户端发出后,先到达离用户最近的 CDN 边缘节点。CDN 内部通过**实时网络监测技术**,探测全网链路质量(包括延迟、丢包率、带宽负载),避开公网中的拥堵或质量较差的节点,选择一条最优的传输路径到达源站。 + +2. **传输协议优化**: + + - **TCP 优化**:优化 TCP 慢启动、拥塞控制算法,在高延迟或丢包环境下提升传输效率。 + - **连接复用**:边缘节点与源站之间保持长连接(Keep-Alive),减少频繁握手带来的延迟。 + +3. **动静态混合加速**:现代 CDN(如阿里云 DCDN、腾讯云 ECDN)能够自动识别用户请求的资源类型: + - **静态资源**:直接从边缘节点缓存返回。 + - **动态资源**:通过智能路由回源获取。 + +> **一句话总结**:动态加速 = 智能探测 + 动态选路 + 协议优化,让动态请求跑得又快又稳。 + +## CDN 如何优化 HTTPS 访问速度? + +HTTPS 虽然安全,但 TLS 握手和加解密过程会增加延迟。CDN 通过多种技术手段对 HTTPS 进行加速优化,在保障安全的同时提升访问速度。 + +| 优化技术 | 原理说明 | 效果 | +| ----------------- | -------------------------------------------------------------------------------------- | ------------------------------ | +| **会话复用** | 用户首次建立 HTTPS 连接后,节点缓存会话信息;再次访问时复用会话参数,减少完整 TLS 握手 | 减少握手延迟 | +| **OCSP Stapling** | 由 CDN 节点定期缓存证书状态,在 TLS 握手时一并发给浏览器,避免浏览器单独查询 CA 机构 | 提升握手效率 | +| **False Start** | 在 TLS 握手尚未完全完成时就开始传输加密数据 | 减少一个 RTT 开销 | +| **HTTP/2** | 支持多路复用、头部压缩 | 减少连接数和传输延迟 | +| **QUIC** | 基于 UDP 的传输协议,0-RTT 建立连接 | 减少连接建立时间,改善弱网体验 | + +**CDN 证书托管的优势**: + +CDN 服务商(如腾讯云、阿里云)通常提供**免费 SSL 证书**和**自动续期**服务,具有以下优势: + +- **免运维**:用户无需手动更新证书,避免因证书过期导致的访问失败。 +- **灵活配置**:支持在 CDN 控制台上传证书,或一键申请免费证书。 +- **多种加密模式**:可选择”**半程加密**”(用户到 CDN 为 HTTPS,CDN 到源站为 HTTP)或”**全程加密**”(两端均为 HTTPS)。 + +**HTTPS 加速的配置建议**: + +1. **基础配置**:在 CDN 控制台开启 HTTPS,并配置证书。 +2. **性能优化**:开启 **OCSP Stapling** 和 **HTTP/2**。 +3. **安全增强**:如需更高安全等级,可开启 **HSTS**(强制浏览器使用 HTTPS 访问)。 +4. **弱网优化**:开启 **QUIC** 协议支持,改善移动端弱网环境下的访问体验。 ## 总结 -- CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻服务器以及带宽的负担。 -- 基于成本、稳定性和易用性考虑,建议直接选择专业的云厂商(比如阿里云、腾讯云、华为云、青云)或者 CDN 厂商(比如网宿、蓝汛)提供的开箱即用的 CDN 服务。 -- GSLB (Global Server Load Balance,全局负载均衡)是 CDN 的大脑,负责多个 CDN 节点之间相互协作,最常用的是基于 DNS 的 GSLB。CDN 会通过 GSLB 找到最合适的 CDN 节点。 -- 为了防止静态资源被盗用,我们可以利用 **Referer 防盗链** + **时间戳防盗链** 。 +- **CDN 的核心价值**:将静态资源分发到多个不同的地方以实现**就近访问**,加快静态资源的访问速度,减轻源站服务器及带宽的负担。 +- **CDN 服务选型**:基于成本、稳定性和易用性考虑,建议直接选择专业的云厂商(如阿里云、腾讯云、华为云)或 CDN 厂商(如网宿、蓝汛)提供的开箱即用服务。 +- **GSLB 的作用**:GSLB(全局负载均衡)是 CDN 的大脑,负责根据用户位置、节点状态等因素,将用户请求调度到**最优的 CDN 节点**。 +- **核心指标**:**命中率**越高越好,**回源率**越低越好。 +- **防盗链机制**:推荐采用 **Referer 防盗链 + 时间戳防盗链**的组合方案,平衡安全性与实现成本。 +- **动态加速**:通过**智能路由选路**、**传输协议优化**、**动静态混合加速**三种技术手段,提升动态请求(API 接口、实时查询等)的传输速度和稳定性。 +- **HTTPS 加速**:通过**会话复用**、**OCSP Stapling**、**False Start**、**HTTP/2**、**QUIC** 等技术优化 TLS 握手和传输过程,在保障安全的同时提升访问速度。 ## 参考 diff --git a/docs/high-performance/data-cold-hot-separation.md b/docs/high-performance/data-cold-hot-separation.md index d7ae70c2bfd..3cb7dedef1a 100644 --- a/docs/high-performance/data-cold-hot-separation.md +++ b/docs/high-performance/data-cold-hot-separation.md @@ -1,68 +1,325 @@ --- title: 数据冷热分离详解 +description: 本文详解数据冷热分离的核心原理与实践方案,涵盖冷热数据判定策略、多级分层设计、数据迁移一致性保障、冷数据查询优化、存储选型(HBase/TiDB/对象存储),以及订单/日志/内容系统的典型落地案例。 category: 高性能 head: - - meta - name: keywords - content: 数据冷热分离,冷数据迁移,冷数据存储 - - - meta - - name: description - content: 数据冷热分离是指根据数据的访问频率和业务重要性,将数据分为冷数据和热数据,冷数据一般存储在存储在低成本、低性能的介质中,热数据高性能存储介质中。 + content: 数据冷热分离,冷数据迁移,冷数据存储,分层存储,TiDB冷热分离,HBase,数据归档,存储成本优化,数据一致性 --- + + ## 什么是数据冷热分离? -数据冷热分离是指根据数据的访问频率和业务重要性,将数据分为冷数据和热数据,冷数据一般存储在存储在低成本、低性能的介质中,热数据高性能存储介质中。 +数据冷热分离是指根据数据的**访问频率**和**业务重要性**,将数据划分为冷数据和热数据,并分别存储在不同性能和成本的存储介质中的架构策略。 + +这种架构的核心目标有三个: + +1. **提升查询性能**:热数据存储在高性能介质(如 SSD、内存)中,保障核心业务的响应速度。 +2. **降低存储成本**:冷数据迁移至低成本介质(如 HDD、对象存储),大幅削减存储开支。 +3. **满足合规要求**:部分行业(如金融、医疗)要求数据长期归档,冷热分离可兼顾合规与成本。 ### 冷数据和热数据 -热数据是指经常被访问和修改且需要快速访问的数据,冷数据是指不经常访问,对当前项目价值较低,但需要长期保存的数据。 +**热数据**是指被频繁访问和修改、且需要快速响应的数据;**冷数据**是指访问频率极低、对当前业务价值较小、但需要长期保留的数据。 + +冷热数据的区分方法主要有两种: + +1. **时间维度区分**:按照数据的创建时间、更新时间或过期时间划分。例如,订单系统将一段时间前(如 90 天或 1 年)的订单数据标记为冷数据。该方法适用于**数据访问频率与时间强相关**的场景,实现简单、成本低。 +2. **访问频率区分**:将高频访问的数据视为热数据,低频访问的数据视为冷数据。例如,内容系统将**浏览量低于阈值**的文章标记为冷数据。该方法需要额外记录访问频率,适用于**访问频率与数据本身特性强相关**的场景。 + +**如何选择区分策略?** + +- 若业务数据天然具有时效性(如订单、日志、账单),优先选择**时间维度**,实现成本最低。 +- 若数据价值与时间无关(如文章、商品、用户画像),需结合**访问频率**进行判定。 +- 实际项目中,可将两者结合使用:以时间维度为主、访问频率为辅,覆盖更多业务场景。 + +### 冷热分离的多级分层策略 + +实际落地时,"冷"与"热"往往不是非此即彼的二分法,而是**渐进式多级分层**: + +| 层级 | 数据特性 | 判定规则示例 | 存储策略 | +| ------------ | -------------------- | --------------------------- | ---------------------- | +| **热数据** | 高频访问、实时响应 | 最近 30 天 + 所有未完成订单 | MySQL 热库(SSD) | +| **温数据** | 中频访问、可能被查询 | 30~90 天前的订单 | MySQL 温库(HDD) | +| **冷数据** | 低频访问、偶发查询 | 90 天~3 年的历史订单 | 独立冷库或对象存储 | +| **归档数据** | 极少访问、仅合规留存 | 超过 3 年的订单 | 对象存储(仅保留汇总) | -冷热数据到底如何区分呢?有两个常见的区分方法: +**实践建议**:判定规则应通过**配置中心**动态管理,避免因业务变化导致频繁修改代码。 -1. **时间维度区分**:按照数据的创建时间、更新时间、过期时间等,将一定时间段内的数据视为热数据,超过该时间段的数据视为冷数据。例如,订单系统可以将 1 年前的订单数据作为冷数据,1 年内的订单数据作为热数据。这种方法适用于数据的访问频率和时间有较强的相关性的场景。 -2. **访问频率区分**:将高频访问的数据视为热数据,低频访问的数据视为冷数据。例如,内容系统可以将浏览量非常低的文章作为冷数据,浏览量较高的文章作为热数据。这种方法需要记录数据的访问频率,成本较高,适合访问频率和数据本身有较强的相关性的场景。 +### 冷数据被访问后如何处理? -几年前的数据并不一定都是冷数据,例如一些优质文章发表几年后依然有很多人访问,大部分普通用户新发表的文章却基本没什么人访问。 +如果冷数据突然被访问(如用户查询 3 年前的订单),是否需要"热升级"? -这两种区分冷热数据的方法各有优劣,实际项目中,可以将两者结合使用。 +| 策略 | 适用场景 | 优点 | 缺点 | +| ------------ | ---------------------- | -------------------- | ---------------------------- | +| **不回迁** | 偶发查询、查询频率极低 | 实现简单 | 查询速度慢 | +| **缓存层** | 中等频率查询 | 加速查询、不改变存储 | 需要额外缓存组件 | +| **异步回迁** | 高频查询、需要持续访问 | 彻底解决性能问题 | 实现复杂、可能产生一致性问题 | + +**推荐做法**:绝大多数场景采用"**不回迁 + 缓存层**"的组合方案。冷数据查询时,先查缓存,命中则直接返回;未命中则查冷库并将结果写入缓存(针对偶发查询,设置 5~15 分钟的短暂 TTL 即可)。 + +**⚠️注意**:为防止恶意攻击者利用随机参数频繁查询不存在的数据导致冷库被击穿,可以在缓存层前置**布隆过滤器(Bloom Filter)**或在缓存中设置**空值占位符**,避免恶意请求穿透到冷库。详细介绍参考 [Redis 常见面试题总结(下)](https://javaguide.cn/database/redis/redis-questions-02.html)(Redis 事务、性能优化、生产问题、集群、使用规范等)。 ### 冷热分离的思想 -冷热分离的思想非常简单,就是对数据进行分类,然后分开存储。冷热分离的思想可以应用到很多领域和场景中,而不仅仅是数据存储,例如: +冷热分离的核心思想是**分层存储(Tiered Storage)**,根据数据的访问特性将其分配到不同层级的存储介质中。在企业级存储架构中,通常划分为以下层级: + +| 层级 | 数据特性 | 典型存储介质 | 访问延迟 | +| --------------------- | ------------------ | -------------------- | ----------- | +| **Hot(热层)** | 高频访问、实时响应 | NVMe SSD、内存 | 毫秒级 | +| **Warm(温层)** | 中频访问、近期数据 | SATA SSD、高速 HDD | 百毫秒级 | +| **Cold(冷层)** | 低频访问、历史数据 | 大容量 HDD、对象存储 | 秒级 | +| **Archive(归档层)** | 极少访问、合规留存 | 磁带库、冰川存储 | 分钟~小时级 | -- 邮件系统中,可以将近期的比较重要的邮件放在收件箱,将比较久远的不太重要的邮件存入归档。 -- 日常生活中,可以将常用的物品放在显眼的位置,不常用的物品放入储藏室或者阁楼。 -- 图书馆中,可以将最受欢迎和最常借阅的图书单独放在一个显眼的区域,将较少借阅的书籍放在不起眼的位置。 -- …… +这种分层思想在 IT 基础设施中被广泛应用,不仅限于数据库,还包括文件系统、对象存储、CDN 缓存等场景。 ### 数据冷热分离的优缺点 -- 优点:热数据的查询性能得到优化(用户的绝大部分操作体验会更好)、节约成本(可以冷热数据的不同存储需求,选择对应的数据库类型和硬件配置,比如将热数据放在 SSD 上,将冷数据放在 HDD 上) -- 缺点:系统复杂性和风险增加(需要分离冷热数据,数据错误的风险增加)、统计效率低(统计的时候可能需要用到冷库的数据)。 +**优点:** + +- **热数据查询性能优化**:热数据集中在高性能存储上,表数据量大幅减少,索引效率显著提升,用户的绝大部分操作体验会更好。 +- **存储成本大幅降低**:冷数据可迁移至 HDD 或对象存储,**SSD 与 HDD 的单位成本差距可达 5~10 倍**,对于海量数据场景节省效果显著。 +- **系统可维护性增强**:热库数据量可控,备份恢复速度更快,DDL 操作(如加索引)耗时更短。 + +**缺点:** + +- **系统复杂性增加**:需要额外的迁移组件、路由逻辑和监控体系,数据一致性风险增加。 +- **跨库查询效率低**:若业务需要同时查询冷热数据(如年度统计报表),需进行跨库关联或数据聚合,查询性能和开发成本均会上升。 +- **迁移策略维护成本**:冷热数据的判定规则需要持续调优,避免误判导致热数据被错误迁移。 + +## 冷数据迁移 + +### 冷数据如何迁移? + +冷数据迁移是冷热分离的核心环节,主流方案有以下三种: + +| 方案 | 实现原理 | 优点 | 缺点 | 适用场景 | +| ------------------- | ---------------------------------------- | ---------------------- | -------------------------------------------- | ---------------------------- | +| **业务层代码实现** | 写操作时判断冷热,直接路由到对应库 | 实时性高 | 侵入业务代码、判定逻辑复杂 | 几乎不使用 | +| **任务调度迁移** | 定时任务扫描热库,批量迁移符合条件的数据 | 实现简单 | 存在迁移延迟、扫表可能污染 Buffer Pool | 时间维度区分场景 | +| **Binlog 监听迁移** | 监听数据库变更日志,实时或准实时迁移 | 实时性好、对业务无侵入 | 需要额外组件(如 Canal)、不适合时间维度判定 | **访问频率区分场景(推荐)** | -## 冷数据如何迁移? +**任务调度迁移**是最常用的方案,可借助 XXL-Job、Elastic-Job 等分布式任务调度平台实现。关于任务调度的方案,我也写过文章详细介绍,可以查看这篇文章:[Java 定时任务详解](https://javaguide.cn/system-design/schedule-task.html) 。 -冷数据迁移方案: +> ⚠️ **风险提示**:任务调度迁移在大数据量下存在性能隐患。大范围的扫表操作(如 `SELECT * FROM orders WHERE create_time < 'xxx' LIMIT 10000`)会严重污染 InnoDB Buffer Pool,将真正的业务热数据挤出内存。**生产环境建议**: +> +> - 使用**基于主键的范围查询**,避免全表扫描; +> - 控制**单次迁移批量大小**,分批执行; +> - 在**业务低峰期**执行迁移任务; +> - 对于海量数据,优先考虑 **Binlog 监听**方案,将对热库的冲击降到最低。 -1. 业务层代码实现:当有对数据进行写操作时,触发冷热分离的逻辑,判断数据是冷数据还是热数据,冷数据就入冷库,热数据就入热库。这种方案会影响性能且冷热数据的判断逻辑不太好确定,还需要修改业务层代码,因此一般不会使用。 -2. 任务调度:可以利用 xxl-job 或者其他分布式任务调度平台定时去扫描数据库,找出满足冷数据条件的数据,然后批量地将其复制到冷库中,并从热库中删除。这种方法修改的代码非常少,非常适合按照时间区分冷热数据的场景。 -3. 监听数据库的变更日志 binlog :将满足冷数据条件的数据从 binlog 中提取出来,然后复制到冷库中,并从热库中删除。这种方法可以不用修改代码,但不适合按照时间维度区分冷热数据的场景。 +典型流程如下: -如果你的公司有 DBA 的话,也可以让 DBA 进行冷数据的人工迁移,一次迁移完成冷数据到冷库。然后,再搭配上面介绍的方案实现后续冷数据的迁移工作。 +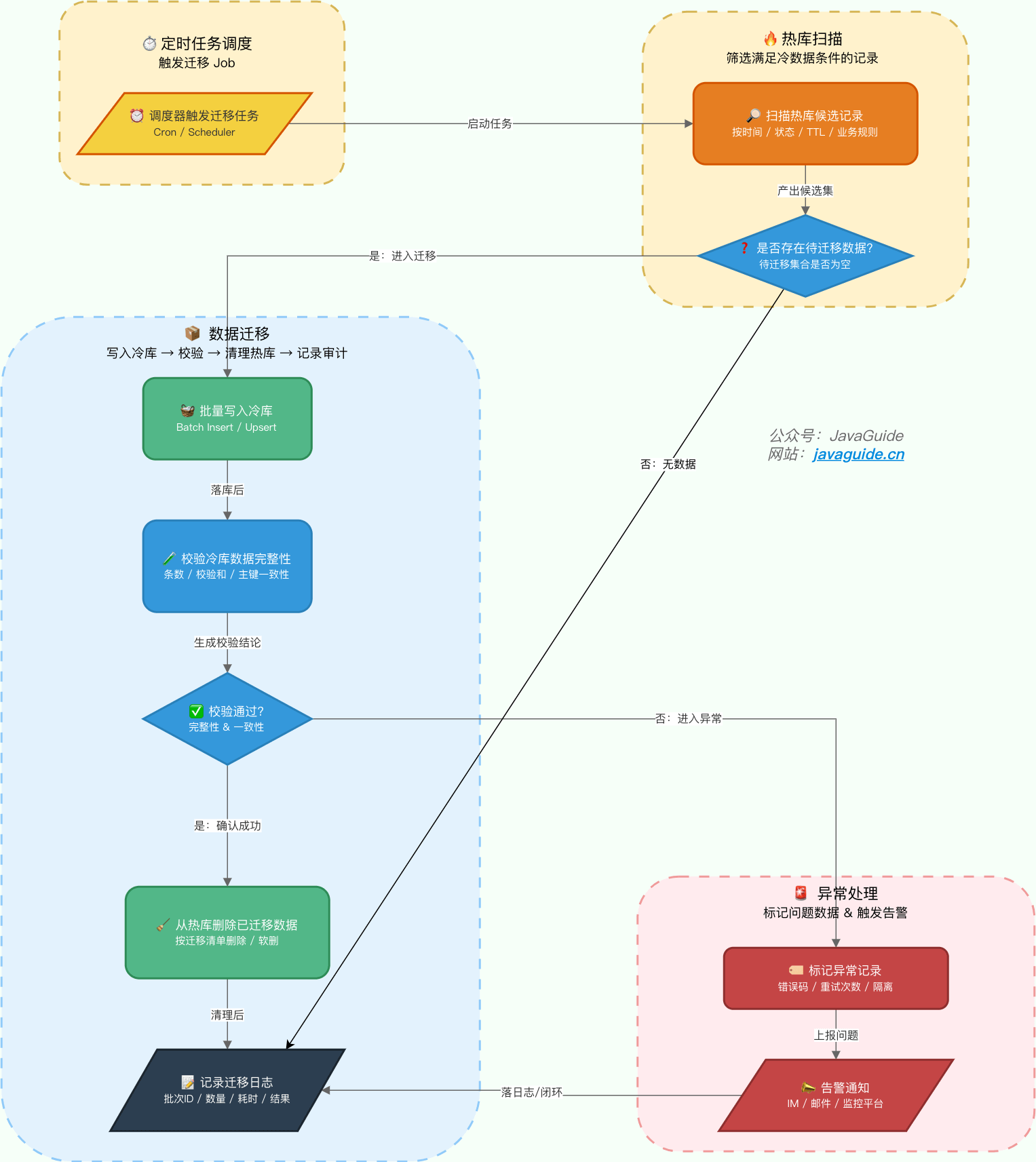 + +**实践建议**:若公司有 DBA 支持,可先进行一次**存量冷数据的人工迁移**,将历史数据批量导入冷库;后续再通过任务调度实现**增量迁移**的自动化。 + +### 迁移过程中如何保证数据一致性? + +数据迁移过程中,最棘手的问题是:**如果数据在迁移过程中被更新,如何处理?** + +#### 常见解决方案 + +| 方案 | 实现方式 | 优点 | 缺点 | +| ------------------- | -------------------------------------- | ---------------- | ------------------------------------ | +| **迁移前锁定** | 迁移前对记录加写锁,迁移完成后释放 | 一致性强 | 影响业务写入、吞吐量下降 | +| **版本号乐观锁** | 迁移时记录版本,删除前校验版本是否变化 | 无锁、性能好 | 需要业务表增加版本字段、冲突时需重试 | +| **状态标记 + 幂等** | 热库增加迁移状态字段,先标记再迁移 | 可追溯、支持回滚 | 需要改造业务表 | + +> **注意**:冷热库通常是**不同的数据库实例**,`INSERT`(冷库)和 `DELETE`(热库)无法放在同一个本地事务中,需要特殊处理跨库原子性问题。 + +#### 推荐方案:状态标记 + 幂等迁移 + +在热库表中增加 `migrate_status` 字段,通过状态机保证迁移的原子性和可追溯性: + +```sql +-- 1. 热库表增加迁移状态字段 +ALTER TABLE orders ADD COLUMN migrate_status TINYINT DEFAULT 0 + COMMENT '0-未迁移 1-迁移中 2-已迁移'; +``` + +```java +// 2. 迁移流程(伪代码,独立冷库场景需在应用层分步执行) + +// Step 1: 标记为迁移中(热库事务) +hotDb.execute("UPDATE orders SET migrate_status = 1 WHERE id = ? AND migrate_status = 0", id); + +// Step 2: 读取热库数据并写入冷库(需切换数据库连接) +Order order = hotDb.query("SELECT * FROM orders WHERE id = ?", id); +coldDb.execute("INSERT IGNORE INTO orders_cold VALUES (?, ?, ...)", order.id, order.data...); + +// Step 3: 标记为已迁移(热库事务) +hotDb.execute("UPDATE orders SET migrate_status = 2 WHERE id = ? AND migrate_status = 1", id); + +// Step 4: 延迟删除热库数据(可选,确认冷库数据无误后执行) +hotDb.execute("DELETE FROM orders WHERE id = ? AND migrate_status = 2", id); +``` + +> **注意**:独立冷库场景下,标准 MySQL 无法直接执行跨库 `INSERT ... SELECT`,必须在应用层拆分为"读取热库 → 写入冷库"两步。 + +**方案优势**: + +- **幂等性**:`INSERT IGNORE` 保证冷库写入幂等,`migrate_status` 状态流转保证热库更新幂等。 +- **可追溯**:通过状态字段可以查询迁移进度,异常时可以人工介入。 +- **可回滚**:迁移失败时可以将状态重置为 0,重新迁移。 +- **渐进式删除**:不立即删除热库数据,确认冷库无误后再清理,降低风险。 + +> **空间回收**:InnoDB 执行 `DELETE` 后仅将数据页标记为删除,物理空间不会立即释放给操作系统。需在**业务低峰期**执行 `OPTIMIZE TABLE` 或 `ALTER TABLE ENGINE=InnoDB` 重建表,才能真正回收磁盘空间。 + +**兜底机制**: + +- **定时对账**:定期扫描 `migrate_status = 1` 超过阈值的记录,自动重置或告警。**注意**:`migrate_status` 字段区分度极低,必须配合联合索引(如 `idx_create_time_migrate_status`)限定扫描区间,避免全表扫描。 +- **高频更新兜底**:对于因频繁更新导致多次跳过的记录,设置最大重试次数,超过后强制迁移或人工介入。 ## 冷数据如何存储? -冷数据的存储要求主要是容量大,成本低,可靠性高,访问速度可以适当牺牲。 +冷数据存储方案的选型原则是:**容量大、成本低、可靠性高,访问速度可适当牺牲**。 + +### 中小厂方案 -冷数据存储方案: +直接使用 **MySQL/PostgreSQL** 即可,保持与热库相同的数据库类型,降低运维复杂度。具体实现方式: -- 中小厂:直接使用 MySQL/PostgreSQL 即可(不改变数据库选型和项目当前使用的数据库保持一致),比如新增一张表来存储某个业务的冷数据或者使用单独的冷库来存放冷数据(涉及跨库查询,增加了系统复杂性和维护难度) -- 大厂:Hbase(常用)、RocksDB、Doris、Cassandra +- **同库分表**:在同一数据库中新增冷数据表(如 `order_history`),通过表名区分冷热数据。 +- **独立冷库**:部署单独的数据库实例作为冷库,热库与冷库通过应用层路由访问。 -如果公司成本预算足的话,也可以直接上 TiDB 这种分布式关系型数据库,直接一步到位。TiDB 6.0 正式支持数据冷热存储分离,可以降低 SSD 使用成本。使用 TiDB 6.0 的数据放置功能,可以在同一个集群实现海量数据的冷热存储,将新的热数据存入 SSD,历史冷数据存入 HDD。 +**⚠️注意**:独立冷库方案涉及**跨库查询**,若业务存在冷热数据联合查询需求,需评估是否引入数据同步或聚合层。 + +### 大厂方案 + +大厂通常采用专门针对海量数据优化的存储引擎: + +| 存储方案 | 特点 | 适用场景 | +| ---------------------- | -------------------------------- | -------------------------------- | +| **HBase** | 列族存储、高吞吐、支持 PB 级数据 | 日志、用户行为、IoT 数据归档 | +| **RocksDB** | 高性能 KV 存储、LSM-Tree 结构 | 嵌入式场景、作为其他系统底层存储 | +| **Doris/ClickHouse** | OLAP 引擎、支持实时分析 | 冷数据需要进行聚合分析的场景 | +| **Cassandra** | 分布式、高可用、无单点故障 | 跨地域部署、高可用要求的归档场景 | +| **对象存储(OSS/S3)** | 成本极低、无限扩展 | 超大规模冷数据、合规归档 | + +### TiDB 方案(推荐) + +如果公司技术栈允许,可以直接使用 **TiDB** 这类分布式关系型数据库,原生支持冷热分离,一步到位。 + +TiDB 6.0 引入了 **基于 SQL 接口的数据放置框架(Placement Rules in SQL)** 功能,用于通过 SQL 接口配置数据在 TiKV 集群中的放置位置。 + +- **热数据**:通过 Placement Rules 指定存储在 **SSD 节点**上,保障查询性能。 +- **冷数据**:指定存储在 **HDD 节点**上,降低存储成本。 + +```sql +-- 创建放置策略:热数据存储在 SSD 节点 +CREATE PLACEMENT POLICY hot_data + CONSTRAINTS="[+disk=ssd]"; + +-- 创建放置策略:冷数据存储在 HDD 节点 +CREATE PLACEMENT POLICY cold_data + CONSTRAINTS="[+disk=hdd]"; + +-- 对表或分区应用放置策略 +ALTER TABLE orders PLACEMENT POLICY = hot_data; +ALTER TABLE orders PARTITION p2022 PLACEMENT POLICY = cold_data; +``` + +这种方案的优势在于:**业务无需感知冷热分离逻辑**,数据路由由 TiDB 自动完成,大幅降低了应用层的复杂度。 + +> **完整实践**:`Placement Rules` 指定了数据存放的介质类型,但数据如何从"热分区"流转到"冷分区"仍需结合**分区表(Range Partitioning)**。按时间跨度创建分区,为历史分区绑定 HDD 放置策略,为当前活跃分区绑定 SSD 放置策略。随着时间推移,只需维护分区的创建与销毁,底层数据即可在不同介质间自然流转。 + +## 冷数据如何查询? + +冷数据虽然访问频率低,但一旦需要查询(如审计、对账、年度报表),如何保证查询效率? + +### 冷数据查询需求分析 + +首先需要明确:**业务是否真的需要查询冷数据?** + +- **不需要**:可将冷数据完全移出业务库,仅保留归档(如对象存储),需要时人工提取。 +- **需要**:需设计合理的查询方案,平衡性能与成本。 + +### 冷数据查询优化方案 + +| 优化手段 | 实现方式 | 适用场景 | +| -------------------- | --------------------------------------------------- | -------------- | +| **冷库独立只读实例** | 冷库部署只读副本,避免冷查询影响热库 | 高频冷查询场景 | +| **查询路由** | 应用层根据时间范围自动路由到热库或冷库 | 跨冷热查询场景 | +| **预聚合** | 定期对冷数据生成月度/季度报表,查询时直接查聚合结果 | 统计分析场景 | +| **列式存储** | 冷库采用 ClickHouse、Doris 等 OLAP 引擎 | 大规模分析查询 | + +**跨冷热查询的处理**: + +若查询范围同时涉及冷热数据(如"查询近 2 年的订单"),有两种处理方式: + +1. **拆分查询**:分别查询热库和冷库,应用层合并结果。 +2. **限制范围**:提示用户缩小查询范围,避免跨库查询。 + +> **防雪崩预警**:若业务包含**全局分页排序**(如 `ORDER BY create_time LIMIT 10000, 20`),应用层必须从冷热库各拉取 `10000 + 20` 条记录进行内存归并,偏移量较大时极易引发 **OOM**。**强制要求**: +> +> - 限制查询时间范围,避免大跨度跨库查询; +> - 或引流至底层同步的宽表(如 ClickHouse)进行计算; +> - 严禁在应用层执行大深度的归并分页。 + +### 应用层如何路由冷热数据? + +| 方案 | 实现方式 | 优点 | 缺点 | +| ------------ | ---------------------------------------- | ------------------ | ---------------------------- | +| **硬编码** | 代码中直接判断路由 | 实现简单 | 维护成本高、规则变更需改代码 | +| **配置中心** | 路由规则存入配置中心(如 Nacos、Apollo) | 动态调整、无需重启 | 需要额外组件支持 | +| **Proxy 层** | 引入 ShardingSphere、ProxySQL 等中间件 | 业务无感知 | 架构复杂度高 | + +**推荐做法**:中小规模采用**配置中心**方案,大规模采用**Proxy 层**方案。 + +> ⚠️ **风险提示**:引入 Proxy 层后,所有跨冷热库的聚合计算(如全局排序、`GROUP BY` 归并分页)都会压在 Proxy 节点的内存与 CPU 上。需严格限制此类操作的最大返回行数,否则极易导致 Proxy 节点 **OOM(内存溢出)**。 + +## 冷热分离 vs 数据归档 vs 分区表 + +这三个概念容易混淆,需要区分清楚: + +| 对比维度 | 冷热分离 | 数据归档 | 分区表 | +| ------------------ | -------------------------- | ---------------------- | -------------------------- | +| **数据是否可访问** | 冷数据仍在业务访问路径上 | 归档数据通常移出业务库 | 所有分区均可访问 | +| **存储介质** | 冷热数据可跨实例、跨存储 | 通常迁移到低成本存储 | 同一实例内 | +| **实现复杂度** | 中等 | 低 | 低 | +| **典型场景** | 订单、日志等有时效性的数据 | 合规留存、数据备份 | 单表数据量大但无需分离存储 | + +**分区表的局限性**:MySQL 分区表可以按时间分区,但所有分区仍在同一个实例中,**无法实现存储介质的分离**。如果目标是降低存储成本,分区表无法替代冷热分离。 + +## 典型业务场景 + +> **说明**:以下存储策略仅供参考,实际选型需结合数据量、查询需求、团队技术栈和成本预算综合考虑。 + +### 订单系统 + +| 阶段 | 数据范围 | 存储策略 | 说明 | +| -------- | ----------------------- | ------------------------------- | ---------------------------- | +| 热数据 | 最近 90 天 + 未完成订单 | MySQL 热库(SSD) | 高频访问,保障查询性能 | +| 冷数据 | 90 天~3 年 | MySQL 冷库(HDD)或 TiDB | 可能需要查询,保持关系型存储 | +| 归档数据 | 超过 3 年 | 对象存储 / HBase / 仅保留汇总表 | 极少查询,优先考虑成本 | + +### 日志系统 + +| 阶段 | 数据范围 | 存储策略 | 说明 | +| ------ | --------- | ------------------------------------------------------ | ----------------------------------------- | +| 热数据 | 近 7 天 | Elasticsearch 热节点 | 实时检索、高频查询 | +| 温数据 | 7~30 天 | Elasticsearch 温节点 | 偶发查询,降低存储成本 | +| 冷数据 | 30 天以上 | Elasticsearch 冷节点 / 压缩归档至对象存储 / ClickHouse | 根据查询需求选择,ClickHouse 适合分析场景 | + +### 内容系统 + +| 阶段 | 数据范围 | 存储策略 | 说明 | +| ------ | -------------------------- | ----------------------------- | ------------------------------ | +| 热数据 | 发布后 3 个月内 + 高阅读量 | MySQL 热库 | 频繁被访问 | +| 冷数据 | 3 个月后 + 低阅读量 | MySQL 冷库 / HBase / 对象存储 | 访问频率低,可迁移至低成本存储 | + +**选型建议**: + +- **需要支持事务或复杂查询**:优先选择 MySQL 冷库或 TiDB +- **需要大规模聚合分析**:优先选择 ClickHouse 或 Doris +- **仅需偶尔查询明细**:可选择对象存储(如 OSS/S3),查询时临时加载 +- **数据量极大且访问极低**:HBase 或对象存储是性价比最高的选择 ## 案例分享 - [如何快速优化几千万数据量的订单表 - 程序员济癫 - 2023](https://www.cnblogs.com/fulongyuanjushi/p/17910420.html) - [海量数据冷热分离方案与实践 - 字节跳动技术团队 - 2022](https://mp.weixin.qq.com/s/ZKRkZP6rLHuTE1wvnqmAPQ) + + diff --git a/docs/high-performance/deep-pagination-optimization.md b/docs/high-performance/deep-pagination-optimization.md index 28826da755a..4288e67bc88 100644 --- a/docs/high-performance/deep-pagination-optimization.md +++ b/docs/high-performance/deep-pagination-optimization.md @@ -1,16 +1,16 @@ --- title: 深度分页介绍及优化建议 +description: 深度分页是指查询偏移量过大导致性能下降的场景,本文详解深度分页产生的原因及四种优化方案:范围查询、子查询优化、INNER JOIN 延迟关联、覆盖索引,并分析各方案的适用场景与优缺点。 category: 高性能 head: - - meta - name: keywords - content: 深度分页 - - - meta - - name: description - content: 查询偏移量过大的场景我们称为深度分页,这会导致查询性能较低。深度分页可以采用范围查询、子查询、INNER JOIN 延迟关联、覆盖索引等方法进行优化。 + content: 深度分页,分页优化,LIMIT优化,MySQL分页,延迟关联,覆盖索引,游标分页 --- -## 深度分页介绍 + + +## 什么是深度分页?怎么导致的? 查询偏移量过大的场景我们称为深度分页,这会导致查询性能较低,例如: @@ -19,9 +19,9 @@ head: SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10 ``` -## 深度分页问题的原因 +当查询偏移量过大时,MySQL 的查询优化器可能会选择全表扫描而不是利用索引来优化查询。 -当查询偏移量过大时,MySQL 的查询优化器可能会选择全表扫描而不是利用索引来优化查询。这是因为扫描索引和跳过大量记录可能比直接全表扫描更耗费资源。 +**深度分页变慢的根本原因**在于 MySQL 的执行机制:对于 `LIMIT offset, N`,MySQL 并非直接跳到 `offset` 处,而是必须从头扫描 `offset + N` 条记录。如果查询依赖二级索引且不满足覆盖索引,这意味着 MySQL 需要对前 `offset` 条记录执行毫无意义的**回表查询(产生海量的随机 I/O)**,最后再将这些辛苦查出的数据丢弃。即便优化器最终因代价过高退化为全表扫描,顺序扫描百万行的成本依然巨大。  @@ -33,24 +33,26 @@ MySQL 的查询优化器采用基于成本的策略来选择最优的查询执 ## 深度分页优化建议 -这里以 MySQL 数据库为例介绍一下如何优化深度分页。 +> **本文基于 MySQL 8.0 + InnoDB 存储引擎**,不同版本优化器行为可能存在差异。 -### 范围查询 +### 范围查询(游标分页) -当可以保证 ID 的连续性时,根据 ID 范围进行分页是比较好的解决方案: +通过记录上一页最后一条记录的 ID,使用 `WHERE id > last_id LIMIT n` 获取下一页数据: ```sql -# 查询指定 ID 范围的数据 -SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id -# 也可以通过记录上次查询结果的最后一条记录的ID进行下一页的查询: -SELECT * FROM t_order WHERE id > 100000 LIMIT 10 +# 通过记录上次查询结果的最后一条记录的 ID 进行下一页的查询 +SELECT * FROM t_order WHERE id > 100000 ORDER BY id LIMIT 10 ``` -这种基于 ID 范围的深度分页优化方式存在很大限制: +**游标分页的核心优势**:**不依赖 ID 的连续性**。MySQL 只需要在 B+ 树上定位到 `last_id` 的位置,然后顺序向后读取 `n` 条记录即可,中间是否有断层(如 ID 被删除)完全不影响结果的准确性和性能。 -1. **ID 连续性要求高**: 实际项目中,数据库自增 ID 往往因为各种原因(例如删除数据、事务回滚等)导致 ID 不连续,难以保证连续性。 -2. **排序问题**: 如果查询需要按照其他字段(例如创建时间、更新时间等)排序,而不是按照 ID 排序,那么这种方法就不再适用。 -3. **并发场景**: 在高并发场景下,单纯依赖记录上次查询的最后一条记录的 ID 进行分页,容易出现数据重复或遗漏的问题。 +这种方式的限制: + +1. **不支持跳页**:无法直接跳转到第 N 页,只能逐页向后(或向前)翻页。 +2. **排序字段受限**:如果查询需要按照其他字段(如创建时间)排序而非 ID 排序,需使用联合游标 `(sort_field, id)` 保证唯一性和顺序。 +3. **并发场景**:当分页查询期间有新数据插入或删除时,可能出现: + - **数据遗漏**:查询第二页时,有新数据插入到第一页范围内,导致该数据被"挤"到第二页,但第二页查询已基于旧的最后 ID 跳过它。 + - **数据重复**:查询第二页时,第一页末尾有数据被删除,原第二页的第一条数据"升"到第一页末尾,导致第二页查询再次返回它。 ### 子查询 @@ -64,15 +66,20 @@ SELECT * FROM t_order WHERE id > 100000 LIMIT 10 ```sql -- 先通过子查询在主键索引上进行偏移,快速找到起始ID -SELECT * FROM t_order WHERE id >= (SELECT id FROM t_order LIMIT 1000000, 1) LIMIT 10; +SELECT * FROM t_order +WHERE id >= ( + SELECT id FROM t_order ORDER BY id LIMIT 1000000, 1 +) ORDER BY id LIMIT 10; ``` **工作原理**: -1. 子查询 `(SELECT id FROM t_order where id > 1000000 limit 1)` 会利用主键索引快速定位到第 1000001 条记录,并返回其 ID 值。 -2. 主查询 `SELECT * FROM t_order WHERE id >= ... LIMIT 10` 将子查询返回的起始 ID 作为过滤条件,使用 `id >=` 获取从该 ID 开始的后续 10 条记录。 +1. 子查询 `(SELECT id FROM t_order ORDER BY id LIMIT 1000000, 1)` 利用主键索引扫描并跳过前 1000000 条记录,返回第 1000001 条记录的主键值。 +2. 主查询 `SELECT * FROM t_order WHERE id >= ... ORDER BY id LIMIT 10` 以该主键为起点,获取后续 10 条完整记录。 + +不过,某些情况下子查询可能会产生临时表,影响性能,因此在复杂查询中建议优先考虑延迟关联。 -不过,子查询的结果会产生一张新表,会影响性能,应该尽量避免大量使用子查询。并且,这种方法只适用于 ID 是正序的。在复杂分页场景,往往需要通过过滤条件,筛选到符合条件的 ID,此时的 ID 是离散且不连续的。 +> **复杂过滤场景**:在包含复杂过滤条件的分页场景中(如 `WHERE status = 1 ORDER BY id LIMIT 1000000, 10`),符合条件的 ID 往往是离散的。此时子查询的优势更加明显:通过在子查询中利用联合索引(如 `(status, id)`)实现覆盖索引扫描,可以高效地跳过前 100 万条符合条件的记录,定位到目标 ID 后,主查询只需回表 10 次。 当然,我们也可以利用子查询先去获取目标分页的 ID 集合,然后再根据 ID 集合获取内容,但这种写法非常繁琐,不如使用 INNER JOIN 延迟关联。 @@ -86,13 +93,14 @@ SELECT t1.* FROM t_order t1 INNER JOIN ( -- 这里的子查询可以利用覆盖索引,性能极高 - SELECT id FROM t_order LIMIT 1000000, 10 -) t2 ON t1.id = t2.id; + SELECT id FROM t_order ORDER BY id LIMIT 1000000, 10 +) t2 ON t1.id = t2.id +ORDER BY t1.id; ``` **工作原理**: -1. 子查询 `(SELECT id FROM t_order where id > 1000000 LIMIT 10)` 利用主键索引快速定位目标分页的 10 条记录的 ID。 +1. 子查询 `(SELECT id FROM t_order ORDER BY id LIMIT 1000000, 10)` 利用主键索引扫描并跳过前 1000000 条记录,返回目标分页的 10 条记录的 ID。 2. 通过 `INNER JOIN` 将子查询结果与主表 `t_order` 关联,获取完整的记录数据。 除了使用 INNER JOIN 之外,还可以使用逗号连接子查询。 @@ -100,8 +108,9 @@ INNER JOIN ( ```sql -- 使用逗号进行延迟关联 SELECT t1.* FROM t_order t1, -(SELECT id FROM t_order where id > 1000000 LIMIT 10) t2 -WHERE t1.id = t2.id; +(SELECT id FROM t_order ORDER BY id LIMIT 1000000, 10) t2 +WHERE t1.id = t2.id +ORDER BY t1.id; ``` **注意**: 虽然逗号连接子查询也能实现类似的效果,但为了代码可读性和可维护性,建议使用更规范的 `INNER JOIN` 语法。 @@ -112,11 +121,14 @@ WHERE t1.id = t2.id; **覆盖索引的好处:** -- **避免 InnoDB 表进行索引的二次查询,也就是回表操作:** InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。 -- **可以把随机 IO 变成顺序 IO 加快查询效率:** 由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。 +- **避免 InnoDB 表进行索引的二次查询,也就是回表操作**:InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。 +- **减少回表带来的随机 IO**:通过覆盖索引直接返回数据,避免了根据二级索引的主键值回表查询聚簇索引的随机 IO 操作。回表时每次按主键值查找聚簇索引,本质上是随机 IO。 + +假设建立了 `(code, type)` 联合索引,下面的查询即可使用覆盖索引: ```sql -# 如果只需要查询 id, code, type 这三列,可建立 code 和 type 的覆盖索引 +# 在 InnoDB 中,辅助索引天然包含主键 id +# 如果只需要查询 id, code, type 这三列,只需建立 (code, type) 的联合索引即可实现覆盖 SELECT id, code, type FROM t_order ORDER BY code LIMIT 1000000, 10; @@ -127,14 +139,45 @@ LIMIT 1000000, 10; - 当查询的结果集占表的总行数的很大一部分时,MySQL 查询优化器可能选择放弃使用索引,自动转换为全表扫描。 - 虽然可以使用 `FORCE INDEX` 强制查询优化器走索引,但这种方式可能会导致查询优化器无法选择更优的执行计划,效果并不总是理想。 +## 生产落地建议 + +### 监控与告警 + +- **慢查询监控**:监控慢查询日志中 `LIMIT` 偏移量过大的 SQL,及时发现问题。 +- **阈值告警**:设置 `long_query_time` 阈值捕获深度分页查询。 +- **执行计划检查**:使用 `EXPLAIN` 定期检查关键分页 SQL 的执行计划,确保优化器按预期使用索引。 + +### 常见误区 + +| 误区 | 事实 | +| --------------------------------- | ---------------------------------------------------- | +| 认为 `FORCE INDEX` 能解决所有问题 | 强制索引可能阻止优化器选择更优计划,应谨慎使用 | +| 认为覆盖索引适用于所有场景 | 字段过多时索引维护成本高,且大结果集仍可能走全表扫描 | +| 认为游标分页能解决所有问题 | 游标分页不支持跳页,且只能按特定字段顺序翻页 | + ## 总结 -本文总结了几种常见的深度分页优化方案: +深度分页问题的根本原因在于:当 `LIMIT` 的偏移量过大时,MySQL 需要扫描并跳过大量记录才能获取目标数据,查询优化器可能放弃索引而选择全表扫描。此时即使有索引,也无法避免大量的回表操作,导致查询性能急剧下降。 + +本文介绍了四种常见的深度分页优化方案,各方案的特点及适用场景对比如下: + +| 优化方案 | 核心思路 | 适用场景 | 限制 | +| ------------ | ------------------------------------------------------------------- | ------------------------------ | ------------------------------------------------ | +| **范围查询** | 记录上一页最后一条 ID,通过 `WHERE id > last_id LIMIT n` 获取下一页 | 按 ID 排序、允许游标式翻页 | 不支持跳页、非 ID 排序需使用联合游标 | +| **子查询** | 先通过子查询获取起始主键,再根据主键过滤 | 需要支持传统 OFFSET 翻页 | 子查询可能产生临时表、依赖排序字段的索引 | +| **延迟关联** | 用 `INNER JOIN` 将分页转移到主键索引,减少回表 | 大数据量分页、需要传统翻页逻辑 | SQL 相对复杂 | +| **覆盖索引** | 建立包含查询字段的联合索引,避免回表 | 查询字段固定、可建立合适索引 | 字段较多时索引维护成本高、大结果集可能走全表扫描 | + +**方案选择建议**: + +- **优先使用延迟关联**:对于大多数需要支持传统 `LIMIT offset, size` 翻页逻辑的场景,延迟关联是性能和可维护性较好的选择。 +- **考虑范围查询(游标分页)**:如果业务允许使用"下一页"式的游标翻页(如社交媒体 feed 流、无限滚动),范围查询性能最佳且稳定。 +- **覆盖索引作为补充**:当查询字段固定且数量不多时,可配合其他方案建立覆盖索引进一步优化。 + +**注意事项**: -1. **范围查询**: 基于 ID 连续性进行分页,通过记录上一页最后一条记录的 ID 来获取下一页数据。适合 ID 连续且按 ID 查询的场景,但在 ID 不连续或需要按其他字段排序时存在局限。 -2. **子查询**: 先通过子查询获取分页的起始主键值,再根据主键进行筛选分页。利用主键索引提高效率,但子查询会生成临时表,复杂场景下性能不佳。 -3. **延迟关联 (INNER JOIN)**: 使用 `INNER JOIN` 将分页操作转移到主键索引上,减少回表次数。相比子查询,延迟关联的性能更优,适合大数据量的分页查询。 -4. **覆盖索引**: 通过索引直接获取所需字段,避免回表操作,减少 IO 开销,适合查询特定字段的场景。但当结果集较大时,MySQL 可能会选择全表扫描。 +- 无论采用哪种方案,都应注意监控实际执行计划(`EXPLAIN`),确保优化器按预期使用索引。 +- 对于超深分页(如百万级偏移量),应从业务层面评估是否真的需要支持,考虑限制最大翻页数或采用其他检索方式(如搜索引擎)。 ## 参考 diff --git a/docs/high-performance/load-balancing.md b/docs/high-performance/load-balancing.md index 619df980574..a4d2082b2e8 100644 --- a/docs/high-performance/load-balancing.md +++ b/docs/high-performance/load-balancing.md @@ -1,15 +1,15 @@ --- title: 负载均衡原理及算法详解 +description: 本文详解负载均衡的核心原理,涵盖四层/七层负载均衡区别、服务端与客户端负载均衡对比,深入讲解轮询、加权轮询、随机、一致性哈希等常见负载均衡算法,以及 Nginx、LVS 等主流实现方案。 category: 高性能 head: - - meta - name: keywords - content: 客户端负载均衡,服务负载均衡,Nginx,负载均衡算法,七层负载均衡,DNS解析 - - - meta - - name: description - content: 负载均衡指的是将用户请求分摊到不同的服务器上处理,以提高系统整体的并发处理能力。负载均衡可以简单分为服务端负载均衡和客户端负载均衡 这两种。服务端负载均衡涉及到的知识点更多,工作中遇到的也比较多,因为,我会花更多时间来介绍。 + content: 负载均衡,四层负载均衡,七层负载均衡,Nginx负载均衡,LVS,负载均衡算法,轮询,一致性哈希,客户端负载均衡 --- + + ## 什么是负载均衡? **负载均衡** 指的是将用户请求分摊到不同的服务器上处理,以提高系统整体的并发处理能力以及可靠性。负载均衡服务可以有由专门的软件或者硬件来完成,一般情况下,硬件的性能更好,软件的价格更便宜(后文会详细介绍到)。 diff --git a/docs/high-performance/message-queue/disruptor-questions.md b/docs/high-performance/message-queue/disruptor-questions.md index eaa52b4fd6d..efd7f24be0b 100644 --- a/docs/high-performance/message-queue/disruptor-questions.md +++ b/docs/high-performance/message-queue/disruptor-questions.md @@ -1,8 +1,13 @@ --- title: Disruptor常见问题总结 +description: 本文总结 Disruptor 高性能内存队列的核心知识与面试要点,涵盖 Disruptor 架构(RingBuffer/Sequencer/WaitStrategy)、高性能原理(无锁设计/缓存行填充/预分配内存)、与 ArrayBlockingQueue 对比、生产者消费者模式等,助力 Disruptor 学习与面试。 category: 高性能 tag: - 消息队列 +head: + - - meta + - name: keywords + content: Disruptor,高性能队列,RingBuffer,无锁队列,缓存行填充,LMAX,内存队列,Disruptor面试 --- Disruptor 是一个相对冷门一些的知识点,不过,如果你的项目经历中用到了 Disruptor 的话,那面试中就很可能会被问到。 diff --git a/docs/high-performance/message-queue/kafka-questions-01.md b/docs/high-performance/message-queue/kafka-questions-01.md index 070858cc1f8..b8034f7c875 100644 --- a/docs/high-performance/message-queue/kafka-questions-01.md +++ b/docs/high-performance/message-queue/kafka-questions-01.md @@ -1,8 +1,13 @@ --- title: Kafka常见问题总结 +description: 本文总结 Kafka 常见面试题与核心知识点,涵盖 Kafka 架构(Broker/Topic/Partition/Consumer Group)、高性能原理(零拷贝/顺序写/批量处理)、消息可靠性(ACK机制/ISR副本)、消息顺序性、Rebalance 机制、Kafka 与 RocketMQ 对比等,助力 Kafka 学习与面试。 category: 高性能 tag: - 消息队列 +head: + - - meta + - name: keywords + content: Kafka,消息队列,Kafka分区,Kafka副本,ISR,消费者组,Rebalance,零拷贝,Kafka面试 --- ## Kafka 基础 diff --git a/docs/high-performance/message-queue/message-queue.md b/docs/high-performance/message-queue/message-queue.md index f34c8825da4..ea8a25c6613 100644 --- a/docs/high-performance/message-queue/message-queue.md +++ b/docs/high-performance/message-queue/message-queue.md @@ -1,8 +1,13 @@ --- title: 消息队列基础知识总结 +description: 本文系统总结消息队列的核心知识,涵盖消息队列的应用场景(异步处理/解耦/削峰)、消息模型(点对点/发布订阅)、如何保证消息不丢失、消息幂等性、消息顺序性、消息积压处理等常见问题,以及 Kafka、RocketMQ、RabbitMQ 技术选型对比。 category: 高性能 tag: - 消息队列 +head: + - - meta + - name: keywords + content: 消息队列,MQ,异步解耦,削峰填谷,消息丢失,消息幂等,消息顺序,Kafka,RocketMQ,RabbitMQ --- ::: tip diff --git a/docs/high-performance/message-queue/rabbitmq-questions.md b/docs/high-performance/message-queue/rabbitmq-questions.md index e971eaf3604..343e69e17b4 100644 --- a/docs/high-performance/message-queue/rabbitmq-questions.md +++ b/docs/high-performance/message-queue/rabbitmq-questions.md @@ -1,37 +1,35 @@ --- title: RabbitMQ常见问题总结 +description: 本文总结 RabbitMQ 常见面试题与核心知识点,涵盖 AMQP 协议、Exchange 交换机类型(Direct/Topic/Fanout)、消息确认机制、死信队列、延迟队列、优先级队列、高可用集群(镜像队列)等,助力 RabbitMQ 学习与面试准备。 category: 高性能 tag: - 消息队列 head: - - meta - name: keywords - content: RabbitMQ,AMQP,Broker,Exchange,优先级队列,延迟队列 - - - meta - - name: description - content: RabbitMQ 是一个在 AMQP(Advanced Message Queuing Protocol )基础上实现的,可复用的企业消息系统。它可以用于大型软件系统各个模块之间的高效通信,支持高并发,支持可扩展。它支持多种客户端如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX,持久化,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。 + content: RabbitMQ,AMQP协议,Exchange交换机,消息确认,死信队列,延迟队列,优先级队列,RabbitMQ集群,消息队列面试 --- -> 本篇文章由 JavaGuide 收集自网络,原出处不明。 +RabbitMQ 作为老牌消息中间件,凭借其成熟的路由机制、丰富的协议支持和完善的可靠性保障,在企业级应用中占据重要地位。但自 RabbitMQ 3.8 引入 Quorum Queue、3.9 引入 Streams、4.0 移除镜像队列以来,其技术架构发生了重大变化,许多传统的最佳实践已不再适用。 + +本文已针对 RabbitMQ 4.0 进行全面更新,明确标注各特性的版本依赖,特别强调了镜像队列(已移除)、Quorum Queue(推荐)和 Streams(3.9+)的选型差异。 ## RabbitMQ 是什么? RabbitMQ 是一个在 AMQP(Advanced Message Queuing Protocol )基础上实现的,可复用的企业消息系统。它可以用于大型软件系统各个模块之间的高效通信,支持高并发,支持可扩展。它支持多种客户端如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP 等,支持 AJAX,持久化,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。 -RabbitMQ 是使用 Erlang 编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正是如此,使的它变的非常重量级,更适合于企业级的开发。它同时实现了一个 Broker 构架,这意味着消息在发送给客户端时先在中心队列排队,对路由(Routing)、负载均衡(Load balance)或者数据持久化都有很好的支持。 +RabbitMQ 是使用 Erlang 编写的一个开源的消息队列,本身支持很多的协议:AMQP、XMPP、SMTP、STOMP,也正是如此,**使得它变得**非常重量级,更适合于企业级的开发。它同时实现了一个 Broker 构架,这意味着消息在发送给客户端时先在中心队列排队,对路由(Routing)、负载均衡(Load Balance)或者数据持久化都有很好的支持。 -PS:也可能直接问什么是消息队列?消息队列就是一个使用队列来通信的组件。 +## RabbitMQ 特点 -## RabbitMQ 特点? - -- **可靠性**: RabbitMQ 使用一些机制来保证可靠性, 如持久化、传输确认及发布确认等。 -- **灵活的路由** : 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能, RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个交换器绑定在一起, 也可以通过插件机制来实现自己的交换器。 -- **扩展性**: 多个 RabbitMQ 节点可以组成一个集群,也可以根据实际业务情况动态地扩展 集群中节点。 -- **高可用性** : 队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队 列仍然可用。 -- **多种协议**: RabbitMQ 除了原生支持 AMQP 协议,还支持 STOMP, MQTT 等多种消息 中间件协议。 -- **多语言客户端** :RabbitMQ 几乎支持所有常用语言,比如 Java、 Python、 Ruby、 PHP、 C#、 JavaScript 等。 -- **管理界面** : RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息、集 群中的节点等。 -- **插件机制** : RabbitMQ 提供了许多插件 , 以实现从多方面进行扩展,当然也可以编写自 己的插件。 +- **可靠性**:RabbitMQ 使用一些机制来保证可靠性,如持久化、传输确认及发布确认等。 +- **灵活的路由**:在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能,RabbitMQ **已经**提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个交换器绑定在一起,也可以通过插件机制来实现自己的交换器。 +- **扩展性**:多个 RabbitMQ 节点可以组成一个集群,也可以根据实际业务情况动态地扩展集群中的节点。 +- **高可用性**:Quorum Queue 基于 Raft 协议实现数据复制,Streams 支持多节点副本,在部分节点出现问题的情况下队列仍然可用。 +- **多种协议**:RabbitMQ 除了原生支持 AMQP 协议,还支持 STOMP、MQTT 等多种消息中间件协议。 +- **多语言客户端**:RabbitMQ 几乎支持所有常用语言,比如 Java、Python、Ruby、PHP、C#、JavaScript 等。 +- **管理界面**:RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息、集群中的节点等。 +- **插件机制**:RabbitMQ 提供了许多插件,以实现从多方面进行扩展,当然也可以编写自己的插件。 ## RabbitMQ 核心概念? @@ -39,7 +37,7 @@ RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、 RabbitMQ 的整体模型架构如下: - + 下面我会一一介绍上图中的一些概念。 @@ -48,7 +46,7 @@ RabbitMQ 的整体模型架构如下: - **Producer(生产者)** :生产消息的一方(邮件投递者) - **Consumer(消费者)** :消费消息的一方(邮件收件人) -消息一般由 2 部分组成:**消息头**(或者说是标签 Label)和 **消息体**。消息体也可以称为 payLoad ,消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括 routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。生产者把消息交由 RabbitMQ 后,RabbitMQ 会根据消息头把消息发送给感兴趣的 Consumer(消费者)。 +消息一般由 2 部分组成:**消息头**(或者说是标签 Label)和 **消息体**。消息体也可以称为 **payload**,消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括 routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。生产者把消息交由 RabbitMQ 后,RabbitMQ 会根据消息头把消息发送给感兴趣的 Consumer(消费者)。 ### Exchange(交换器) @@ -56,19 +54,13 @@ RabbitMQ 的整体模型架构如下: **Exchange(交换器)** 用来接收生产者发送的消息并将这些消息路由给服务器中的队列中,如果路由不到,或许会返回给 **Producer(生产者)** ,或许会被直接丢弃掉 。这里可以将 RabbitMQ 中的交换器看作一个简单的实体。 -**RabbitMQ 的 Exchange(交换器) 有 4 种类型,不同的类型对应着不同的路由策略**:**direct(默认)**,**fanout**, **topic**, 和 **headers**,不同类型的 Exchange 转发消息的策略有所区别。这个会在介绍 **Exchange Types(交换器类型)** 的时候介绍到。 - -Exchange(交换器) 示意图如下: +**RabbitMQ 的 Exchange(交换器) 有 4 种类型,不同的类型对应着不同的路由策略**:**direct**,**fanout**, **topic**, 和 **headers**,不同类型的 Exchange 转发消息的策略有所区别。这个会在介绍 **Exchange Types(交换器类型)** 的时候介绍到。 - +> 注意:AMQP 规范定义了一个默认交换器(Default Exchange),它是一个 pre-declared 的 direct 类型交换器,但创建新交换器时必须显式指定类型,不能省略。 生产者将消息发给交换器的时候,一般会指定一个 **RoutingKey(路由键)**,用来指定这个消息的路由规则,而这个 **RoutingKey 需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效**。 -RabbitMQ 中通过 **Binding(绑定)** 将 **Exchange(交换器)** 与 **Queue(消息队列)** 关联起来,在绑定的时候一般会指定一个 **BindingKey(绑定建)** ,这样 RabbitMQ 就知道如何正确将消息路由到队列了,如下图所示。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。Exchange 和 Queue 的绑定可以是多对多的关系。 - -Binding(绑定) 示意图: - -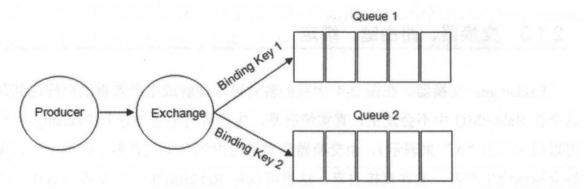 +RabbitMQ 中通过 **Binding(绑定)** 将 **Exchange(交换器)** 与 **Queue(消息队列)** 关联起来,在绑定的时候一般会指定一个 **BindingKey(绑定键)** ,这样 RabbitMQ 就知道如何正确将消息路由到队列了,如下图所示。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。Exchange 和 Queue 的绑定可以是多对多的关系。 生产者将消息发送给交换器时,需要一个 RoutingKey,当 BindingKey 和 RoutingKey 相匹配时,消息会被路由到对应的队列中。在绑定多个队列到同一个交换器的时候,这些绑定允许使用相同的 BindingKey。BindingKey 并不是在所有的情况下都生效,它依赖于交换器类型,比如 fanout 类型的交换器就会无视,而是将消息路由到所有绑定到该交换器的队列中。 @@ -76,9 +68,19 @@ Binding(绑定) 示意图: **Queue(消息队列)** 用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。 -**RabbitMQ** 中消息只能存储在 **队列** 中,这一点和 **Kafka** 这种消息中间件相反。Kafka 将消息存储在 **topic(主题)** 这个逻辑层面,而相对应的队列逻辑只是 topic 实际存储文件中的位移标识。 RabbitMQ 的生产者生产消息并最终投递到队列中,消费者可以从队列中获取消息并消费。 +**RabbitMQ** 在经典架构中,消息只能存储在 **队列** 中,这一点和 **Kafka** 这种消息中间件相反。Kafka 将消息存储在 **topic(主题)** 这个逻辑层面,而相对应的队列逻辑只是 topic 实际存储文件中的位移标识。RabbitMQ 的生产者生产消息并最终投递到队列中,消费者可以从队列中获取消息并消费。 + +> **版本说明(3.9+ 重要更新)**:从 RabbitMQ 3.9 版本开始,官方引入了 **Streams** 数据结构。Streams 提供了一种类似 Kafka 的 append-only 日志存储模型,支持非破坏性消费、大规模消息堆积以及基于 Offset 的历史数据重放(Replay)。 +> +> **架构选型建议**: +> +> - **普通队列**:适用于传统消息队列场景,消息被消费后即删除 +> - **Streams**:适用于需要高频重放、海量堆积或事件溯源的场景 +> - **核心瓶颈差异**:使用 Stream 时,磁盘 I/O 吞吐量(MB/s)取代了传统的每秒入队率(msg/s)成为核心瓶颈指标 + +**多个消费者可以订阅同一个队列**,默认情况下队列中的消息会被平均分摊(Round-Robin,即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,这样避免消息被重复消费。 -**多个消费者可以订阅同一个队列**,这时队列中的消息会被平均分摊(Round-Robin,即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,这样避免消息被重复消费。 +> 注意:实际分发策略受 `prefetch_count` 参数影响。默认行为(`prefetch_count=0`)会尽可能多地分发消息给各 Consumer,可能导致负载不均。推荐设置 `prefetch_count=1` 或更高值,让 Consumer 确认后再发送下一条,实现公平分发。 **RabbitMQ** 不支持队列层面的广播消费,如果有广播消费的需求,需要在其上进行二次开发,这样会很麻烦,不建议这样做。 @@ -86,57 +88,72 @@ Binding(绑定) 示意图: 对于 RabbitMQ 来说,一个 RabbitMQ Broker 可以简单地看作一个 RabbitMQ 服务节点,或者 RabbitMQ 服务实例。大多数情况下也可以将一个 RabbitMQ Broker 看作一台 RabbitMQ 服务器。 -下图展示了生产者将消息存入 RabbitMQ Broker,以及消费者从 Broker 中消费数据的整个流程。 - -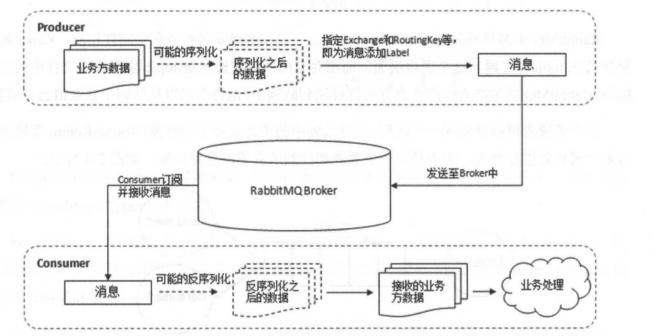 - -这样图 1 中的一些关于 RabbitMQ 的基本概念我们就介绍完毕了,下面再来介绍一下 **Exchange Types(交换器类型)** 。 - ### Exchange Types(交换器类型) -RabbitMQ 常用的 Exchange Type 有 **fanout**、**direct**、**topic**、**headers** 这四种(AMQP 规范里还提到两种 Exchange Type,分别为 system 与 自定义,这里不予以描述)。 - -**1、fanout** +RabbitMQ 常用的 Exchange Type 有 **fanout**、**direct**、**topic**、**headers** 这四种(AMQP 规范里还提到两种 Exchange Type,分别为 system 与自定义,这里不予以描述)。 -fanout 类型的 Exchange 路由规则非常简单,它会把所有发送到该 Exchange 的消息路由到所有与它绑定的 Queue 中,不需要做任何判断操作,所以 fanout 类型是所有的交换机类型里面速度最快的。fanout 类型常用来广播消息。 +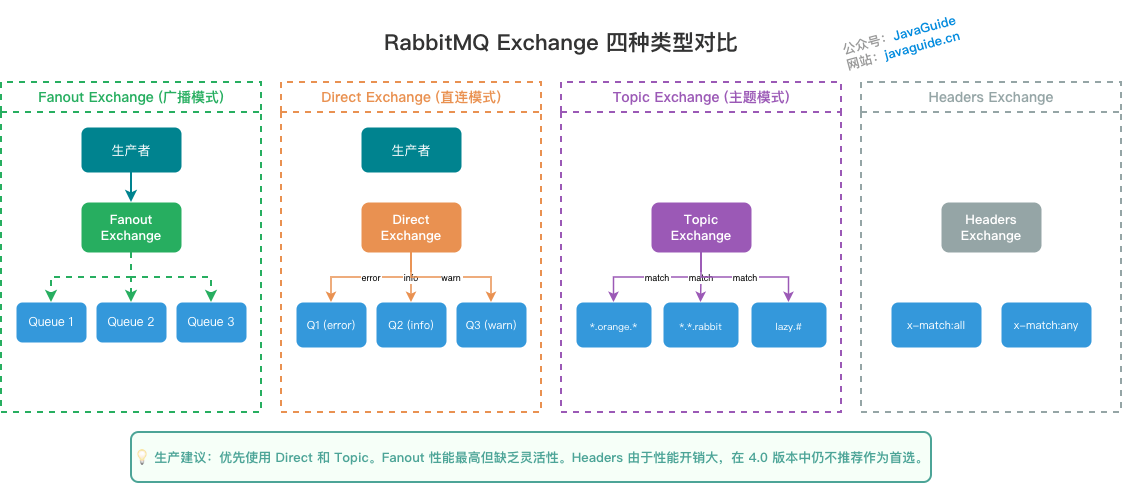 -**2、direct** +**1、fanout(广播模式)** -direct 类型的 Exchange 路由规则也很简单,它会把消息路由到那些 Bindingkey 与 RoutingKey 完全匹配的 Queue 中。 +- **路由规则**:把所有发送到该 Exchange 的消息路由到所有与它绑定的 Queue 中,**忽略 BindingKey** +- **特点**:不需要做任何判断操作,是所有交换机类型里面速度最快的 +- **典型使用场景**: + - 系统配置更新广播(如配置中心推送) + - 实时排行榜同步(多实例数据同步) + - 缓存失效广播(如 Redis 缓存清理通知) + - 日志分发(将日志同时发送到多个存储系统) -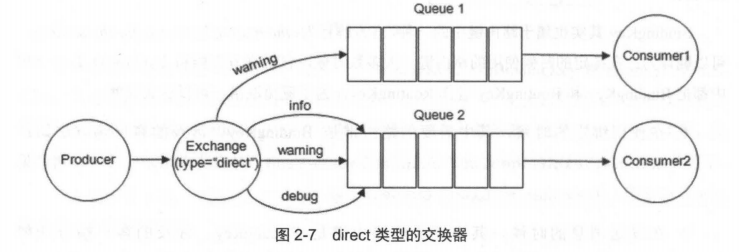 +**2、direct(直连模式)** -以上图为例,如果发送消息的时候设置路由键为“warning”,那么消息会路由到 Queue1 和 Queue2。如果在发送消息的时候设置路由键为"Info”或者"debug”,消息只会路由到 Queue2。如果以其他的路由键发送消息,则消息不会路由到这两个队列中。 +- **路由规则**:把消息路由到那些 BindingKey 与 RoutingKey **完全匹配**的 Queue 中 +- **特点**:精确匹配,路由效率高 +- **典型使用场景**: + - **基础点对点任务分发**:根据任务级别路由(如 `error`、`warning`、`info`) + - 优先级队列:高优先级任务分配更多资源 + - 按服务类型分发(如 `order-service`、`payment-service`) -direct 类型常用在处理有优先级的任务,根据任务的优先级把消息发送到对应的队列,这样可以指派更多的资源去处理高优先级的队列。 +**示例**:以上图为例,如果发送消息时设置路由键为 `"warning"`,消息会路由到 Queue1 和 Queue2;如果设置路由键为 `"info"` 或 `"debug"`,消息只会路由到 Queue2。 -**3、topic** +**3、topic(主题模式)** -前面讲到 direct 类型的交换器路由规则是完全匹配 BindingKey 和 RoutingKey ,但是这种严格的匹配方式在很多情况下不能满足实际业务的需求。topic 类型的交换器在匹配规则上进行了扩展,它与 direct 类型的交换器相似,也是将消息路由到 BindingKey 和 RoutingKey 相匹配的队列中,但这里的匹配规则有些不同,它约定: +- **路由规则**:基于 BindingKey 和 RoutingKey 的**模糊匹配** +- **匹配规则**: + - RoutingKey 为点号 `"."` 分隔的字符串(如 `com.rabbitmq.client`、`order.china.beijing`) + - BindingKey 中可以使用两种通配符: + - `"*"`:匹配**一个单词** + - `"#"`:匹配**零个或多个单词** +- **典型使用场景**: + - **按地域或业务模块过滤**(如 `order.china.*` 匹配中国所有地区订单) + - 多级路由(如 `com.rabbitmq.client`、`java.util.concurrent`) + - 发布订阅系统(分类通知、按标签订阅) -- RoutingKey 为一个点号“.”分隔的字符串(被点号“.”分隔开的每一段独立的字符串称为一个单词),如 “com.rabbitmq.client”、“java.util.concurrent”、“com.hidden.client”; -- BindingKey 和 RoutingKey 一样也是点号“.”分隔的字符串; -- BindingKey 中可以存在两种特殊字符串“\*”和“#”,用于做模糊匹配,其中“\*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)。 +**示例**: -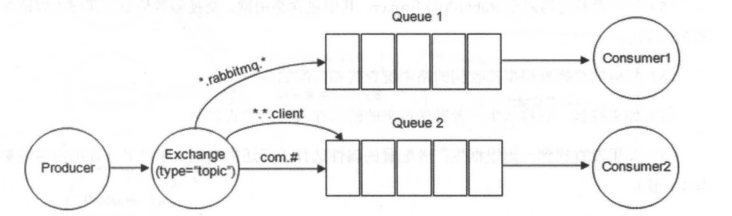 +- 路由键为 `"com.rabbitmq.client"` 的消息会同时路由到绑定 `"*.rabbitmq.*"` 和 `"#.client.#"` 的队列 +- 路由键为 `"order.china.beijing"` 的消息会路由到绑定 `"order.china.*"` 的队列 -以上图为例: +**4、headers(不推荐)** -- 路由键为 “com.rabbitmq.client” 的消息会同时路由到 Queue1 和 Queue2; -- 路由键为 “com.hidden.client” 的消息只会路由到 Queue2 中; -- 路由键为 “com.hidden.demo” 的消息只会路由到 Queue2 中; -- 路由键为 “java.rabbitmq.demo” 的消息只会路由到 Queue1 中; -- 路由键为 “java.util.concurrent” 的消息将会被丢弃或者返回给生产者(需要设置 mandatory 参数),因为它没有匹配任何路由键。 - -**4、headers(不推荐)** - -headers 类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中的 headers 属性进行匹配。在绑定队列和交换器时指定一组键值对,当发送消息到交换器时,RabbitMQ 会获取到该消息的 headers(也是一个键值对的形式),对比其中的键值对是否完全匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由到该队列。headers 类型的交换器性能会很差,而且也不实用,基本上不会看到它的存在。 +- **路由规则**:根据消息内容中的 headers 键值对进行匹配 +- **特点**: + - 不依赖 RoutingKey,支持 `x-match=all`(全部匹配)或 `x-match=any`(任一匹配) + - **性能较差**,匹配效率远低于其他三种类型 +- **典型使用场景**: + - 几乎不使用,面试时可提到"因为匹配性能较差,生产环境建议用 Topic 替代" + - 仅适用于极其复杂的路由规则且消息量极小的场景 ## AMQP 是什么? -RabbitMQ 就是 AMQP 协议的 `Erlang` 的实现(当然 RabbitMQ 还支持 `STOMP2`、 `MQTT3` 等协议 ) AMQP 的模型架构 和 RabbitMQ 的模型架构是一样的,生产者将消息发送给交换器,交换器和队列绑定 。 +RabbitMQ 就是 AMQP 协议的 `Erlang` 的实现(当然 RabbitMQ 还支持 `STOMP`、`MQTT` 等协议)。AMQP 的模型架构 和 RabbitMQ 的模型架构是一样的,生产者将消息发送给交换器,交换器和队列绑定。 -RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都是遵循的 AMQP 协议中相 应的概念。目前 RabbitMQ 最新版本默认支持的是 AMQP 0-9-1。 +RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都是遵循的 AMQP 协议中**相应**的概念。 + +> **版本说明**: +> +> - **AMQP 0-9-1**:RabbitMQ 的传统协议,广泛使用,功能完整 +> - **AMQP 1.0**:RabbitMQ 4.x 已将其提升为一等公民协议,显著优化了原生 AMQP 1.0 的解析效率,不再需要像旧版本那样通过复杂的插件转换。这提升了与其他消息中间件(如 ActiveMQ、Service Bus)的互操作性,适合需要跨平台集成的场景 +> - 新项目可考虑使用 AMQP 1.0 以获得更好的跨平台兼容性 **AMQP 协议的三层**: @@ -150,12 +167,12 @@ RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都 - **队列 (Queue)**:用来存储消息的数据结构,位于硬盘或内存中。 - **绑定 (Binding)**:一套规则,告知交换器消息应该将消息投递给哪个队列。 -## **说说生产者 Producer 和消费者 Consumer?** +## 说说生产者 Producer 和消费者 Consumer -**生产者** : +**生产者**: - 消息生产者,就是投递消息的一方。 -- 消息一般包含两个部分:消息体(`payload`)和标签(`Label`)。 +- 消息一般包含两个部分:**消息体**(payload)和**消息头**(Label/Headers)。 **消费者**: @@ -170,11 +187,11 @@ RabbitMQ 中的交换器、交换器类型、队列、绑定、路由键等都 ## 什么是死信队列?如何导致的? -DLX,全称为 `Dead-Letter-Exchange`,死信交换器,死信邮箱。当消息在一个队列中变成死信 (`dead message`) 之后,它能被重新发送到另一个交换器中,这个交换器就是 DLX,绑定 DLX 的队列就称之为死信队列。 +DLX,全称为 `Dead-Letter-Exchange`(死信交换器),当消息在一个队列中变成死信(`dead message`)之后,它能被重新发送到另一个交换器中,这个交换器就是 DLX,绑定 DLX 的队列就称之为死信队列。 **导致的死信的几种原因**: -- 消息被拒(`Basic.Reject /Basic.Nack`) 且 `requeue = false`。 +- 消息被拒(`Basic.Reject` 或 `Basic.Nack`)且 `requeue = false`。 - 消息 TTL 过期。 - 队列满了,无法再添加。 @@ -185,7 +202,13 @@ DLX,全称为 `Dead-Letter-Exchange`,死信交换器,死信邮箱。当消 RabbitMQ 本身是没有延迟队列的,要实现延迟消息,一般有两种方式: 1. 通过 RabbitMQ 本身队列的特性来实现,需要使用 RabbitMQ 的死信交换机(Exchange)和消息的存活时间 TTL(Time To Live)。 -2. 在 RabbitMQ 3.5.7 及以上的版本提供了一个插件(rabbitmq-delayed-message-exchange)来实现延迟队列功能。同时,插件依赖 Erlang/OPT 18.0 及以上。 + + - 缺点:消息按队列过期而非单消息级别(除非给每个消息单独队列) + +2. 在 RabbitMQ 3.5.7 及以上的版本提供了一个插件(rabbitmq-delayed-message-exchange)来实现延迟队列功能。同时,插件依赖 Erlang/OTP 18.0 及以上。 + - 原理:将消息暂存在 Mnesia 表中,定时轮询并投递到目标交换器 + - **容量边界警告(严重)**:该插件将延迟消息全部暂存在 Erlang 的 Mnesia 内部数据库中,**不具备良好的磁盘换页(Paging)能力**。如果单节点堆积**数十万到上百万级别**的延迟消息,会导致 Broker 内存剧增甚至触发**内存高水位(Memory Watermark)告警**,进而产生 **全局背压(Global Backpressure)** 阻塞所有生产者的 TCP 连接。 + - **生产建议**:针对海量延迟(千万级以上),必须退化使用外部定时任务(如时间轮、SchedulerX、XXL-JOB)调度或死信链表方案 也就是说,AMQP 协议以及 RabbitMQ 本身没有直接支持延迟队列的功能,但是可以通过 TTL 和 DLX 模拟出延迟队列的功能。 @@ -205,28 +228,167 @@ RabbitMQ 自 V3.5.0 有优先级队列实现,优先级高的队列会先被消 ## RabbitMQ 消息怎么传输? -由于 TCP 链接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈,所以 RabbitMQ 使用信道的方式来传输数据。信道(Channel)是生产者、消费者与 RabbitMQ 通信的渠道,信道是建立在 TCP 链接上的虚拟链接,且每条 TCP 链接上的信道数量没有限制。就是说 RabbitMQ 在一条 TCP 链接上建立成百上千个信道来达到多个线程处理,这个 TCP 被多个线程共享,每个信道在 RabbitMQ 都有唯一的 ID,保证了信道私有性,每个信道对应一个线程使用。 +由于 TCP 链接的创建和销毁开销较大(三次握手、慢启动等),且并发数受系统资源限制,会造成性能瓶颈,所以 RabbitMQ 使用信道的方式来传输数据。信道(Channel)是生产者、消费者与 RabbitMQ 通信的渠道,信道是建立在 TCP 链接上的虚拟链接。 + +> 注意: +> +> - 单个 TCP 连接可承载多个 Channel,但官方建议不超过 100-200 个/连接 +> - 每个 Channel 有独立的编号,但共享同一 TCP 连接的流量控制 +> - **Channel 不是线程安全的**,多线程应使用不同 Channel 实例 + +## 如何保证消息的可靠性? + + + +消息可能在三个环节丢失:生产者 → Broker、Broker 存储期间、Broker → 消费者 + +**1. 生产者 → Broker** + +保证生产者端零丢失需要**双重机制兜底**: + +- **Publisher Confirms**(异步确认):确认消息是否到达 Broker + + ```java + channel.confirmSelect(); + channel.addConfirmListener((sequenceNumber, multiple) -> { + // 消息已到达 Broker 并落盘/同步到镜像 + }, (sequenceNumber, multiple) -> { + // 消息未到达 Broker,记录日志并重试 + }); + ``` + +- **Mandatory + Return Listener**(路由失败处理):捕获消息到达 Exchange 但无法路由到 Queue 的情况 + + ```java + // 开启 mandatory 模式 + channel.basicPublish("exchange", "routingKey", + true, // mandatory=true + null, + messageBody); + + // 配置 Return Listener + channel.addReturnListener((replyCode, replyText, exchange, routingKey, properties, body) -> { + // 消息到达 Exchange 但路由失败,记录日志或发送到备用交换器 + log.error("Message returned: {}", replyText); + }); + ``` + +> **关键警告**:若仅开启 Confirm 未处理 Return,配置漂移(如误删队列或绑定)会导致生产者认为发送成功,但消息在 Broker 内部被静默丢弃,形成**消息黑洞**。 + +- **事务机制**(不推荐):同步阻塞,**性能显著下降(官方文档未给出具体倍数,实际影响取决于消息大小和网络延迟)** + - 注意:事务机制和 Confirm 机制是互斥的,两者不能共存 + +**2. Broker 存储期间** + +- **消息持久化**:`delivery_mode=2`,消息写入磁盘 +- **队列持久化**:`durable=true`,重启后队列重建 +- **集群模式**: + - **镜像队列**(Classic Queue Mirroring,已于 4.0 移除):主从同步,仅用于老版本维护 + - **Quorum Queue**(3.8+ 推荐,4.0 后为默认):基于 Raft 协议,支持更严格的仲裁写入(N/2 + 1) + - **Streams**(3.9+):适用于事件溯源和高频重放场景 -## **如何保证消息的可靠性?** +**3. Broker → 消费者** -消息到 MQ 的过程中搞丢,MQ 自己搞丢,MQ 到消费过程中搞丢。 +- **手动 Ack**:`basicAck(deliveryTag, multiple)`,确保消费成功后再确认 +- **重试机制**:消费失败时 `basicNack` 或 `basicReject` 并 `requeue=true` +- **死信队列**:达到最大重试次数后路由到 DLQ 人工介入 +- **幂等性保障**:业务层实现,避免重复消费导致的数据不一致。幂等性具体实现方案参考这篇文章:[接口幂等方案总结](https://javaguide.cn/high-availability/idempotency.html)。 -- 生产者到 RabbitMQ:事务机制和 Confirm 机制,注意:事务机制和 Confirm 机制是互斥的,两者不能共存,会导致 RabbitMQ 报错。 -- RabbitMQ 自身:持久化、集群、普通模式、镜像模式。 -- RabbitMQ 到消费者:basicAck 机制、死信队列、消息补偿机制。 +以下时序图展示了从生产者到消费者的完整消息流转及各环节的异常处理策略: + +```mermaid +sequenceDiagram + participant P as 生产者 (Producer) + participant E as 交换器 (Exchange) + participant DLX as 死信交换器 (DLX) + participant Q as 队列 (Quorum Queue) + participant C as 消费者 (Consumer) + + P->>E: 1. 发送消息 (开启 Confirm & Mandatory) + alt 路由成功 + E->>Q: 2. 消息进入队列 + Q-->>P: 3. Raft 多数派落盘后返回 Confirm Ack + else 路由失败 (无匹配 Queue, mandatory=true) + E-->>P: 2a. 触发 Return Listener 返回消息 + Note over P: 记录日志或告警 + end + + Q->>C: 4. 推送消息 (开启手动 Ack) + + alt 消费成功 + C-->>Q: 5. 发送 basic.ack + Q->>Q: 6. 标记消息可删除 + else 业务异常且可重试 + C-->>Q: 5a. basic.nack (requeue=true) + Q->>Q: 6a. 消息重回队列尾部 (注意:顺序破坏) + else 致命异常 / 重试超限 + C-->>Q: 5b. basic.reject (requeue=false) + Q->>DLX: 6b. 路由至死信交换机 (DLX) + end +``` + +**关键路径说明**: + +- **Confirm + Returns**(互为补充): + - Confirm 确认消息是否到达 Broker 并落盘/同步 + - Mandatory + Return Listener 捕获路由失败事件(消息到达 Exchange 但无法进入 Queue) +- **Quorum Queue**:Raft 多数派确认后才返回 Ack,保证数据不丢 +- **手动 Ack**:确保消费成功后才删除消息 +- **DLQ 兜底**:重试超限后路由到死信队列,避免消息无限重试 + +> **注意**:Alternate Exchange(备用交换器)是另一种独立的路由失败处理机制,与 Mandatory + Return Listener 互斥。配置 Alternate Exchange 后,路由失败的消息会被转发到备用交换器,生产者收到的是正常的 Confirm Ack 而非 Return。 ## 如何保证 RabbitMQ 消息的顺序性? -- 拆分多个 queue(消息队列),每个 queue(消息队列) 一个 consumer(消费者),就是多一些 queue (消息队列)而已,确实是麻烦点; -- 或者就一个 queue (消息队列)但是对应一个 consumer(消费者),然后这个 consumer(消费者)内部用内存队列做排队,然后分发给底层不同的 worker 来处理。 +RabbitMQ 仅保证**单个 Queue 内的 FIFO 顺序**,但多消费者场景下可能出现乱序。解决方案: + +**1. 单 Consumer 模式** + +- 一个 Queue 只绑定一个 Consumer +- 优点:保证顺序 +- 缺点:成为瓶颈,吞吐量受限 + +**2. 分区有序**(推荐,但需注意失效模式) + +- 按业务 key(如订单ID)哈希到不同 Queue +- 每个 Queue 独立 Consumer +- 优点:既保证顺序又提高吞吐量 + +> **失效模式警告**: +> +> - **拓扑变更乱序**:当后端队列扩缩容导致哈希环发生变化时,同一个业务 Key 的新老消息可能进入不同队列 +> - **重试乱序**:若消费者内部处理失败执行 Nack 并 Requeue,该消息会被重新推入队列**尾部**,导致后续消息先被消费 +> - **应用层防护**:极端严格顺序场景下,消费者业务表必须设计基于**状态机**或**版本号**的幂等与防并发覆盖机制 + +**3. 内部内存队列**(慎重) + +- 单一 Consumer 内部维护内存队列分发到 Worker 线程池 +- 需处理: + - Consumer 挂掉时内存队列丢失风险 + - 需实现背压机制防止 OOM + - 增加 ack 复杂度(需追踪具体 Worker 处理状态) +- 生产环境慎用此方案 ## 如何保证 RabbitMQ 高可用的? -RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的,我们就以 RabbitMQ 为例子讲解第一种 MQ 的高可用性怎么实现。RabbitMQ 有三种模式:单机模式、普通集群模式、镜像集群模式。 +RabbitMQ 是比较有代表性的,因为是基于主从(非分布式)做高可用性的,我们就以 RabbitMQ 为例子讲解第一种 MQ 的高可用性怎么实现。RabbitMQ 有四种模式:单机模式、普通集群模式、镜像集群模式(已废弃)、Quorum Queue(推荐)。 + +> **版本演进说明**: +> +> - **3.8 前**:镜像队列(Classic Queue Mirroring)是主要高可用方案 +> - **3.8+**:Quorum Queue 作为推荐替代方案,镜像队列被标记为 deprecated +> - **3.13**:镜像队列仍可用但已废弃 +> - **4.0+**:镜像队列**完全移除**,Quorum Queue 成为默认高可用方案 +> +> **网络分区警告(严重)**:无论是普通集群还是早期的镜像集群,均依赖 Erlang 内部的分布式同步机制,对网络抖动极度敏感。在多机房或跨可用区部署时,极易发生**网络分区(Split-brain)**。必须在 `rabbitmq.conf` 中明确配置分区恢复策略: +> +> - `pause_minority`:少数派节点自动暂停服务以防数据分化(推荐) +> - `autoheal`:自动选择一方继续运行(有数据丢失风险) +> - 对于 3.8 以上版本,强烈建议直接使用基于 Raft 一致性算法的 Quorum Queue,从根本上解决网络分区导致的消息丢失与状态不一致问题 **单机模式** -Demo 级别的,一般就是你本地启动了玩玩儿的?,没人生产用单机模式。 +Demo 级别的,一般就是你本地启动了玩玩儿的,没人生产用单机模式。 **普通集群模式** @@ -234,14 +396,276 @@ Demo 级别的,一般就是你本地启动了玩玩儿的?,没人生产用 你消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从 queue 所在实例上拉取数据过来。这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个 queue 的读写操作。 -**镜像集群模式** +**镜像集群模式**(Classic Queue Mirroring,已废弃) + +> ⚠️ **重要警告**:镜像队列已在 RabbitMQ 4.0 中被**完全移除**。RabbitMQ 3.8 引入 Quorum Queue 作为推荐替代方案,3.13 版本镜像队列仍可用但已废弃,4.0 版本正式移除。新项目请使用 Quorum Queue 或 Streams。 + +这种模式是 RabbitMQ 早期版本的高可用方案。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据。每次写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。 -这种模式,才是所谓的 RabbitMQ 的高可用模式。跟普通集群模式不一样的是,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。RabbitMQ 有很好的管理控制台,就是在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。 +**工作原理**: -这样的好处在于,你任何一个机器宕机了,没事儿,其它机器(节点)还包含了这个 queue 的完整数据,别的 consumer 都可以到其它节点上去消费数据。坏处在于,第一,这个性能开销也太大了吧,消息需要同步到所有机器上,导致网络带宽压力和消耗很重!RabbitMQ 一个 queue 的数据都是放在一个节点里的,镜像集群下,也是每个节点都放这个 queue 的完整数据。 +- Queue 主节点接收消息,同步到 N 个镜像节点 +- 主节点宕机时,最老的镜像节点升级为主节点 +- 通过管理控制台新增策略,指定数据同步到所有节点或指定数量的节点 + +**优点**: + +- 任何机器宕机,其他节点包含该 queue 的完整数据 +- Consumer 可以切换到其他节点继续消费 + +**缺点**: + +- 性能开销大,消息需要同步到所有机器上 +- 网络带宽压力和消耗重 +- 不是真正的分布式架构,是主从复制 + +**Quorum Queue**(3.8+ 推荐,4.0 后为默认高可用方案) + +基于 Raft 协议的复制队列,是 RabbitMQ 3.8+ 推荐的高可用方案,4.0 后成为默认选项: + +- **基于 Raft 协议**:通过日志复制和选举实现一致性 +- **仲裁写入**:需要多数节点确认(N/2 + 1)才认为写入成功 +- **更严格的一致性**:避免镜像队列的脑裂风险 +- **适用场景**:对可靠性要求高的场景 + +**声明方式(客户端)**: + +Java: + +```java +// Java 客户端声明 Quorum Queue +Map
(无队列可消费)"] + end + + subgraph Message["消息粒度负载均衡 5.x"] + style Message fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + direction TB + MQ1["队列1"] --> MC1["消费者1
消费消息1"] + MQ1 --> MC2["消费者2
消费消息2"] + MQ1 --> MC3["消费者3
消费消息3"] + end + + classDef queue fill:#4CA497,color:#fff,rx:10,ry:10 + classDef consumer4x fill:#E99151,color:#fff,rx:10,ry:10 + classDef consumer5x fill:#00838F,color:#fff,rx:10,ry:10 + + class Q1,Q2,Q3,Q4,MQ1 queue + class C1,C2,C3,C4 consumer4x + class MC1,MC2,MC3 consumer5x + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + +- **队列粒度负载均衡(4.x 默认策略)**:一个队列只会被一个消费者消费。如果某个消费者挂掉,分组内其它消费者会接替挂掉的消费者继续消费。就像上图中 `Consumer1` 和 `Consumer2` 分别对应着两个队列,而 `Consumer3` 是没有队列对应的,所以一般来讲要控制 **消费者组中的消费者个数和主题中队列个数相同** 。这种模式的缺点是容易产生 **长尾效应**:如果某个消费者处理速度较慢,会导致其对应的队列消息堆积,而其他消费者却处于空闲状态。 +- **消息粒度负载均衡(5.x 新增策略)**:同一消费者分组内的多个消费者将按照消息粒度平均分摊主题中的所有消息,即同一个队列中的消息,可被平均分配给多个消费者共同消费。消费者获取某条消息后,服务端会将该消息加锁,保证这条消息对其他消费者不可见,直到该消息消费成功或消费超时。这种模式有效解决了长尾效应问题,因为消息不再静态绑定到某个消费者,而是动态分配给空闲的消费者。 当然也可以消费者个数小于队列个数,只不过不太建议。如下图。 @@ -215,119 +319,622 @@ tag:  -但是,这样我生产者是不是只能向一个队列发送消息?又因为需要维护消费位置所以一个队列只能对应一个消费者组中的消费者,这样是不是其他的 `Consumer` 就没有用武之地了?从这两个角度来讲,并发度一下子就小了很多。 +但是,这样我生产者是不是只能向一个队列发送消息?又因为需要维护消费位置所以一个队列只能对应一个消费者组中的消费者,这样是不是其他的 Consumer 就没有用武之地了?从这两个角度来讲,并发度一下子就小了很多。 + +所以总结来说,RocketMQ 通过**使用在一个 Topic 中配置多个队列并且每个队列维护每个消费者组的消费位置** 实现了 **主题模式/发布订阅模式** 。 + +## RocketMQ 架构 + +讲完了消息模型,我们理解起 RocketMQ 的技术架构起来就容易多了。 + +RocketMQ 的核心组件包括 **NameServer、Broker、Producer、Consumer**,在 5.0 版本中还引入了 **Proxy** 组件。 + +```mermaid +flowchart TB + subgraph RocketMQ["RocketMQ 系统架构"] + direction TB + style RocketMQ fill:#F0F2F5,stroke:#E0E6ED,stroke-width:1.5px + + subgraph Components["核心组件"] + direction TB + style Components fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + NS["NameServer
注册中心"] + BK["Broker
消息存储"] + PX["Proxy
代理层(5.0+)"] + PD["Producer
生产者"] + CM["Consumer
消费者"] + end + + subgraph Protocol["通信协议"] + direction LR + style Protocol fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + RP["Remoting
私有协议"] + GP["gRPC
云原生协议"] + end + + subgraph Network["网络层"] + style Network fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + NB["Netty
高性能通信框架"] + end + end + + NS <--> BK + NS <--> PD + NS <--> CM + PD <--> PX + CM <--> PX + PX <--> BK + PD -.->|Remoting 直连| BK + CM -.->|Remoting 直连| BK + BK --> NB + RP --> NB + GP --> NB + + classDef ns fill:#E99151,color:#fff,rx:10,ry:10 + classDef broker fill:#4CA497,color:#fff,rx:10,ry:10 + classDef proxy fill:#005D7B,color:#fff,rx:10,ry:10 + classDef producer fill:#00838F,color:#fff,rx:10,ry:10 + classDef consumer fill:#7E57C2,color:#fff,rx:10,ry:10 + classDef remoting fill:#FFC107,color:#333,rx:10,ry:10 + classDef grpc fill:#26A69A,color:#fff,rx:10,ry:10 + classDef netty fill:#EF5350,color:#fff,rx:10,ry:10 + + class NS ns + class BK broker + class PX proxy + class PD producer + class CM consumer + class RP remoting + class GP grpc + class NB netty + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + +### 核心组件要点 + +| 组件 | 技术要点 | +| -------------- | ---------------------------------------- | +| **NameServer** | 轻量级注册中心,各节点无数据同步 | +| **Broker** | 消息存储与投递,支持主从部署 | +| **Proxy** | 5.0 新增,协议适配与计算卸载(可选组件) | +| **Producer** | 同步、异步、单向多种发送方式 | +| **Consumer** | Push/Pull/Simple 三种消费模式 | + +### NameServer(注册中心) + +NameServer 负责元数据的存储,扮演着集群"中枢神经系统"的角色,其核心作用是为生产者和消费者提供路由信息,帮助它们找到对应的 Broker 地址。 + +**核心功能:** + +1. **Broker 管理**:Broker 启动时主动连接 NameServer,上报元数据信息。 +2. **路由信息管理**:生产者和消费者从 NameServer 获取 Broker 路由表。 + +**心跳机制:** + +```mermaid +flowchart LR + subgraph Heartbeat["心跳机制"] + style Heartbeat fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + direction TB + BK["Broker"] -->|启动时| Reg["注册元数据"] + BK -->|每隔30秒| HB["发送心跳包"] + HB --> NS["NameServer
更新路由表"] + NS -->|每隔10秒检查| Check["检查心跳
(120秒超时)"] + Check -->|超时| Down["标记Broker宕机"] + end + + classDef broker fill:#4CA497,color:#fff,rx:10,ry:10 + classDef ns fill:#E99151,color:#fff,rx:10,ry:10 + classDef check fill:#FFC107,color:#333,rx:10,ry:10 + classDef down fill:#EF5350,color:#fff,rx:10,ry:10 + classDef default fill:#4CA497,color:#fff,rx:10,ry:10 + + class BK broker + class NS ns + class Check check + class Down down + class Reg,HB default + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + +**元数据包含:** + +- Broker 的地址、名称、BrokerId +- 主节点地址 +- 该 Broker 上的所有 Topic 的队列配置 + +### Broker(消息存储) + +Broker 负责消息的存储、投递和查询以及服务高可用保证。 + +**存储机制:** + +1. **消息写入**:收到消息后顺序追加到 CommitLog 文件 +2. **文件分割**:文件超过固定大小(默认 1G)生成新文件 +3. **逻辑分片**:MessageQueue 是逻辑分片,ConsumeQueue 是消息索引 + +**一个 Topic 分布在多个 Broker 上,一个 Broker 可以配置多个 Topic ,它们是多对多的关系**。 + +如果某个 Topic 消息量很大,应该给它多配置几个队列(上文中提到了提高并发能力),并且 **尽量多分布在不同 Broker 上,以减轻某个 Broker 的压力** 。 + +Topic 消息量都比较均匀的情况下,如果某个 Broker 上的队列越多,则该 Broker 压力越大。 + + + +### Producer(生产者) + +**发送流程:** + +```mermaid +flowchart TB + subgraph ProducerFlow["生产者发送流程"] + direction TB + style ProducerFlow fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + + P["Producer 启动"] -->|1.建立长连接| NS1["连接 NameServer
获取路由表"] + NS1 -->|2.选择队列| LB["负载均衡算法
选择 MessageQueue"] + LB -->|3.建立连接| BK["与 Broker 建立长连接"] + BK -->|4.发送消息| MSG["发送消息到
MessageQueue"] + end + + classDef producer fill:#00838F,color:#fff,rx:10,ry:10 + classDef ns fill:#E99151,color:#fff,rx:10,ry:10 + classDef lb fill:#FFC107,color:#333,rx:10,ry:10 + classDef broker fill:#4CA497,color:#fff,rx:10,ry:10 + classDef msg fill:#7E57C2,color:#fff,rx:10,ry:10 + + class P producer + class NS1 ns + class LB lb + class BK broker + class MSG msg + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + +**三种发送方式:** + +- **单向发送(Oneway)**:发送后立即返回,不关心是否成功 +- **同步发送(Sync)**:发送后等待响应 +- **异步发送(Async)**:发送后立即返回,在回调方法中处理响应 + +### Consumer(消费者) + +**消费流程:** + +```mermaid +flowchart TB + subgraph ConsumerFlow["消费者消费流程"] + direction TB + style ConsumerFlow fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + + C["Consumer 启动"] -->|1.建立长连接| NS2["连接 NameServer
获取路由表"] + NS2 -->|2.建立连接| BK2["与 Broker 建立连接"] + BK2 -->|3.消费消息| CONS["开始消费消息"] + CONS -->|4.提交位点| OFFSET["提交消费位点
保存消费进度"] + end -所以总结来说,`RocketMQ` 通过**使用在一个 `Topic` 中配置多个队列并且每个队列维护每个消费者组的消费位置** 实现了 **主题模式/发布订阅模式** 。 + classDef consumer fill:#7E57C2,color:#fff,rx:10,ry:10 + classDef ns fill:#E99151,color:#fff,rx:10,ry:10 + classDef broker fill:#4CA497,color:#fff,rx:10,ry:10 + classDef consume fill:#00838F,color:#fff,rx:10,ry:10 + classDef offset fill:#FFC107,color:#333,rx:10,ry:10 -## RocketMQ 的架构图 + class C consumer + class NS2 ns + class BK2 broker + class CONS consume + class OFFSET offset -讲完了消息模型,我们理解起 `RocketMQ` 的技术架构起来就容易多了。 + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + +**三种消费模式:** + +- **拉取模式(Pull)**:消费者主动向 Broker 发送拉取请求 +- **推模式(Push)**:长轮询机制,Broker 有消息时才返回 +- **无状态模式(Pop)**:RocketMQ 5.0 新增,服务端管理重平衡和位点 + +### 网络协议 -`RocketMQ` 技术架构中有四大角色 `NameServer`、`Broker`、`Producer`、`Consumer` 。我来向大家分别解释一下这四个角色是干啥的。 +RocketMQ 支持两种协议: -- `Broker`:主要负责消息的存储、投递和查询以及服务高可用保证。说白了就是消息队列服务器嘛,生产者生产消息到 `Broker` ,消费者从 `Broker` 拉取消息并消费。 +| 协议 | Remoting(私有协议) | gRPC(云原生) | +| -------------- | -------------------- | ------------------------- | +| **性能** | 极致(私有协议优化) | 稍低(HTTP/2 头部开销) | +| **多语言支持** | 高成本(需重复实现) | 低成本(官方/社区实现) | +| **云原生集成** | 困难(需额外适配) | 原生支持(Istio/K8s) | +| **可观测性** | 需额外开发 | 原生支持(OpenTelemetry) | +| **适用场景** | 内部高性能场景 | 面向用户和云原生 | - 这里,我还得普及一下关于 `Broker`、`Topic` 和 队列的关系。上面我讲解了 `Topic` 和队列的关系——一个 `Topic` 中存在多个队列,那么这个 `Topic` 和队列存放在哪呢? +### 网络模块(基于 Netty) - **一个 `Topic` 分布在多个 `Broker`上,一个 `Broker` 可以配置多个 `Topic` ,它们是多对多的关系**。 +RocketMQ 的 RPC 通信采用 Netty 作为底层通信库,基于 Reactor 多线程模型进行了深度扩展和优化。 - 如果某个 `Topic` 消息量很大,应该给它多配置几个队列(上文中提到了提高并发能力),并且 **尽量多分布在不同 `Broker` 上,以减轻某个 `Broker` 的压力** 。 +**线程模型总结:** - `Topic` 消息量都比较均匀的情况下,如果某个 `broker` 上的队列越多,则该 `broker` 压力越大。 +- **Reactor 主线程**:1 个,负责监听连接 +- **Reactor 线程池**:默认 3 个,负责网络数据处理 +- **业务线程池**:动态调整,根据 CPU 核心数 -  +### Proxy(代理层,5.0 新增) - > 所以说我们需要配置多个 Broker。 +RocketMQ 5.0 引入了 **Proxy** 组件,这是 **计算与存储分离** 架构的核心体现。Proxy 作为客户端与 Broker 之间的代理层,将客户端协议适配、权限管理、消费管理等计算逻辑从 Broker 中剥离出来,使 Broker 更专注于消息存储和高可用。这种设计对于云原生架构非常重要,使得计算层可以独立弹性扩展。 -- `NameServer`:不知道你们有没有接触过 `ZooKeeper` 和 `Spring Cloud` 中的 `Eureka` ,它其实也是一个 **注册中心** ,主要提供两个功能:**Broker 管理** 和 **路由信息管理** 。说白了就是 `Broker` 会将自己的信息注册到 `NameServer` 中,此时 `NameServer` 就存放了很多 `Broker` 的信息(Broker 的路由表),消费者和生产者就从 `NameServer` 中获取路由表然后照着路由表的信息和对应的 `Broker` 进行通信(生产者和消费者定期会向 `NameServer` 去查询相关的 `Broker` 的信息)。 +**两种部署模式:** -- `Producer`:消息发布的角色,支持分布式集群方式部署。说白了就是生产者。 +| 模式 | 说明 | 适用场景 | +| ---------------- | ----------------------------------------------- | ---------------------------------------- | +| **Local 模式** | Proxy 和 Broker 同进程部署,只需新增 Proxy 配置 | 从旧版本平滑升级,或无特殊需求的场景 | +| **Cluster 模式** | Proxy 和 Broker 分别独立部署 | 需要弹性扩展或对协议适配有定制需求的场景 | -- `Consumer`:消息消费的角色,支持分布式集群方式部署。支持以 push 推,pull 拉两种模式对消息进行消费。同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制。说白了就是消费者。 +**核心作用:** -听完了上面的解释你可能会觉得,这玩意好简单。不就是这样的么? +- **协议适配**:支持 gRPC 协议接入,方便多语言客户端接入 +- **计算卸载**:将认证鉴权、消费管理等计算逻辑从 Broker 剥离,降低 Broker 负载 +- **弹性扩展**:Proxy 无状态,可独立水平扩展 + +> **注意**:在 5.0 版本中,使用新版 SDK(gRPC 协议)的客户端需要通过 Proxy 接入,而旧版 SDK(Remoting 协议)仍然可以直连 Broker。 + +### 为什么必须要 NameServer? + +先看一个简单的架构模型: 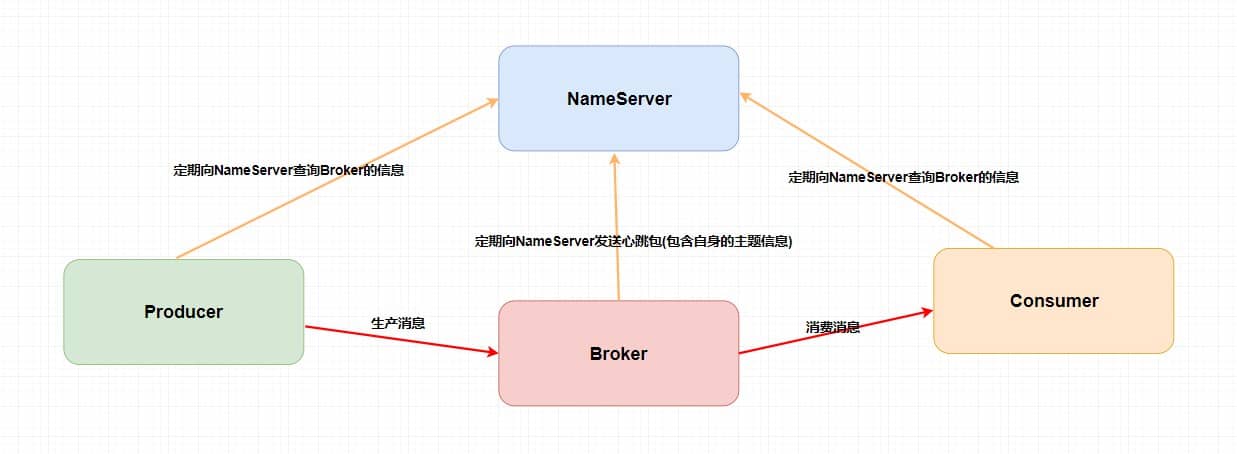 -嗯?你可能会发现一个问题,这老家伙 `NameServer` 干啥用的,这不多余吗?直接 `Producer`、`Consumer` 和 `Broker` 直接进行生产消息,消费消息不就好了么? +你可能会发现一个问题:NameServer 是做什么的?直接让 Producer、Consumer 和 Broker 进行生产和消费消息不行吗? -但是,我们上文提到过 `Broker` 是需要保证高可用的,如果整个系统仅仅靠着一个 `Broker` 来维持的话,那么这个 `Broker` 的压力会不会很大?所以我们需要使用多个 `Broker` 来保证 **负载均衡** 。 +Broker 需要保证高可用,如果整个系统仅靠一个 Broker 来维持,压力会非常大,所以需要使用多个 Broker 来保证 **负载均衡**。如果消费者和生产者直接和多个 Broker 相连,当 Broker 变更时会牵连每个生产者和消费者,产生耦合问题。NameServer 注册中心就是用来解决这个问题的。 -如果说,我们的消费者和生产者直接和多个 `Broker` 相连,那么当 `Broker` 修改的时候必定会牵连着每个生产者和消费者,这样就会产生耦合问题,而 `NameServer` 注册中心就是用来解决这个问题的。 +**NameServer 的设计哲学:** -> 如果还不是很理解的话,可以去看我介绍 `Spring Cloud` 的那篇文章,其中介绍了 `Eureka` 注册中心。 +NameServer 是 **无状态的、各节点之间互不通信** 的。这与 ZooKeeper 的强一致性(需要选举机制)形成了鲜明对比,体现了 RocketMQ 追求 **极致性能和简单架构** 的设计哲学。每个 Broker 与所有 NameServer 保持长连接,定期上报自身信息,即使某个 NameServer 节点宕机,也不会影响整个集群的可用性。 -当然,`RocketMQ` 中的技术架构肯定不止前面那么简单,因为上面图中的四个角色都是需要做集群的。我给出一张官网的架构图,大家尝试理解一下。 +下面是官网的架构图:  -其实和我们最开始画的那张乞丐版的架构图也没什么区别,主要是一些细节上的差别。听我细细道来 🤨。 - -第一、我们的 `Broker` **做了集群并且还进行了主从部署** ,由于消息分布在各个 `Broker` 上,一旦某个 `Broker` 宕机,则该`Broker` 上的消息读写都会受到影响。所以 `Rocketmq` 提供了 `master/slave` 的结构,`salve` 定时从 `master` 同步数据(同步刷盘或者异步刷盘),如果 `master` 宕机,**则 `slave` 提供消费服务,但是不能写入消息** (后面我还会提到哦)。 +和前面的简化架构图相比,主要是一些细节上的差别: -第二、为了保证 `HA` ,我们的 `NameServer` 也做了集群部署,但是请注意它是 **去中心化** 的。也就意味着它没有主节点,你可以很明显地看出 `NameServer` 的所有节点是没有进行 `Info Replicate` 的,在 `RocketMQ` 中是通过 **单个 Broker 和所有 NameServer 保持长连接** ,并且在每隔 30 秒 `Broker` 会向所有 `Nameserver` 发送心跳,心跳包含了自身的 `Topic` 配置信息,这个步骤就对应这上面的 `Routing Info` 。 +第一、Broker **做了集群并且还进行了主从部署** ,由于消息分布在各个 Broker 上,一旦某个 Broker 宕机,则该 Broker 上的消息读写都会受到影响。所以 RocketMQ 提供了 `master/slave` 的结构,`slave` 定时从 `master` 同步数据(同步刷盘或者异步刷盘),如果 `master` 宕机,**则 `slave` 提供消费服务,但是不能写入消息** (后面还会详细说明)。 -第三、在生产者需要向 `Broker` 发送消息的时候,**需要先从 `NameServer` 获取关于 `Broker` 的路由信息**,然后通过 **轮询** 的方法去向每个队列中生产数据以达到 **负载均衡** 的效果。 +第二、为了保证 HA,NameServer 也做了集群部署,但它是 **去中心化** 的。也就意味着它没有主节点,可以明显看出 NameServer 的所有节点之间没有进行 `Info Replicate`。在 RocketMQ 中,**单个 Broker 和所有 NameServer 保持长连接**,并且 **每隔 30 秒** Broker 会向所有 NameServer 发送心跳,心跳包含了自身的 Topic 配置信息。NameServer **每隔 10 秒** 检查一次心跳,如果某个 Broker **超过 120 秒** 没有心跳,则认为该 Broker 已宕机。 -第四、消费者通过 `NameServer` 获取所有 `Broker` 的路由信息后,向 `Broker` 发送 `Pull` 请求来获取消息数据。`Consumer` 可以以两种模式启动—— **广播(Broadcast)和集群(Cluster)**。广播模式下,一条消息会发送给 **同一个消费组中的所有消费者** ,集群模式下消息只会发送给一个消费者。 +第三、在生产者需要向 Broker 发送消息的时候,**需要先从 NameServer 获取关于 Broker 的路由信息**,然后通过 **轮询** 的方法去向每个队列中生产数据以达到 **负载均衡** 的效果。 -## RocketMQ 功能特性 +第四、消费者通过 NameServer 获取所有 Broker 的路由信息后,向 Broker 发送 `Pull` 请求来获取消息数据。Consumer 可以以两种模式启动—— **广播(Broadcast)和集群(Cluster)**。广播模式下,一条消息会发送给 **同一个消费组中的所有消费者** ,集群模式下消息只会发送给一个消费者。 -### 消息 +## RocketMQ 消息 -#### 普通消息 +### 普通消息 普通消息一般应用于微服务解耦、事件驱动、数据集成等场景,这些场景大多数要求数据传输通道具有可靠传输的能力,且对消息的处理时机、处理顺序没有特别要求。以在线的电商交易场景为例,上游订单系统将用户下单支付这一业务事件封装成独立的普通消息并发送至 RocketMQ 服务端,下游按需从服务端订阅消息并按照本地消费逻辑处理下游任务。每个消息之间都是相互独立的,且不需要产生关联。另外还有日志系统,以离线的日志收集场景为例,通过埋点组件收集前端应用的相关操作日志,并转发到 RocketMQ 。 - - **普通消息生命周期** +```mermaid + flowchart LR + N1["初始化"] --> N2["待消费"] --> N3["消费中"] --> N4["消费提交"] --> N5["消息删除"] + + classDef default fill:#4CA497,color:#fff,rx:10,ry:10 + classDef final fill:#00838F,color:#fff,rx:10,ry:10 + + class N1,N2,N3,N4 default + class N5 final + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + - 初始化:消息被生产者构建并完成初始化,待发送到服务端的状态。 - 待消费:消息被发送到服务端,对消费者可见,等待消费者消费的状态。 - 消费中:消息被消费者获取,并按照消费者本地的业务逻辑进行处理的过程。 此时服务端会等待消费者完成消费并提交消费结果,如果一定时间后没有收到消费者的响应,RocketMQ 会对消息进行重试处理。 - 消费提交:消费者完成消费处理,并向服务端提交消费结果,服务端标记当前消息已经被处理(包括消费成功和失败)。RocketMQ 默认支持保留所有消息,此时消息数据并不会立即被删除,只是逻辑标记已消费。消息在保存时间到期或存储空间不足被删除前,消费者仍然可以回溯消息重新消费。 - 消息删除:RocketMQ 按照消息保存机制滚动清理最早的消息数据,将消息从物理文件中删除。 -#### 定时消息 +### 定时/延时消息 + +> **备注:定时消息和延时消息本质相同,都是服务端根据消息设置的定时时间在某一固定时刻将消息投递给消费者消费。** + +在分布式定时调度触发、任务超时处理等场景,需要实现精准、可靠的定时事件触发。使用 RocketMQ 的定时消息可以简化定时调度任务的开发逻辑,实现高性能、可扩展、高可靠的定时触发能力。 -在分布式定时调度触发、任务超时处理等场景,需要实现精准、可靠的定时事件触发。使用 RocketMQ 的定时消息可以简化定时调度任务的开发逻辑,实现高性能、可扩展、高可靠的定时触发能力。定时消息仅支持在 MessageType 为 Delay 的主题内使用,即定时消息只能发送至类型为定时消息的主题中,发送的消息的类型必须和主题的类型一致。在 4.x 版本中,只支持延时消息,默认分为 18 个等级分别为:1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h,也可以在配置文件中增加自定义的延时等级和时长。在 5.x 版本中,开始支持定时消息,在构造消息时提供了 3 个 API 来指定延迟时间或定时时间。 +**典型场景一:分布式定时调度** + +在分布式定时调度场景下,需要实现各类精度的定时任务,例如每天 5 点执行文件清理,每隔 2 分钟触发一次消息推送等需求。传统基于数据库的定时调度方案在分布式场景下,性能不高,实现复杂。 + +**典型场景二:任务超时处理** + +以电商交易场景为例,订单下单后暂未支付,此时不可以直接关闭订单,而是需要等待一段时间后才能关闭订单。使用 RocketMQ 定时消息可以实现超时任务的检查触发。 基于定时消息的超时任务处理具备如下优势: - **精度高、开发门槛低**:基于消息通知方式不存在定时阶梯间隔。可以轻松实现任意精度事件触发,无需业务去重。 - **高性能可扩展**:传统的数据库扫描方式较为复杂,需要频繁调用接口扫描,容易产生性能瓶颈。RocketMQ 的定时消息具有高并发和水平扩展的能力。 - +**定时时间设置原则** + +RocketMQ 定时消息设置的定时时间是一个预期触发的系统时间戳,延时时间也需要转换成当前系统时间后的某一个时间戳,而不是一段延时时长。 + +- **时间格式**:毫秒级的 Unix 时间戳 +- **定时时长最大值**:默认为 24 小时,不支持自定义修改 +- **定时时间必须设置在当前时间之后**,否则定时不生效,服务端会立即投递消息 + +**示例**: + +- 定时消息:当前系统时间为 2022-06-09 17:30:00,希望消息在 19:20:00 投递,则定时时间戳为 1654773600000 +- 延时消息:当前系统时间为 2022-06-09 17:30:00,希望延时 1 小时后投递,则定时时间戳为 1654770600000 + +**4.x 版本与 5.x 版本的区别** + +- **4.x 版本**:只支持延时消息,默认分为 18 个等级(1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h),也可以在配置文件中增加自定义的延时等级和时长。 +- **5.x 版本**:支持任意精度的定时消息,通过设置定时时间戳(毫秒级)来实现。底层采用了 **时间轮(TimingWheel)** 算法来高效管理大量定时任务,相比 4.x 版本的固定等级方式,大幅提升了灵活性和精度。 **定时消息生命周期** -- 初始化:消息被生产者构建并完成初始化,待发送到服务端的状态。 -- 定时中:消息被发送到服务端,和普通消息不同的是,服务端不会直接构建消息索引,而是会将定时消息**单独存储在定时存储系统中**,等待定时时刻到达。 -- 待消费:定时时刻到达后,服务端将消息重新写入普通存储引擎,对下游消费者可见,等待消费者消费的状态。 -- 消费中:消息被消费者获取,并按照消费者本地的业务逻辑进行处理的过程。 此时服务端会等待消费者完成消费并提交消费结果,如果一定时间后没有收到消费者的响应,RocketMQ 会对消息进行重试处理。 -- 消费提交:消费者完成消费处理,并向服务端提交消费结果,服务端标记当前消息已经被处理(包括消费成功和失败)。RocketMQ 默认支持保留所有消息,此时消息数据并不会立即被删除,只是逻辑标记已消费。消息在保存时间到期或存储空间不足被删除前,消费者仍然可以回溯消息重新消费。 -- 消息删除:Apache RocketMQ 按照消息保存机制滚动清理最早的消息数据,将消息从物理文件中删除。 +```mermaid + flowchart LR + T1["初始化"] --> T2["定时中"] --> T3["待消费"] --> T4["消费中"] --> T5["消费提交"] --> T6["消息删除"] + + classDef default fill:#E99151,color:#fff,rx:10,ry:10 + classDef final fill:#00838F,color:#fff,rx:10,ry:10 + + class T1,T2,T3,T4,T5 default + class T6 final + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + +- **初始化**:消息被生产者构建并完成初始化,待发送到服务端的状态。 +- **定时中**:消息被发送到服务端,和普通消息不同的是,服务端不会直接构建消息索引,而是会将定时消息**单独存储在定时存储系统中**,等待定时时刻到达。 +- **待消费**:定时时刻到达后,服务端将消息重新写入普通存储引擎,对下游消费者可见,等待消费者消费的状态。 +- **消费中**:消息被消费者获取,并按照消费者本地的业务逻辑进行处理的过程。此时服务端会等待消费者完成消费并提交消费结果,如果一定时间后没有收到消费者的响应,RocketMQ 会对消息进行重试处理。 +- **消费提交**:消费者完成消费处理,并向服务端提交消费结果,服务端标记当前消息已经被处理(包括消费成功和失败)。RocketMQ 默认支持保留所有消息,此时消息数据并不会立即被删除,只是逻辑标记已消费。消息在保存时间到期或存储空间不足被删除前,消费者仍然可以回溯消息重新消费。 +- **消息删除**:Apache RocketMQ 按照消息保存机制滚动清理最早的消息数据,将消息从物理文件中删除。 + +**使用限制** + +1. **消息类型一致性**:定时消息仅支持在 MessageType 为 Delay 的主题内使用 +2. **定时精度约束**:定时时长参数精确到毫秒级,但默认精度为 1000ms(秒级精度) + +**使用建议** 定时消息的实现逻辑需要先经过定时存储等待触发,定时时间到达后才会被投递给消费者。因此,如果将大量定时消息的定时时间设置为同一时刻,则到达该时刻后会有大量消息同时需要被处理,会造成系统压力过大,导致消息分发延迟,影响定时精度。 -#### 顺序消息 +### 顺序消息 + +**什么是顺序消息** + +顺序消息是 Apache RocketMQ 提供的一种高级消息类型,支持消费者按照发送消息的先后顺序获取消息,从而实现业务场景中的顺序处理。 + +**应用场景** + +在有序事件处理、撮合交易、数据实时增量同步等场景下,异构系统间需要维持强一致的状态同步,上游的事件变更需要按照顺序传递到下游进行处理。 + +- **撮合交易**:以证券、股票交易撮合场景为例,对于出价相同的交易单,坚持按照先出价先交易的原则,下游处理订单的系统需要严格按照出价顺序来处理订单。 +- **数据实时增量同步**:以数据库变更增量同步场景为例,上游源端数据库按需执行增删改操作,将二进制操作日志作为消息,通过 RocketMQ 传输到下游搜索系统,下游系统按顺序还原消息数据,实现状态数据按序刷新。 + +**如何保证消息的顺序性** + +RocketMQ 的消息顺序性分为两部分:**生产顺序性**和**消费顺序性**。 + +**生产顺序性** + +如需保证消息生产的顺序性,则必须满足以下条件: + +1. **单一生产者**:消息生产的顺序性仅支持单一生产者 +2. **串行发送**:生产者使用多线程并行发送时,不同线程间产生的消息将无法判定其先后顺序 + +满足以上条件的生产者,将顺序消息发送至 RocketMQ 后,会保证设置了同一**消息组**的消息,按照发送顺序存储在同一队列中。 + +**消息组(MessageGroup)** + +RocketMQ 顺序消息的顺序关系通过消息组(MessageGroup)判定和识别,发送顺序消息时需要为每条消息设置归属的消息组。 + +- **相同消息组**的多条消息之间遵循先进先出的顺序关系 +- **不同消息组**、无消息组的消息之间不涉及顺序性 + +基于消息组的顺序判定逻辑,支持按照业务逻辑做细粒度拆分,可以在满足业务局部顺序的前提下提高系统的并行度和吞吐能力。 + +```mermaid +flowchart TB + subgraph Order["订单系统"] + style Order fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + O1["订单A
消息组: orderA"] + O2["订单B
消息组: orderB"] + O3["订单C
消息组: orderC"] + end + + subgraph Queue["队列"] + style Queue fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + Q["队列1
(混合存储不同消息组)"] + end + + subgraph Storage["存储顺序"] + style Storage fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + direction LR + S1["orderA-M1
↓"] + S2["orderB-M1
↓"] + S3["orderA-M2
↓"] + S4["orderC-M1
↓"] + S5["orderB-M2
↓"] + end + + O1 --> Q + O2 --> Q + O3 --> Q + Q --> Storage + + classDef orderA fill:#4CA497,color:#fff,rx:10,ry:10 + classDef orderB fill:#E99151,color:#fff,rx:10,ry:10 + classDef orderC fill:#7E57C2,color:#fff,rx:10,ry:10 + classDef queue fill:#00838F,color:#fff,rx:10,ry:10 + classDef storage fill:#FFC107,color:#333,rx:10,ry:10 + + class O1 orderA + class O2 orderB + class O3 orderC + class Q queue + class S1,S2,S3,S4,S5 storage + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + +**说明**: + +- orderA 消息组的 M1、M2 保持顺序 +- orderB 消息组的 M1、M2 保持顺序 +- 不同消息组可以混合存储在同一个队列中 -顺序消息仅支持使用 MessageType 为 FIFO 的主题,即顺序消息只能发送至类型为顺序消息的主题中,发送的消息的类型必须和主题的类型一致。和普通消息发送相比,顺序消息发送必须要设置消息组。(推荐实现 MessageQueueSelector 的方式,见下文)。要保证消息的顺序性需要单一生产者串行发送。 +**消费顺序性** -单线程使用 MessageListenerConcurrently 可以顺序消费,多线程环境下使用 MessageListenerOrderly 才能顺序消费。 +如需保证消息消费的顺序性,则必须满足以下条件: -#### 事务消息 +1. **投递顺序**:RocketMQ 通过客户端 SDK 和服务端通信协议保障消息按照服务端存储顺序投递 +2. **有限重试**:顺序消息投递仅在重试次数限定范围内,超过最大重试次数后将不再重试,跳过这条消息消费 -事务消息是 Apache RocketMQ 提供的一种高级消息类型,支持在分布式场景下保障消息生产和本地事务的最终一致性。简单来讲,就是将本地事务(数据库的 DML 操作)与发送消息合并在同一个事务中。例如,新增一个订单。在事务未提交之前,不发送订阅的消息。发送消息的动作随着事务的成功提交而发送,随着事务的回滚而取消。当然真正地处理过程不止这么简单,包含了半消息、事务监听和事务回查等概念,下面有更详细的说明。 +**消费者类型对顺序消费的影响** -## 关于发送消息 +- **PushConsumer**:RocketMQ 保证消息按照存储顺序一条一条投递给消费者 +- **SimpleConsumer**:消费者可能一次拉取多条消息,此时消息消费的顺序性需要由业务方自行保证 -### **不建议单一进程创建大量生产者** +**生产顺序性和消费顺序性组合** + +| 生产顺序 | 消费顺序 | 顺序性效果 | +| ---------------------------- | -------- | -------------------------------- | +| 设置消息组,保证消息顺序发送 | 顺序消费 | 按照消息组粒度,严格保证消息顺序 | +| 设置消息组,保证消息顺序发送 | 并发消费 | 并发消费,尽可能按时间顺序处理 | +| 未设置消息组,消息乱序发送 | 顺序消费 | 按队列存储粒度,严格顺序 | +| 未设置消息组,消息乱序发送 | 并发消费 | 并发消费,尽可能按照时间顺序处理 | + +**使用限制** + +1. **消息类型一致性**:顺序消息仅支持在 MessageType 为 FIFO 的主题内使用 +2. 顺序消息消费失败进行消费重试时,为保障消息的顺序性,后续消息不可被消费,必须等待前面的消息消费完成后才能被处理 + +**使用建议** + +1. **串行消费**:消息消费建议串行处理,避免一次消费多条消息导致乱序 +2. **消息组尽可能打散**:建议将业务以消息组粒度进行拆分,例如将订单 ID、用户 ID 作为消息组关键字,可实现同一终端用户的消息按照顺序处理,不同用户的消息无需保证顺序 + +### 事务消息 + +**什么是事务消息** + +事务消息是 Apache RocketMQ 提供的一种高级消息类型,支持在分布式场景下保障消息生产和本地事务的最终一致性。简单来讲,就是将本地事务(数据库的 DML 操作)与发送消息合并在同一个事务中。 + +**应用场景** + +在分布式系统调用的特点为一个核心业务逻辑的执行,同时需要调用多个下游业务进行处理。如何保证核心业务和多个下游业务的执行结果完全一致,是分布式事务需要解决的主要问题。 + +以电商交易场景为例,用户支付订单这一核心操作的同时会涉及到下游物流发货、积分变更、购物车状态清空等多个子系统的变更: + +- **主分支订单系统状态更新**:由未支付变更为支付成功 +- **物流系统状态新增**:新增待发货物流记录,创建订单物流记录 +- **积分系统状态变更**:变更用户积分,更新用户积分表 +- **购物车系统状态变更**:清空购物车,更新用户购物车记录 + +**传统方案的问题** + +- **传统 XA 事务方案**:基于 XA 协议的分布式事务系统可以实现一致性,但多分支环境下资源锁定范围大,并发度低 +- **基于普通消息方案**:普通消息和订单事务无法保证一致,容易出现消息发送成功但订单没有执行成功、订单执行成功但消息没有发送成功等情况 + +**RocketMQ 事务消息方案** + +RocketMQ 事务消息的方案,具备高性能、可扩展、业务开发简单的优势,支持二阶段的提交能力,将二阶段提交和本地事务绑定,实现全局提交结果的一致性。 + +**事务消息处理流程** + +```mermaid +flowchart TB + subgraph Phase1["阶段一: 发送半事务消息"] + direction TB + style Phase1 fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + M1["生产者构建消息"] --> M2["发送至服务端"] + M2 --> M3["服务端持久化消息"] + M3 --> M4["返回 Ack 确认"] + M4 --> M5["消息标记为
'暂不能投递'
(半事务消息)"] + end + + subgraph Phase2["阶段二: 执行本地事务"] + direction TB + style Phase2 fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + L1["生产者开始执行
本地事务逻辑"] --> L2{"本地事务
执行结果"} + L2 -->|Commit| L3["提交二次确认 Commit"] + L2 -->|Rollback| L4["提交二次确认 Rollback"] + L2 -->|Unknown| L5["等待事务回查"] + end + + subgraph Phase3["阶段三: 事务回查机制"] + direction TB + style Phase3 fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + C1["服务端未收到确认
或收到 Unknown"] --> C2["固定时间后
发起消息回查"] + C2 --> C3["生产者检查本地事务
最终状态"] + C3 --> C4["再次提交二次确认"] + end + + subgraph Result["最终处理"] + style Result fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + direction TB + R1["Commit: 消息投递给消费者"] + R2["Rollback: 回滚事务
不投递消息"] + end + + Phase1 --> Phase2 + L3 --> R1 + L4 --> R2 + L5 --> Phase3 + C4 --> R1 + + classDef normal fill:#4CA497,color:#fff,rx:10,ry:10 + classDef decision fill:#E99151,color:#fff,rx:10,ry:10 + classDef result fill:#00838F,color:#fff,rx:10,ry:10 + + class M1,M2,M3,M4,M5,L1,C1,C2,C3,C4 normal + class L2,L3,L4,L5 decision + class R1,R2 result + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + +1. 生产者将消息发送至 RocketMQ 服务端 +2. 服务端将消息持久化成功之后,向生产者返回 Ack 确认消息已经发送成功,此时消息被标记为"暂不能投递",这种状态下的消息即为**半事务消息** +3. 生产者开始执行本地事务逻辑 +4. 生产者根据本地事务执行结果向服务端提交二次确认结果(Commit 或 Rollback) +5. 如果服务端未收到二次确认结果,或收到的结果为 Unknown,经过固定时间后,服务端将对消息生产者发起**消息回查** +6. 生产者收到消息回查后,需要检查对应消息的本地事务执行的最终结果 +7. 生产者根据检查到的本地事务的最终状态再次提交二次确认 + +**事务消息生命周期** + +- **初始化**:半事务消息被生产者构建并完成初始化,待发送到服务端的状态 +- **事务待提交**:半事务消息被发送到服务端,并不会直接被服务端持久化,而是会被单独存储到事务存储系统中,等待第二阶段本地事务返回执行结果后再提交。此时消息对下游消费者不可见 +- **消息回滚**:第二阶段如果事务执行结果明确为回滚,服务端会将半事务消息回滚,该事务消息流程终止 +- **提交待消费**:第二阶段如果事务执行结果明确为提交,服务端会将半事务消息重新存储到普通存储系统中,此时消息对下游消费者可见 +- **消费中**:消息被消费者获取,并按照消费者本地的业务逻辑进行处理的过程 +- **消费提交**:消费者完成消费处理,并向服务端提交消费结果 +- **消息删除**:RocketMQ 按照消息保存机制滚动清理最早的消息数据 + +**使用限制** + +1. **消息类型一致性**:事务消息仅支持在 MessageType 为 Transaction 的主题内使用 +2. **消费事务性**:RocketMQ 事务消息保证本地主分支事务和下游消息发送事务的一致性,但不保证消息消费结果和上游事务的一致性 +3. **中间状态可见性**:事务消息为最终一致性,即消息提交到下游消费端处理完成之前,下游分支和上游事务之间的状态会不一致 +4. **事务超时机制**:事务消息的生命周期存在超时机制,半事务消息被生产者发送服务端后,如果在指定时间内服务端无法确认提交或者回滚状态,则消息默认会被回滚 +5. **事务回查机制**:服务端默认 **每隔 60 秒** 对未确认的半事务消息发起回查,**最多回查 15 次**。超过最大回查次数后,消息将被丢弃或进入死信队列 + +**使用建议** + +1. **避免大量未决事务导致超时**:生产者应该尽量避免本地事务返回未知结果,大量的事务检查会导致系统性能受损 +2. **正确处理"进行中"的事务**:消息回查时,对于正在进行中的事务不要返回 Rollback 或 Commit 结果,应继续保持 Unknown 的状态 + +### 关于发送消息 + +#### 不建议单一进程创建大量生产者 Apache RocketMQ 的生产者和主题是多对多的关系,支持同一个生产者向多个主题发送消息。对于生产者的创建和初始化,建议遵循够用即可、最大化复用原则,如果有需要发送消息到多个主题的场景,无需为每个主题都创建一个生产者。 -### **不建议频繁创建和销毁生产者** +#### 不建议频繁创建和销毁生产者 Apache RocketMQ 的生产者是可以重复利用的底层资源,类似数据库的连接池。因此不需要在每次发送消息时动态创建生产者,且在发送结束后销毁生产者。这样频繁的创建销毁会在服务端产生大量短连接请求,严重影响系统性能。 @@ -344,30 +951,77 @@ p.shutdown(); ## 消费者分类 -### PushConsumer +### PushConsumer(推模式消费者) + +**核心特点:** 高度封装的消费者类型,消费消息仅仅通过消费监听器监听并返回结果。消息的获取、消费状态提交以及消费重试都通过 RocketMQ 的客户端 SDK 完成。 -PushConsumer 的消费监听器执行结果分为以下三种情况: +**适用场景:** + +- 消息处理时间可预估 +- 无异步化、高级定制需求 +- 希望快速开发的场景 + +**使用示例:** + +```java +public static void main(String[] args) throws InterruptedException, MQClientException { + // 创建 Push 模式消费者 + DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("CID_JODIE_1"); + + // 订阅主题 + consumer.subscribe("TopicTest", "*"); + + // 设置从哪里开始消费 + consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET); + + // 注册消息监听器 + consumer.registerMessageListener(new MessageListenerConcurrently() { + @Override + public ConsumeConcurrentlyStatus consumeMessage( + List
消费队列1、2"] + CG --> C2["消费者2
消费队列3、4"] + CG --> C3["消费者3
空闲"] + Note1["任意一条消息
只需被消费组内
任意一个消费者处理"] + end + + subgraph Broadcast["广播消费模式"] + direction TB + style Broadcast fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + BG["消费者组"] --> B1["消费者1
消费所有消息"] + BG --> B2["消费者2
消费所有消息"] + BG --> B3["消费者3
消费所有消息"] + Note2["每条消息
推送给消费组
所有消费者"] + end + + %% 优化:调整注释连线,避免跨子图渲染异常 + C1 -.-> Note1 + C2 -.-> Note1 + C3 -.-> Note1 + B1 -.-> Note2 + B2 -.-> Note2 + B3 -.-> Note2 + end + + classDef cg fill:#4CA497,color:#fff,rx:10,ry:10 + classDef consumer fill:#E99151,color:#fff,rx:10,ry:10 + classDef note fill:#00838F,color:#fff,rx:10,ry:10 + + class CG,BG cg + class C1,C2,C3,B1,B2,B3 consumer + class Note1,Note2 note + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + 消费者分组中的订阅关系、投递顺序性、消费重试策略是一致的。 - 订阅关系:Apache RocketMQ 以消费者分组的粒度管理订阅关系,实现订阅关系的管理和追溯。 @@ -433,29 +1256,37 @@ RocketMQ 服务端 5.x 版本:上述消费者的消费行为从关联的消费 RocketMQ 服务端 3.x/4.x 历史版本:上述消费逻辑由消费者客户端接口定义,因此,您需要自己在消费者客户端设置时保证同一分组下的消费者的消费行为一致。(来自官方网站) +**两种消费模式对比:** + +| 对比维度 | 集群消费模式 | 广播消费模式 | +| ------------ | ---------------------------------------------- | ------------------------------------ | +| **消息消费** | 任意一条消息只需被消费组内的任意一个消费者处理 | 每条消息推送给消费组所有消费者 | +| **扩缩容** | 可通过扩缩消费者数量来提升或降低消费能力 | 扩缩消费者数量无法提升或降低消费能力 | +| **适用场景** | 需要提升消费能力、避免重复消费 | 需要所有消费者都收到消息 | + ## 如何解决顺序消费和重复消费? -其实,这些东西都是我在介绍消息队列带来的一些副作用的时候提到的,也就是说,这些问题不仅仅挂钩于 `RocketMQ` ,而是应该每个消息中间件都需要去解决的。 +其实,这些东西都是我在介绍消息队列带来的一些副作用的时候提到的,也就是说,这些问题不仅仅挂钩于 RocketMQ ,而是应该每个消息中间件都需要去解决的。 -在上面我介绍 `RocketMQ` 的技术架构的时候我已经向你展示了 **它是如何保证高可用的** ,这里不涉及运维方面的搭建,如果你感兴趣可以自己去官网上照着例子搭建属于你自己的 `RocketMQ` 集群。 +在上面我介绍 RocketMQ 的技术架构的时候我已经向你展示了 **它是如何保证高可用的** ,这里不涉及运维方面的搭建,如果你感兴趣可以自己去官网上照着例子搭建属于你自己的 RocketMQ 集群。 -> 其实 `Kafka` 的架构基本和 `RocketMQ` 类似,只是它注册中心使用了 `Zookeeper`、它的 **分区** 就相当于 `RocketMQ` 中的 **队列** 。还有一些小细节不同会在后面提到。 +> 其实 Kafka 的架构基本和 RocketMQ 类似,只是它注册中心使用了 Zookeeper、它的 **分区** 就相当于 RocketMQ 中的 **队列** 。还有一些小细节不同会在后面提到。 ### 顺序消费 -在上面的技术架构介绍中,我们已经知道了 **`RocketMQ` 在主题上是无序的、它只有在队列层面才是保证有序** 的。 +在上面的技术架构介绍中,我们已经知道了 **RocketMQ 在主题上是无序的、它只有在队列层面才是保证有序** 的。 这又扯到两个概念——**普通顺序** 和 **严格顺序** 。 -所谓普通顺序是指 消费者通过 **同一个消费队列收到的消息是有顺序的** ,不同消息队列收到的消息则可能是无顺序的。普通顺序消息在 `Broker` **重启情况下不会保证消息顺序性** (短暂时间) 。 +所谓普通顺序是指 消费者通过 **同一个消费队列收到的消息是有顺序的** ,不同消息队列收到的消息则可能是无顺序的。普通顺序消息在 Broker **重启情况下不会保证消息顺序性** (短暂时间) 。 所谓严格顺序是指 消费者收到的 **所有消息** 均是有顺序的。严格顺序消息 **即使在异常情况下也会保证消息的顺序性** 。 -但是,严格顺序看起来虽好,实现它可会付出巨大的代价。如果你使用严格顺序模式,`Broker` 集群中只要有一台机器不可用,则整个集群都不可用。你还用啥?现在主要场景也就在 `binlog` 同步。 +但是,严格顺序看起来虽好,实现它可会付出巨大的代价。如果你使用严格顺序模式,Broker 集群中只要有一台机器不可用,则整个集群都不可用。你还用啥?现在主要场景也就在 `binlog` 同步。 一般而言,我们的 `MQ` 都是能容忍短暂的乱序,所以推荐使用普通顺序模式。 -那么,我们现在使用了 **普通顺序模式** ,我们从上面学习知道了在 `Producer` 生产消息的时候会进行轮询(取决你的负载均衡策略)来向同一主题的不同消息队列发送消息。那么如果此时我有几个消息分别是同一个订单的创建、支付、发货,在轮询的策略下这 **三个消息会被发送到不同队列** ,因为在不同的队列此时就无法使用 `RocketMQ` 带来的队列有序特性来保证消息有序性了。 +那么,我们现在使用了 **普通顺序模式** ,我们从上面学习知道了在 Producer 生产消息的时候会进行轮询(取决你的负载均衡策略)来向同一主题的不同消息队列发送消息。那么如果此时我有几个消息分别是同一个订单的创建、支付、发货,在轮询的策略下这 **三个消息会被发送到不同队列** ,因为在不同的队列此时就无法使用 RocketMQ 带来的队列有序特性来保证消息有序性了。 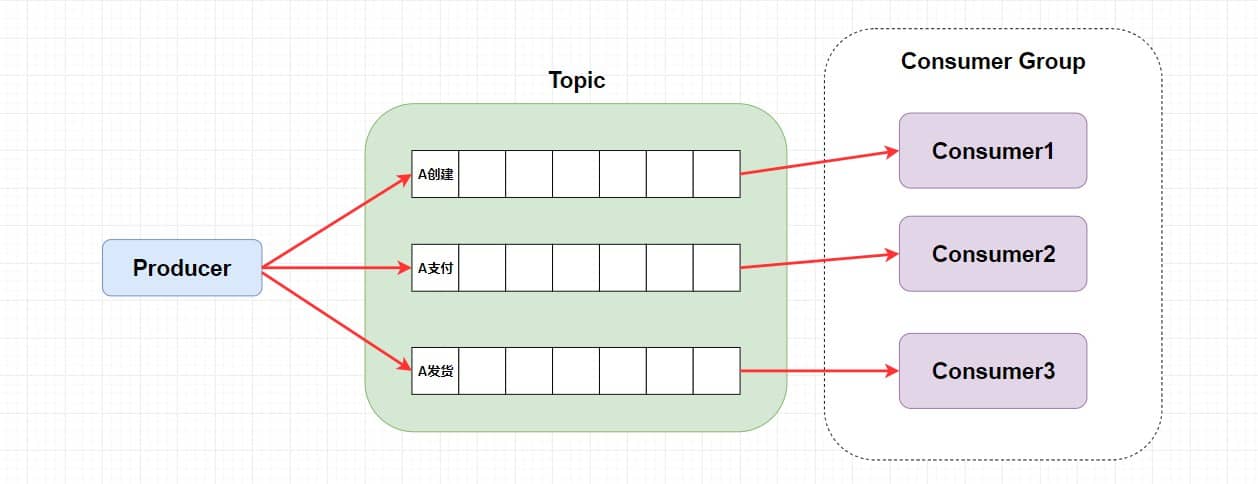 @@ -463,32 +1294,46 @@ RocketMQ 服务端 3.x/4.x 历史版本:上述消费逻辑由消费者客户 其实很简单,我们需要处理的仅仅是将同一语义下的消息放入同一个队列(比如这里是同一个订单),那我们就可以使用 **Hash 取模法** 来保证同一个订单在同一个队列中就行了。 -RocketMQ 实现了两种队列选择算法,也可以自己实现 +**4.x 版本:使用 MessageQueueSelector** + +RocketMQ 4.x 版本通过继承 `MessageQueueSelector` 来实现自定义队列选择逻辑: -- 轮询算法 +```java +SendResult sendResult = producer.send(msg, new MessageQueueSelector() { + @Override + public MessageQueue select(List
[Java后端面试重点总结](https://javaguide.cn/interview-preparation/key-points-of-interview.html) | +| 简历 | 一到两页纸、项目 STAR、技术栈与岗位匹配 | [程序员简历编写指南](https://javaguide.cn/interview-preparation/resume-guide.html) | +| 学习路线 | 查漏补缺,确定自己当前所处阶段 | [Java 学习路线(最新版,4w+ 字)](https://javaguide.cn/interview-preparation/java-roadmap.html) | +| 项目与经历 | 没有项目/实习时如何包装、怎么讲 | [项目经验指南](https://javaguide.cn/interview-preparation/project-experience-guide.html)
[校招没有实习经历怎么办?实习经历怎么写?](https://javaguide.cn/interview-preparation/internship-experience.html) | +| 心态 | 减少紧张、发挥更稳 | [面试太紧张怎么办?](https://javaguide.cn/interview-preparation/how-to-handle-interview-nerves.html) | + +**核心要点**: + +- **技术好≠面试能过**,必须系统准备——尽早以求职为导向学习,根据招聘要求制定技能清单。 +- **掌握投递简历的黄金时间**:秋招 7-9 月,春招 3-4 月;多渠道获取招聘信息(官网、招聘网站、牛客网、内推等)。 +- **花 2-3 天完善简历**,重视项目经历描述;**校招简历不超过 2 页,社招不超过 3 页**。一定要把包装润色,但也要避免简历夸大事实,面试时易被深挖暴露。 +- **八股文很有意义**,日常开发也会用到;不要抱侥幸心理,打铁还需自身硬。 +- **提前准备 1-2 分钟自我介绍话术**,能流畅讲出个人背景、技术栈和求职意向。 +- **多多自测**,可以用 AI 辅助模拟面试,找同学朋友互相模拟面试。 + +### 第一阶段:项目与简历深挖(约 1 周) + +**目标**:能清晰讲出每个项目的背景、你的角色、技术选型与难点,并能推导出「可能被问的面试题」。 + +**产出物**: + +- **项目卡片**:按简历逐条过项目,为每个项目写清——业务背景、技术栈、你负责的模块、1~2 个难点与解决方式、可量化的成果(如 QPS、耗时、节省成本)。 +- **必会题清单**:根据项目用到的技术,列出「必会题」(例如:用了 Redis 缓存→ Redis 常见数据结构、持久化机制、线程模型等;用了 MySQL → 索引、事务、慢 SQL 优化等)。可参考 [JavaGuide](https://javaguide.cn/) 网站中的面试题总结按项目拓展。 +- **话术稿**:每个项目准备 1~2 分钟版本(自我介绍用)和 3~5 分钟版本(深挖用),能流畅讲出「为什么这么选、遇到什么问题、怎么解决的」。 + +**每日建议**:每天至少梳理 1 个项目 + 对应必会题,周末做一次脱稿自测(录音或对着镜子讲)。 + +**自测**:能脱稿讲清每个项目的背景、难点和你的贡献;必会题清单里的题能答出要点,对于大厂面试要能抗住深挖,做到举一反三。 + +**没有项目经验怎么办?** + +1. **实战项目视频/专栏**:慕课网、哔哩哔哩、拉勾、极客时间等;选择适合自己能力的项目,不必强求微服务项目。[JavaGuide 官方知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)已经推出[⭐AI 智能面试辅助平台 + RAG 知识库](https://javaguide.cn/zhuanlan/interview-guide.html)和[手写 RPC 框架](https://javaguide.cn/zhuanlan/handwritten-rpc-framework.html)。并且,还分享了很多高频项目经历(如博客、外卖、线程池、短连接)的优化版介绍和面试准备。 +2. **实战类开源项目**:JavaGuide 推荐的[优质开源实战项目](https://javaguide.cn/open-source-project/practical-project.html);在理解基础上改进或增加功能。 +3. **参加大公司组织的比赛**:阿里云天池大赛等;获奖项目含金量高。 + +**项目经历写作要点(STAR 法则)**: + +- **Situation(情景)**:项目背景是什么?要解决什么问题? +- **Task(任务)**:你在项目中负责什么?你的角色是什么? +- **Action(行动)**:你具体做了什么?用了什么技术?遇到了什么问题?如何解决的? +- **Result(结果)**:取得了什么成果?最好量化(QPS 从 xxx 提高到 xxx,响应时间降低 xx%) + +**项目介绍高频问题**: + +- 技术架构直接写技术名词,不需要解释。 +- 减少纯业务描述,多挖掘技术亮点,结合具体业务场景描述。 +- 优化成果要量化(QPS、响应时间、成本节省等),非真实项目包装合理数值即可。 +- 工作内容介绍控制在 6~8 条左右比较好,多了少了都有影响,一定要至少有 3-4 条是有技术亮点的,能吸引到面试官。 +- 避免模糊性描述(如"负责开发"),要具体(技术+场景+效果)。 +- 一定要包装项目,但也不要过度包装,准备时多想“如果面试官问为什么”,确保逻辑自洽。 + +### 第二阶段:Java 核心 + MySQL + Redis (约 2~3 周) + +**优先级**:最重要的部分,面试高频考点,MySQL + Redis ≥ Java 基础/集合/并发 > 框架知识,大厂会深挖并发与底层。 + +**Java 基础** + +- [Java 基础常见面试题总结(上)](https://javaguide.cn/java/basis/java-basic-questions-01.html)、[(中)](https://javaguide.cn/java/basis/java-basic-questions-02.html)、[(下)](https://javaguide.cn/java/basis/java-basic-questions-03.html):语法与面向对象、字符串与拷贝、异常/泛型/反射/SPI/序列化/注解 + +**Java 集合** + +- [Java 集合常见面试题(上)](https://javaguide.cn/java/collection/java-collection-questions-01.html)、[(下)](https://javaguide.cn/java/collection/java-collection-questions-02.html):List/Set/Queue、HashMap、ConcurrentHashMap + +**Java 并发**(大厂必深挖) + +- [Java 并发常见面试题(上)](https://javaguide.cn/java/concurrent/java-concurrent-questions-01.html)、[(中)](https://javaguide.cn/java/concurrent/java-concurrent-questions-02.html)、[(下)](https://javaguide.cn/java/concurrent/java-concurrent-questions-03.html):线程与锁、synchronized/ReentrantLock、ThreadLocal/线程池/Future/AQS/虚拟线程 +- [JMM](https://javaguide.cn/java/concurrent/jmm.html)、[线程池详解](https://javaguide.cn/java/concurrent/java-thread-pool-summary.html)与[最佳实践](https://javaguide.cn/java/concurrent/java-thread-pool-best-practices.html) +- [ThreadLocal](https://javaguide.cn/java/concurrent/threadlocal.html)、[AQS](https://javaguide.cn/java/concurrent/aqs.html)、[CompletableFuture](https://javaguide.cn/java/concurrent/completablefuture-intro.html)、[常见并发容器](https://javaguide.cn/java/concurrent/java-concurrent-collections.html) + +**MySQL**(必看) + +- [MySQL 常见面试题总结](https://javaguide.cn/database/mysql/mysql-questions-01.html)(基础、引擎、事务、索引、锁、优化) +- [MySQL 索引详解](https://javaguide.cn/database/mysql/mysql-index.html)、[三大日志](https://javaguide.cn/database/mysql/mysql-logs.html)、[事务隔离级别](https://javaguide.cn/database/mysql/transaction-isolation-level.html) +- [InnoDB 对 MVCC 的实现](https://javaguide.cn/database/mysql/innodb-implementation-of-mvcc.html)、[SQL 执行过程](https://javaguide.cn/database/mysql/how-sql-executed-in-mysql.html) + +**Redis**(必看) + +- [Redis 常见面试题总结(上)](https://javaguide.cn/database/redis/redis-questions-01.html)、[Redis 常见面试题总结(下)](https://javaguide.cn/database/redis/redis-questions-02.html) +- [Redis 延时任务](https://javaguide.cn/database/redis/redis-delayed-task.html)、[Redis 做消息队列](https://javaguide.cn/database/redis/redis-stream-mq.html) +- [5 种基本数据类型](https://javaguide.cn/database/redis/redis-data-structures-01.html)、[3 种特殊类型](https://javaguide.cn/database/redis/redis-data-structures-02.html)、[跳表实现有序集合](https://javaguide.cn/database/redis/redis-skiplist.html) +- [持久化](https://javaguide.cn/database/redis/redis-persistence.html)、[内存碎片](https://javaguide.cn/database/redis/redis-memory-fragmentation.html)、[常见阻塞原因](https://javaguide.cn/database/redis/redis-common-blocking-problems-summary.html) + +**自测**:随机抽题,能用自己的话讲出来,不死记硬背,理解记忆,重点记关键词。尤其是要重点测试 MySQL 和 Redis 部分,面试考察重点中的重点。 + +### 第三阶段:框架和系统设计(约 1~3 周) + +#### 设计模式 + +- [设计模式常见面试题总结](https://interview.javaguide.cn/system-design/design-pattern.html) + +**自测**:掌握单例模式至少两种常见写法;代理模式、责任链模式、策略模式一定要搞懂,最好能够结合你的项目经历或者开源框架中的运用讲出来。 + +#### 框架 + +**Spring / Spring Boot** + +- [Spring 常见面试题](https://javaguide.cn/system-design/framework/spring/spring-knowledge-and-questions-summary.html)、[SpringBoot 常见面试题](https://javaguide.cn/system-design/framework/spring/springboot-knowledge-and-questions-summary.html) +- [常用注解](https://javaguide.cn/system-design/framework/spring/spring-common-annotations.html)、[IoC 与 AOP](https://javaguide.cn/system-design/framework/spring/ioc-and-aop.html)、[Spring 事务](https://javaguide.cn/system-design/framework/spring/spring-transaction.html) +- [Spring 中的设计模式](https://javaguide.cn/system-design/framework/spring/spring-design-patterns-summary.html)、[SpringBoot 自动装配](https://javaguide.cn/system-design/framework/spring/spring-boot-auto-assembly-principles.html)、[Async 原理](https://javaguide.cn/system-design/framework/spring/async.html)(原理性知识,时间不够可跳过) +- [MyBatis 常见面试题](https://javaguide.cn/system-design/framework/mybatis/mybatis-interview.html)(不重要,可跳过,考查不多)、[Netty 常见面试题](https://javaguide.cn/system-design/framework/netty.html)(用到才需要准备) + +**自测**:能说清项目里用到的 Spring 注解、IoC/AOP 在项目中的体现、事务失效场景。 + +**权限与安全** + +- [认证授权基础](https://javaguide.cn/system-design/security/basis-of-authority-certification.html)、[JWT](https://javaguide.cn/system-design/security/jwt-intro.html) 与[优缺点](https://javaguide.cn/system-design/security/advantages-and-disadvantages-of-jwt.html)、[权限系统设计](https://javaguide.cn/system-design/security/design-of-authority-system.html)、[SSO](https://javaguide.cn/system-design/security/sso-intro.html)、[常见加密算法](https://javaguide.cn/system-design/security/encryption-algorithms.html) + +#### 系统设计与场景题 + +面试官常会穿插一两道系统设计或场景题,考察整体思路和方案权衡。 + +- **系统设计 / 场景题汇总**:[系统设计常见面试题总结](https://javaguide.cn/system-design/system-design-questions.html)(付费内容在 [《后端面试高频系统设计&场景题》](https://javaguide.cn/zhuanlan/back-end-interview-high-frequency-system-design-and-scenario-questions.html) 专栏,含短链、秒杀、海量数据处理等 30+ 道)。 +- **本站可参考的设计类文章**(思路可迁移到面试口述):[定时任务](https://javaguide.cn/system-design/schedule-task.html)、[Web 实时消息推送](https://javaguide.cn/system-design/web-real-time-message-push.html)。 + + + +**自测**:能口述 1~2 个经典系统设计(如短链、秒杀、限流)的整体思路与关键取舍;场景题(如海量数据去重、第三方登录)能说出常见方案。 + +### 第四阶段:计算机基础(按目标公司安排) + +**目标字节、腾讯等重算法/基础的厂**:适当多留时间,算法与代码题要单独刷(LeetCode 热题、剑指 Offer 等等);**目标中小厂**:可压缩或后置。 + +- **算法与代码题**(面字节、快手等必留时间):[剑指 Offer 题解](https://javaguide.cn/cs-basics/algorithms/the-sword-refers-to-offer.html)、LeetCode 热题 100、常见手写(如 LRU、生产者消费者、单例等)。建议每天至少 1 道,保持手感。 +- **网络**:[计网常见面试题(上)](https://javaguide.cn/cs-basics/network/other-network-questions.html)、[(下)](https://javaguide.cn/cs-basics/network/other-network-questions2.html)、[访问网页全过程](https://javaguide.cn/cs-basics/network/the-whole-process-of-accessing-web-pages.html)、[应用层常见协议](https://javaguide.cn/cs-basics/network/application-layer-protocol.html)、[HTTP/HTTPS](https://javaguide.cn/cs-basics/network/http-vs-https.html)、[HTTP 1.0 vs 1.1](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html)、[DNS](https://javaguide.cn/cs-basics/network/dns.html)、[TCP 三次握手与四次挥手](https://javaguide.cn/cs-basics/network/tcp-connection-and-disconnection.html)、[TCP 可靠性](https://javaguide.cn/cs-basics/network/tcp-reliability-guarantee.html)、[ARP](https://javaguide.cn/cs-basics/network/arp.html) +- **操作系统**:[操作系统常见面试题(上)](https://javaguide.cn/cs-basics/operating-system/operating-system-basic-questions-01.html)、[(下)](https://javaguide.cn/cs-basics/operating-system/operating-system-basic-questions-02.html)、[Linux 基础](https://javaguide.cn/cs-basics/operating-system/linux-intro.html) +- **数据结构**:[数组/链表/栈/队列](https://javaguide.cn/cs-basics/data-structure/linear-data-structure.html)、[图](https://javaguide.cn/cs-basics/data-structure/graph.html)、[堆](https://javaguide.cn/cs-basics/data-structure/heap.html)、[树](https://javaguide.cn/cs-basics/data-structure/tree.html)、[红黑树](https://javaguide.cn/cs-basics/data-structure/red-black-tree.html)、[布隆过滤器](https://javaguide.cn/cs-basics/data-structure/bloom-filter.html) + +**自测**:能画访问网页全过程、TCP 握手挥手等等;算法题能手写常见套路;OS 进程/线程、内存、死锁能说清概念与例子。 + +### 第五阶段:分布式与高并发(按简历与岗位) + +若简历或岗位涉及分布式/微服务/高并发,再系统过一遍;否则可只过「项目会用到的点」。 + +- **分布式理论**:[CAP 与 BASE](https://javaguide.cn/distributed-system/protocol/cap-and-base-theorem.html)、[Paxos](https://javaguide.cn/distributed-system/protocol/paxos-algorithm.html)、[Raft](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html)、[ZAB](https://javaguide.cn/distributed-system/protocol/zab.html)、[Gossip](https://javaguide.cn/distributed-system/protocol/gossip-protocol.html)、[一致性哈希](https://javaguide.cn/distributed-system/protocol/consistent-hashing.html) +- **RPC**:[RPC 基础](https://javaguide.cn/distributed-system/rpc/rpc-intro.html)、[Dubbo](https://javaguide.cn/distributed-system/rpc/dubbo.html)(目前问的很少,可跳过) +- **分布式 ID / 网关 / 锁 / 事务**(项目涉及再重点看):[分布式 ID](https://javaguide.cn/distributed-system/distributed-id.html)、[设计指南](https://javaguide.cn/distributed-system/distributed-id-design.html)、[API 网关](https://javaguide.cn/distributed-system/api-gateway.html)、[Spring Cloud Gateway](https://javaguide.cn/distributed-system/spring-cloud-gateway-questions.html)、[分布式锁](https://javaguide.cn/distributed-system/distributed-lock-implementations.html)、[分布式事务](https://javaguide.cn/distributed-system/distributed-transaction.html) +- **高并发**(项目涉及再重点看):[CDN](https://javaguide.cn/high-performance/cdn.html)、[读写分离与分库分表](https://javaguide.cn/high-performance/read-and-write-separation-and-library-subtable.html)、[冷热分离](https://javaguide.cn/high-performance/data-cold-hot-separation.html)、[SQL 优化](https://javaguide.cn/high-performance/sql-optimization.html)、[深度分页](https://javaguide.cn/high-performance/deep-pagination-optimization.html)、[负载均衡](https://javaguide.cn/high-performance/load-balancing.html) +- **高可用**(项目涉及再重点看):[高可用系统设计](https://javaguide.cn/high-availability/high-availability-system-design.html)、[限流](https://javaguide.cn/high-availability/limit-request.html)、[熔断与降级](https://javaguide.cn/high-availability/fallback-and-circuit-breaker.html)、[超时与重试](https://javaguide.cn/high-availability/timeout-and-retry.html)、[幂等设计](https://javaguide.cn/high-availability/idempotency.html)、[冗余设计](https://javaguide.cn/high-availability/redundancy.html) +- **消息队列**(项目涉及再重点看):[MQ 基础](https://javaguide.cn/high-performance/message-queue/message-queue.html)、[Disruptor](https://javaguide.cn/high-performance/message-queue/disruptor-questions.html)、[RabbitMQ](https://javaguide.cn/high-performance/message-queue/rabbitmq-questions.html)、[RocketMQ](https://javaguide.cn/high-performance/message-queue/rocketmq-questions.html)、[Kafka](https://javaguide.cn/high-performance/message-queue/kafka-questions-01.html) + +**自测**:能讲清项目里用到的分布式方案(如分布式锁、ID、MQ)及选型理由;CAP/BASE、一致性哈希等能举例说明。 + +### 第六阶段:JVM(大厂 / 部分中厂) + +目标阿里、美团、携程、顺丰、招银等可重点看;面国企或小厂可跳过。 + +- [Java 内存区域](https://javaguide.cn/java/jvm/memory-area.html)、[JVM 垃圾回收](https://javaguide.cn/java/jvm/jvm-garbage-collection.html) +- [类文件结构](https://javaguide.cn/java/jvm/class-file-structure.html)、[类加载过程](https://javaguide.cn/java/jvm/class-loading-process.html)、[类加载器](https://javaguide.cn/java/jvm/classloader.html) +- 结合[星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)的 [常见线上问题案例](https://t.zsxq.com/0bsAac47U) 理解调优与排查(也可以参考这篇 [JVM 线上问题排查和性能调优案例](https://javaguide.cn/java/jvm/jvm-in-action.html)) + +**自测**:能说清内存区域、常见 GC 器与回收过程、类加载与双亲委派;能结合项目或案例讲一次 GC 调优或 OOM 排查思路。 + +**Java 新特性**(按岗位要求选读):[Java 11](https://javaguide.cn/java/new-features/java11.html)、[Java 17](https://javaguide.cn/java/new-features/java17.html)、[Java 21](https://javaguide.cn/java/new-features/java21.html) + +### 面试前 1~2 天冲刺清单 + +临近面试时优先做这几件事,避免临时抱佛脚方向散乱: + +| 事项 | 说明 | +| ----------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------- | +| 过一遍必会题 | 重点看你第一阶段整理的「项目相关必会题」+ 简历上写的「熟练掌握」对应的考点,能口头复述要点即可。 | +| 练一遍项目话术 | 每个项目 1 分钟版、3 分钟版各讲一遍,卡壳的地方记下来再顺一遍。 | +| 目标公司/岗位倾向 | 翻一下该公司或同类型岗位的面经,看有没有偏重(如算法、计网、项目深挖),针对性过一眼。 | +| 心态与状态 | 早睡、准备好设备(线上面试)或路线(现场),可看 [面试太紧张怎么办?](https://javaguide.cn/interview-preparation/how-to-handle-interview-nerves.html)。 | + +面试结束后建议做一次简短复盘:哪些题答得不好、哪些没准备到,补充进必会题清单,下一场前重点过一遍。 diff --git a/docs/interview-preparation/how-to-handle-interview-nerves.md b/docs/interview-preparation/how-to-handle-interview-nerves.md index 1a1a79409f9..d46a28716f2 100644 --- a/docs/interview-preparation/how-to-handle-interview-nerves.md +++ b/docs/interview-preparation/how-to-handle-interview-nerves.md @@ -1,12 +1,21 @@ --- title: 面试太紧张怎么办? +description: 面试太紧张影响发挥怎么办?从心态调整、提前准备到模拟面试与表达训练,提供一套可落地的方法,帮助你降低焦虑、提升临场表现,更稳定地通过技术面试。 category: 面试准备 icon: security-fill +head: + - - meta + - name: keywords + content: 面试紧张,技术面试,面试心态,临场发挥,模拟面试,表达训练,面试准备,校招 --- -很多小伙伴在第一次技术面试时都会感到紧张甚至害怕,面试结束后还会有种“懵懵的”感觉。我也经历过类似的状况,可以说是深有体会。其实,**紧张是很正常的**——它代表你对面试的重视,也来自于对未知结果的担忧。但如果过度紧张,反而会影响你的临场发挥。 + -下面,我就分享一些自己的心得,帮大家更好地应对面试中的紧张情绪。 +很多小伙伴在第一次技术面试时都会感到紧张甚至害怕,遇到稍微刁钻的问题大脑就一片空白,面试结束后还会有种“懵懵的”感觉。我也经历过类似的状况,对这种手心出汗、语无伦次的窘境深有体会。 + +其实,**紧张是非常正常的生理和心理反应**——它代表你对这次机会的重视,也源于人类对未知结果的天然担忧。但如果任由过度紧张蔓延,绝对会大幅折损你的临场发挥水平。 + +下面,我将结合自己的实战经验,从**心态重塑、战术准备、临场应对、面后复盘**四个维度,分享一套可落地的“抗紧张”指南。 ## 试着接受紧张情绪,调整心态 @@ -22,13 +31,13 @@ icon: security-fill ### 认真准备技术面试 -- **优先梳理核心知识点**:比如计算基础、数据库、Java 基础、Java 集合、并发编程、SpringBoot(这里以 Java 后端方向为例)等。如果时间不够,可以分轻重缓急,有重点地复习。强烈推荐阅读一下 [Java 面试重点总结(重要)](https://javaguide.cn/interview-preparation/key-points-of-interview.html)这篇文章。 +- **优先梳理核心知识点**:比如计算基础、数据库、Java 基础、Java 集合、并发编程、SpringBoot(这里以 Java 后端方向为例)等。如果时间不够,可以分轻重缓急,有重点地复习。如果你想要系统准备 Java 后端面试但又不知道如何开始的,可以参考 [Java 后端面试通关计划(后端通用)](https://javaguide.cn/interview-preparation/backend-interview-plan.html)。 - **精心准备项目经历**:认真思考你简历上最重要的项目(面试以前两个项目为主,尤其是第一个),它们的技术难点、业务逻辑、架构设计,以及可能被面试官深挖的点。把你的思考总结成可能出现的面试问题,并尝试回答。 ### 模拟面试和自测 - **约朋友或同学互相提问**:以真实的面试场景来进行演练,并及时对回答进行诊断和反馈。 -- **线上练习**:很多平台都提供 AI 模拟面试,能比较真实地模拟面试官提问情境。 +- **线上练习**:直接利用 AI 来进行模拟面试即可,免费且高效。把自己的简历投喂给它,让它根据你的简历,尤其是项目经历生成面试问题。 - **面经**:平时可以多看一些前辈整理的面经,尤其是目标岗位或目标公司的面经,总结高频考点和常见问题。 - **技术面试题自测**:在 [《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的 「技术面试题自测篇」 ,我总结了 Java 面试中最重要的知识点的最常见的面试题并按照面试提问的方式展现出来。其中,每一个问题都有提示和重要程度说明,非常适合用来自测。 diff --git a/docs/interview-preparation/internship-experience.md b/docs/interview-preparation/internship-experience.md index 4e16fc7e0b5..719c0e5c31f 100644 --- a/docs/interview-preparation/internship-experience.md +++ b/docs/interview-preparation/internship-experience.md @@ -1,12 +1,21 @@ --- -title: 校招没有实习经历怎么办? +title: 校招没有实习经历怎么办?实习经历怎么写? +description: 校招没有实习经历也能上岸:从补强项目经验、持续优化简历到系统准备技术面试,给出可执行的提升路径与注意事项,帮助你在没有大厂实习的情况下提高面试通过率。 category: 面试准备 icon: experience +head: + - - meta + - name: keywords + content: 校招,实习经历,没有实习怎么办,项目经验,简历优化,技术面试准备,Java后端,秋招 --- + + 由于目前的面试太卷,对于犹豫是否要找实习的同学来说,个人建议不论是本科生还是研究生都应该在参加校招面试之前,争取一下不错的实习机会,尤其是大厂的实习机会,日常实习或者暑期实习都可以。当然,如果大厂实习面不上,中小厂实习也是可以接受的。 -不过,现在的实习是真难找,今年有非常多的同学没有找到实习,有一部分甚至是 211/985 名校的同学。 +不过,现在的实习是真难找,这两年有非常多的同学没有找到实习,有一部分甚至是 211/985 名校的同学。实习难找是一方面原因,国内很多学校的导师压根不放实习,这也是很棘手的问题。 + +## 没有实习经历怎么办? 如果实在是找不到合适的实习的话,那也没办法,我们应该多花时间去把下面这三件事情给做好: @@ -14,7 +23,7 @@ icon: experience 2. 持续完善简历 3. 准备技术面试 -## 补强项目经历 +### 补强项目经历 校招没有实习经历的话,找工作比较吃亏(没办法,太卷了),需要在项目经历部分多发力弥补一下。 @@ -24,7 +33,7 @@ icon: experience 推荐阅读一下网站的这篇文章:[项目经验指南](https://javaguide.cn/interview-preparation/project-experience-guide.html)。 -## **完善简历** +### 完善简历 一定一定一定要重视简历啊!建议至少花 2~3 天时间来专门完善自己的简历。并且,后续还要持续完善。 @@ -40,17 +49,46 @@ icon: experience 详细的程序员简历编写指南可以参考这篇文章:[程序员简历编写指南(重要)](https://javaguide.cn/interview-preparation/resume-guide.html)。 -## **准备技术面试** +### 准备技术面试 面试之前一定要提前准备一下常见的面试题也就是八股文: - 自己面试中可能涉及哪些知识点、那些知识点是重点。 - 面试中哪些问题会被经常问到、面试中自己该如何回答。(强烈不推荐死记硬背,第一:通过背这种方式你能记住多少?能记住多久?第二:背题的方式的学习很难坚持下去!) -Java 后端面试复习的重点请看这篇文章:[Java 后端的面试重点是什么?](https://javaguide.cn/interview-preparation/key-points-of-interview.html)。 - 不同类型的公司对于技能的要求侧重点是不同的比如腾讯、字节可能更重视计算机基础比如网络、操作系统这方面的内容。阿里、美团这种可能更重视你的项目经历、实战能力。 一定不要抱着一种思想,觉得八股文或者基础问题的考查意义不大。如果你抱着这种思想复习的话,那效果可能不会太好。实际上,个人认为还是很有意义的,八股文或者基础性的知识在日常开发中也会需要经常用到。例如,线程池这块的拒绝策略、核心参数配置什么的,如果你不了解,实际项目中使用线程池可能就用的不是很明白,容易出现问题。而且,其实这种基础性的问题是最容易准备的,像各种底层原理、系统设计、场景题以及深挖你的项目这类才是最难的! 八股文资料首推我的 [《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 和 [JavaGuide](https://javaguide.cn/home.html) 。里面不仅仅是原创八股文,还有很多对实际开发有帮助的干货。除了我的资料之外,你还可以去网上找一些其他的优质的文章、视频来看。 + +如果你想要系统准备 Java 后端面试但又不知道如何开始的,可以参考 [Java 后端面试通关计划(后端通用)](https://javaguide.cn/interview-preparation/backend-interview-plan.html)。 + +## 实习经历在简历上一般怎么写比较出彩? + +实习经历的描述一定要避免空谈,尽量列举出你在实习期间取得的成就和具体贡献,使用具体的数据和指标来量化你的工作成果。 + +示例(这里假设项目细节放在实习经历这里介绍,你也可以选择将实习经历参与的项目放到项目经历中): + +1. 负责订单模块核心流程开发,实现订单状态的精确流转,并保障与库存、支付等模块的数据一致性。 +2. 负责行为风控黑名单看板的开发,支持查看拉黑用户、批量拉黑以及取消拉黑。 +3. 基于 Redisson + AOP 封装限流组件,实现对核心接口(如付费、课程搜索)的限流,有效防止恶意请求冲击。 +4. 优化用户统计模块性能,利用 CompletableFuture 并行加载多维度数据(如用户增长、课程活跃度),,平均相应时间从 3.5s 降低到 1s。 +5. 封装通用数据脱敏组件,通过自定义 Jackson 注解实现对手机号、邮箱等敏感信息的自动、无侵入式脱敏。 +6. 优化文件上传模块,基于 MinIO 实现了文件的分片上传、断点续传以及极速秒传功能。 +7. 排查并解决扣费模块由于扣费父任务和反作弊子任务使用同一个线程池导致的死锁问题,通过线程池隔离策略根除该隐患。 +8. 实习期间独立负责 7 个功能需求与 3 个线上问题修复,代码均一次性通过评审与测试。 + +下面是[星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)一位球友分享的实习经历介绍,整体写的还是非常不错的: + + + +📌关于实习经历这块再多提一点:很多同学实习期间可能接触不到什么实际的开发任务,大部分时间可能都是在熟悉和维护项目。 + +对于这种情况,应对思路是一套组合拳:首先,你肯定是要和 mentor 沟通继续争取做一些有价值的工作,这样你的实习经历才更有价值,简历上自然就能够有东西可写。记得找一个 mentor 不那么忙的时候沟通,放低姿态,真诚一些,表明自己现有的工作已经认真完成,想要承担更多责任的意愿。其次,不管是否能够争取到这种机会,你都要自己有意识地寻找项目中适合自己研究的功能点(比如同组其他实习生干的活),进行深度挖掘。重点关注以下几个方面: + +1. **这个功能是干嘛的?** 它解决了什么业务痛点?给哪个业务方用的?整个流程是怎样的? +2. **它是怎么实现的?** 用了哪些关键技术、框架或者设计模式?核心代码的逻辑是怎样的? +3. **为什么要这么设计?** 当初设计的时候有没有别的方案?现在这个方案好在哪,又有什么潜在的坑?如果让你来做,你会怎么设计? + +只要你把具体的功能点彻底搞懂,那就可以在简历上合理包装成自己的成果。除了功能点开发之外,也可以包装一些合适的问题排查解决经历,这样能够体现你解决问题的能力。 面试时也不用太担心自己“露馅”,只要你选择的内容不属于那些显然不会交给实习生完成的高难度任务,并且能清晰地讲明白,就不会有问题。 diff --git a/docs/interview-preparation/interview-experience.md b/docs/interview-preparation/interview-experience.md index 2b58e95df10..c5f08d174ae 100644 --- a/docs/interview-preparation/interview-experience.md +++ b/docs/interview-preparation/interview-experience.md @@ -1,12 +1,17 @@ --- title: 优质面经汇总(付费) +description: 优质面经汇总:整理 30+ 篇高质量 Java 后端校招/社招面经与复盘,总结高频考点与面试策略,适合对照自测与查缺补漏。 category: 知识星球 icon: experience +head: + - - meta + - name: keywords + content: Java面经,校招面经,社招面经,大厂面经,面试经验,面经汇总,Java后端面试,付费专栏 --- 古人云:“**他山之石,可以攻玉**” 。善于学习借鉴别人的面试的成功经验或者失败的教训,可以让自己少走许多弯路。 -在 **[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)** 的 **「面经篇」** ,我分享了 15+ 篇高质量的 Java 后端面经,有校招的,也有社招的,有大厂的,也有中小厂的。 +在 **[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)** 的 **「面经篇」** ,我分享了 30+ 篇高质量的 Java 后端面经,有校招的,也有社招的,有大厂的,也有中小厂的。 如果你是非科班的同学,也能在这些文章中找到对应的非科班的同学写的面经。 diff --git a/docs/interview-preparation/java-roadmap.md b/docs/interview-preparation/java-roadmap.md index 44de032e88c..4e234274c45 100644 --- a/docs/interview-preparation/java-roadmap.md +++ b/docs/interview-preparation/java-roadmap.md @@ -1,9 +1,16 @@ --- title: Java 学习路线(最新版,4w+字) +description: Java学习路线最新版:结合当下 Java 后端招聘要求,提供从基础到进阶的系统学习路径与资料建议,覆盖Java核心、数据库、缓存、中间件、框架与面试重点,帮助高效规划与提速上岸。 category: 面试准备 icon: path +head: + - - meta + - name: keywords + content: Java学习路线,Java后端路线,Java学习计划,校招准备,面试路线,Spring Boot,MySQL,Redis,JVM --- + + ::: tip 重要说明 本学习路线保持**年度系统性修订**,严格同步 Java 技术生态与招聘市场的最新动态,**确保内容时效性与前瞻性**。 diff --git a/docs/interview-preparation/key-points-of-interview.md b/docs/interview-preparation/key-points-of-interview.md index c2101dc307a..db3ffd91c89 100644 --- a/docs/interview-preparation/key-points-of-interview.md +++ b/docs/interview-preparation/key-points-of-interview.md @@ -1,9 +1,16 @@ --- title: Java后端面试重点总结 +description: Java后端面试重点总结:梳理校招/社招高频考点与复习优先级,覆盖Java基础、集合、并发、MySQL、Redis、Spring/Spring Boot、JVM与项目经验准备,帮你抓重点高效备战。 category: 面试准备 icon: star +head: + - - meta + - name: keywords + content: Java后端面试,面试重点,八股文,Java基础,Java集合,Java并发,MySQL,Redis,Spring Boot,项目经验 --- + + ::: tip 友情提示 本文节选自 **[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)**。这是一份教你如何更高效地准备面试的专栏,内容和 JavaGuide 互补,涵盖常见八股文(系统设计、常见框架、分布式、高并发 ……)、优质面经等内容。 ::: @@ -12,6 +19,10 @@ icon: star **准备面试的时候,具体哪些知识点是重点呢?如何把握重点?** +先看下面这张全局图(后续会详细解读): + +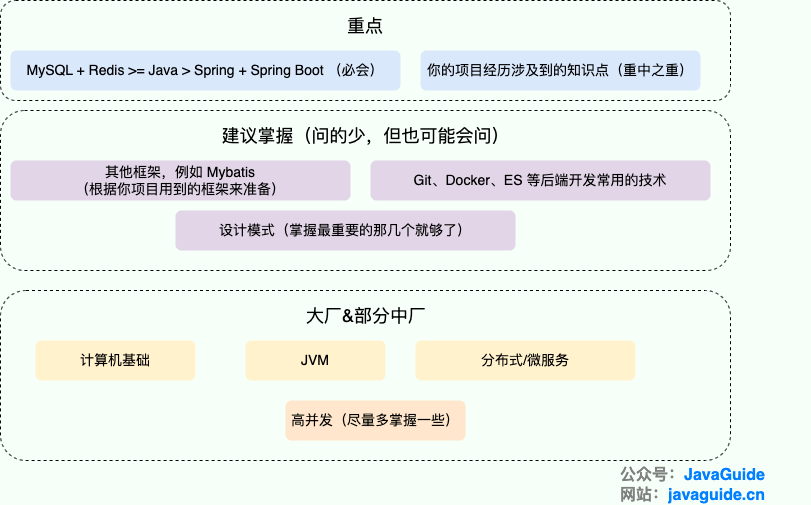 + 给你几点靠谱的建议: 1. Java 基础、集合、并发、MySQL、Redis 、Spring、Spring Boot 这些 Java 后端开发必备的知识点(MySQL + Redis >= Java > Spring + Spring Boot)。大厂以及中小厂的面试问的比较多的就是这些知识点。Spring 和 Spring Boot 这俩框架类的知识点相对前面的知识点来说重要性要稍低一些,但一般面试也会问一些,尤其是中小厂。并发知识一般中大厂提问更多也更难,尤其是大厂喜欢深挖底层,很容易把人问倒。计算机基础相关的内容会在下面提到。 @@ -19,13 +30,15 @@ icon: star 3. 针对自身找工作的需求,你又可以适当地调整复习的重点。像中小厂一般问计算机基础比较少一些,有些大厂比如字节比较重视计算机基础尤其是算法。这样的话,如果你的目标是中小厂的话,计算机基础就准备面试来说不是那么重要了。如果复习时间不够的话,可以暂时先放放,腾出时间给其他重要的知识点。 4. 一般校招的面试不会强制要求你会分布式/微服务、高并发的知识(不排除个别岗位有这方面的硬性要求),所以到底要不要掌握还是要看你个人当前的实际情况。如果你会这方面的知识的话,对面试相对来说还是会更有利一些(想要让项目经历有亮点,还是得会一些性能优化的知识。性能优化的知识这也算是高并发知识的一个小分支了)。如果你的技能介绍或者项目经历涉及到分布式/微服务、高并发的知识,那建议你尽量也要抽时间去认真准备一下,面试中很可能会被问到,尤其是项目经历用到的时候。不过,也还是主要准备写在简历上的那些知识点就好。 5. JVM 相关的知识点,一般是大厂(例如美团、阿里)和一些不错的中厂(例如携程、顺丰、招银网络)才会问到,面试国企、差一点的中厂和小厂就没必要准备了。JVM 面试中比较常问的是 [Java 内存区域](https://javaguide.cn/java/jvm/memory-area.html)、[JVM 垃圾回收](https://javaguide.cn/java/jvm/jvm-garbage-collection.html)、[类加载器和双亲委派模型](https://javaguide.cn/java/jvm/classloader.html) 以及 JVM 调优和问题排查(我之前分享过一些[常见的线上问题案例](https://t.zsxq.com/0bsAac47U),里面就有 JVM 相关的)。 -6. 不同的大厂面试侧重点也会不同。比如说你要去阿里这种公司的话,项目和八股文就是重点,阿里笔试一般会有代码题,进入面试后就很少问代码题了,但是对原理性的问题问的比较深,经常会问一些你对技术的思考。再比如说你要面试字节这种公司,那计算机基础,尤其是算法是重点,字节的面试十分注重代码功底,有时候开始面试就会直接甩给你一道代码题,写出来再谈别的。也会问面试八股文,以及项目,不过,相对来说要少很多。建议你看一下这篇文章 [为了解开互联网大厂秋招内幕,我把他们全面了一遍](https://mp.weixin.qq.com/s/pBsGQNxvRupZeWt4qZReIA),了解一下常见大厂的面试题侧重点。 +6. 不同的大厂面试侧重点也会不同。比如说你要去阿里这种公司的话,项目和八股文就是重点,阿里笔试一般会有代码题,进入面试后就很少问代码题了,但是对原理性的问题问的比较深,经常会问一些你对技术的思考。再比如说你要面试字节这种公司,那计算机基础,尤其是算法是重点,字节的面试十分注重代码功底,有时候开始面试就会直接甩给你一道代码题,写出来再谈别的。也会问面试八股文,以及项目,不过,相对来说要少很多。 7. 多去找一些面经看看,尤其你目标公司或者类似公司对应岗位的面经。这样可以实现针对性的复习,还能顺便自测一波,检查一下自己的掌握情况。 看似 Java 后端八股文很多,实际把复习范围一缩小,重要的东西就是那些。考虑到时间问题,你不可能连一些比较冷门的知识点也给准备了。这没必要,主要精力先放在那些重要的知识点即可。 ## 如何更高效地准备八股文? +
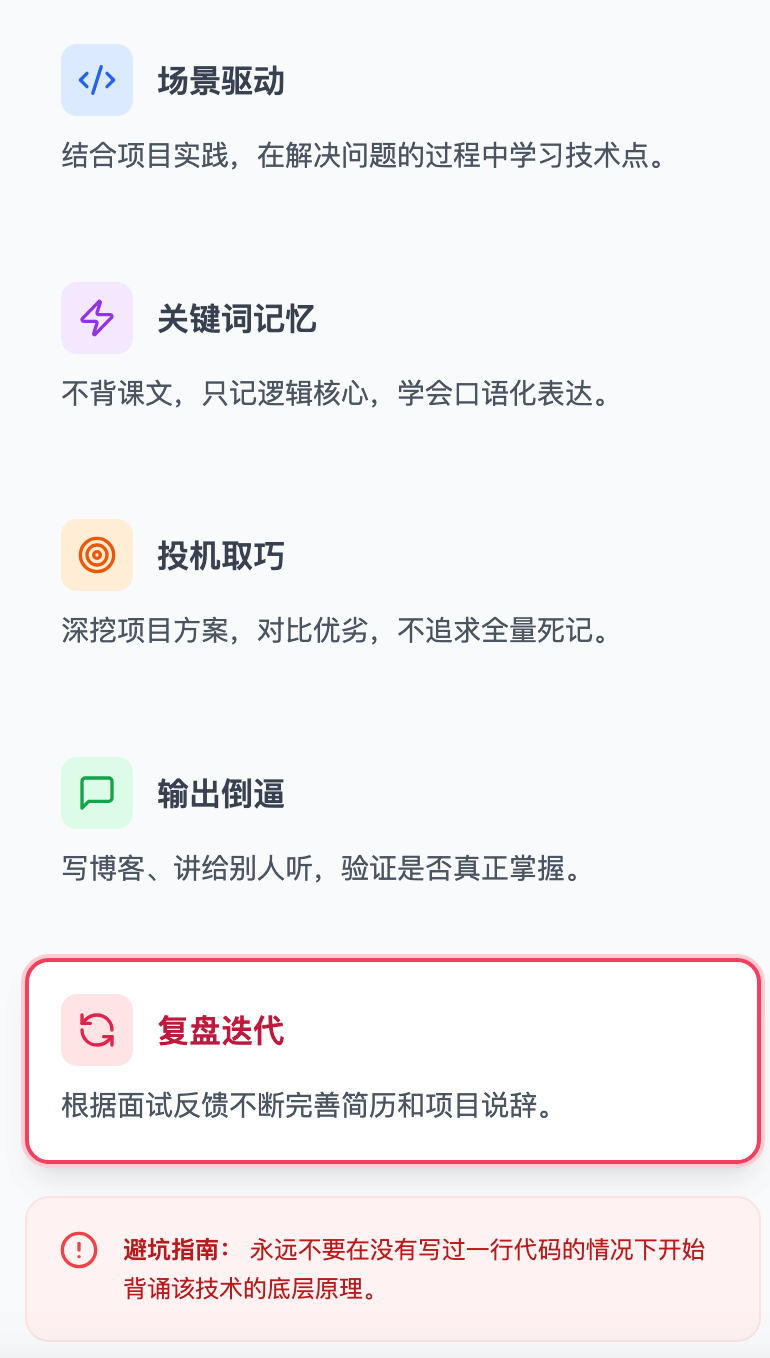 +
对于技术八股文来说,尽量不要死记硬背,这种方式非常枯燥且对自身能力提升有限!但是!想要一点不背是不太现实的,只是说要结合实际应用场景和实战来理解记忆。
我一直觉得面试八股文最好是和实际应用场景和实战相结合。很多同学现在的方向都错了,上来就是直接背八股文,硬生生学成了文科,那当然无趣了。
@@ -41,3 +54,7 @@ icon: star
另外,准备八股文的过程中,强烈建议你花个几个小时去根据你的简历(主要是项目经历部分)思考一下哪些地方可能被深挖,然后把你自己的思考以面试问题的形式体现出来。面试之后,你还要根据当下的面试情况复盘一波,对之前自己整理的面试问题进行完善补充。这个过程对于个人进一步熟悉自己的简历(尤其是项目经历)部分,非常非常有用。这些问题你也一定要多花一些时间搞懂吃透,能够流畅地表达出来。面试问题可以参考 [Java 面试常见问题总结(2024 最新版)](https://t.zsxq.com/0eRq7EJPy),记得根据自己项目经历去深入拓展即可!
最后,准备技术面试的同学一定要定期复习(自测的方式非常好),不然确实会遗忘的。
+
+## 详细面试准备计划(后端通用)
+
+[Java 后端面试重点和详细准备计划](https://javaguide.cn/interview-preparation/backend-interview-plan.html)
diff --git a/docs/interview-preparation/pdf-interview-javaguide.md b/docs/interview-preparation/pdf-interview-javaguide.md
new file mode 100644
index 00000000000..67d0da97125
--- /dev/null
+++ b/docs/interview-preparation/pdf-interview-javaguide.md
@@ -0,0 +1,62 @@
+---
+title: 2026 最新后端面试 PDF 资料
+description: 2026 版后端面试 PDF 资料整理(JavaGuide):梳理校招/社招高频考点与复习优先级,覆盖 Java 基础、集合、并发、MySQL、Redis、Spring/Spring Boot、JVM、系统设计与项目经验准备,帮你抓重点高效备战。
+category: 面试准备
+icon: pdf
+head:
+ - - meta
+ - name: keywords
+ content: 后端面试PDF,Java面试PDF,PDF面试资料,Java八股文PDF,面试突击PDF,校招社招,Java后端面试,Java基础,Java集合,Java并发,JVM,MySQL,Redis,Spring Boot,系统设计,项目经验
+---
+
+大家好,我是 Guide。
+
+**2026 版后端 PDF 面试资料终于搞定了!这次的更新量大得惊人,熬了几个通宵,总算能拿出来见人了。**
+
+在上一版的基础上,我把内容又往深里挖了挖。目前这份资料已经涵盖了 **Java 核心、计算机基础、数据库、缓存、分布式、设计模式、智力题、学习路线、面经**等全方位内容。毫不夸张地说,你备战后端面试需要的硬核干货,这一份全包了!
+
+为了让大家看得更爽,我对其中大部分 PDF 进行了“推倒重来式”的优化:
+
+- **重构面试突击系列**:将原先臃肿的内容拆分成多篇,逻辑更清晰。
+- **重写设计模式总结**:新增多道高频设计模式面试题,优化内容表达。
+- **全方位细节完善**:每一个知识点都反复推敲,确保没有逻辑断层。
+
+
+
+这些 PDF 面试资料的质量都非常高,绝大部分都是 Guide 的原创,也会有一些其他优质技术博主分享的原创资料。
+
+之所以一直坚持出 PDF 版,是因为有一些朋友比较喜欢看 PDF 资料,甚至把 PDF 资料打印出来学习。
+
+
+
+截止到目前,这套资料在各个渠道的汇总下载量已经突破了 **35w+** 。 说实话,这个数字对我来说不只是流量,更是沉甸甸的信任和责任。
+
+老规矩,没有任何花里胡哨的套路,直接**白嫖**: 在 **JavaGuide** 公众号后台回复 **PDF** 即可获取。
+
+
+
+由于 PDF 的时效性问题,如果想要更完美的体验,个人其实还是更建议大家去 [JavaGuide](https://javaguide.cn/) 网站上在线阅读,内容更新,一直在持续完善。
+
+## 部分内容概览
+
+**《JavaGuide 面试突击》— Java 集合**:
+
+
+
+**《JavaGuide 面试突击》— JVM**:
+
+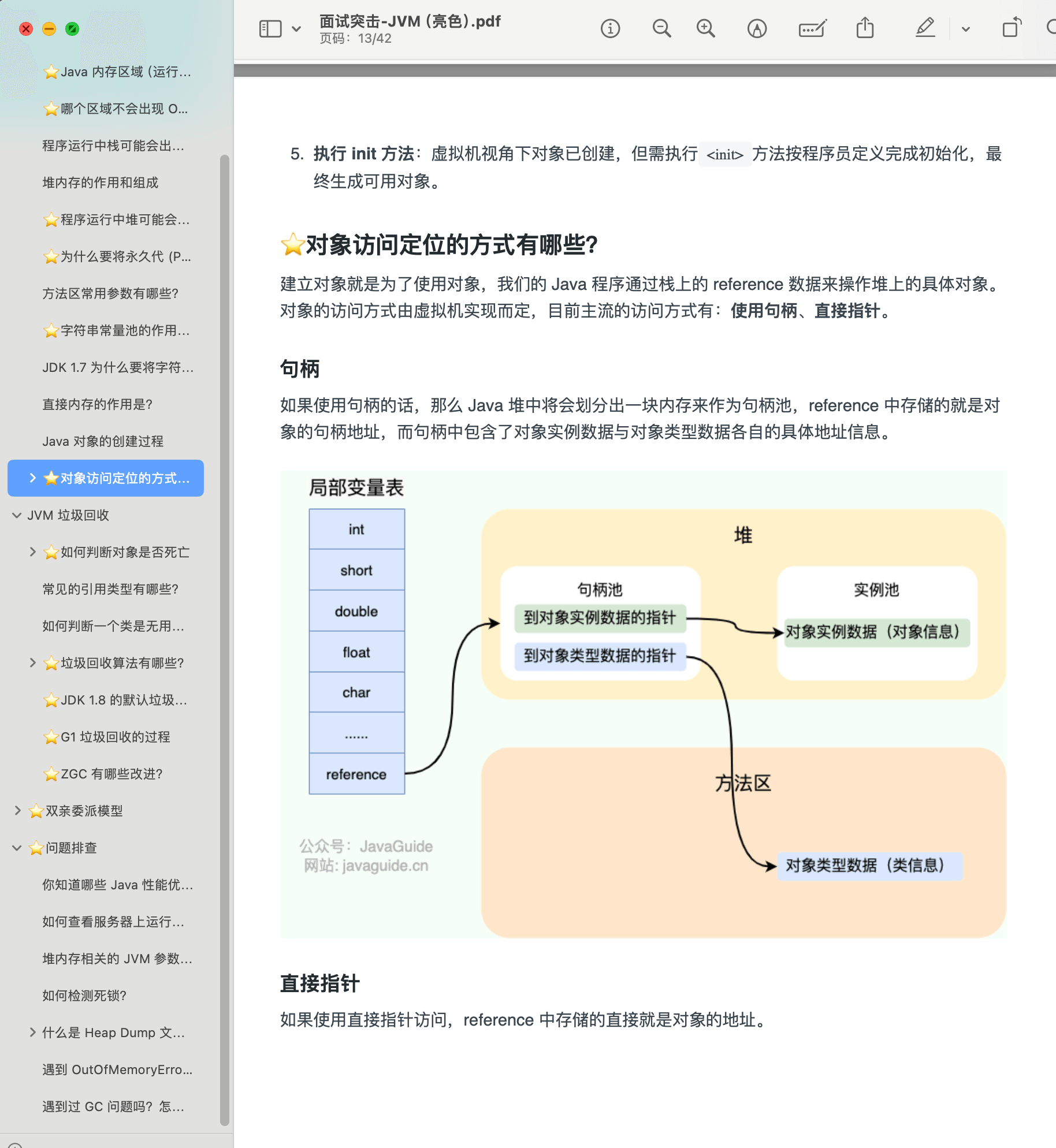
+
+**《JavaGuide 面试突击》—设计模式**:
+
+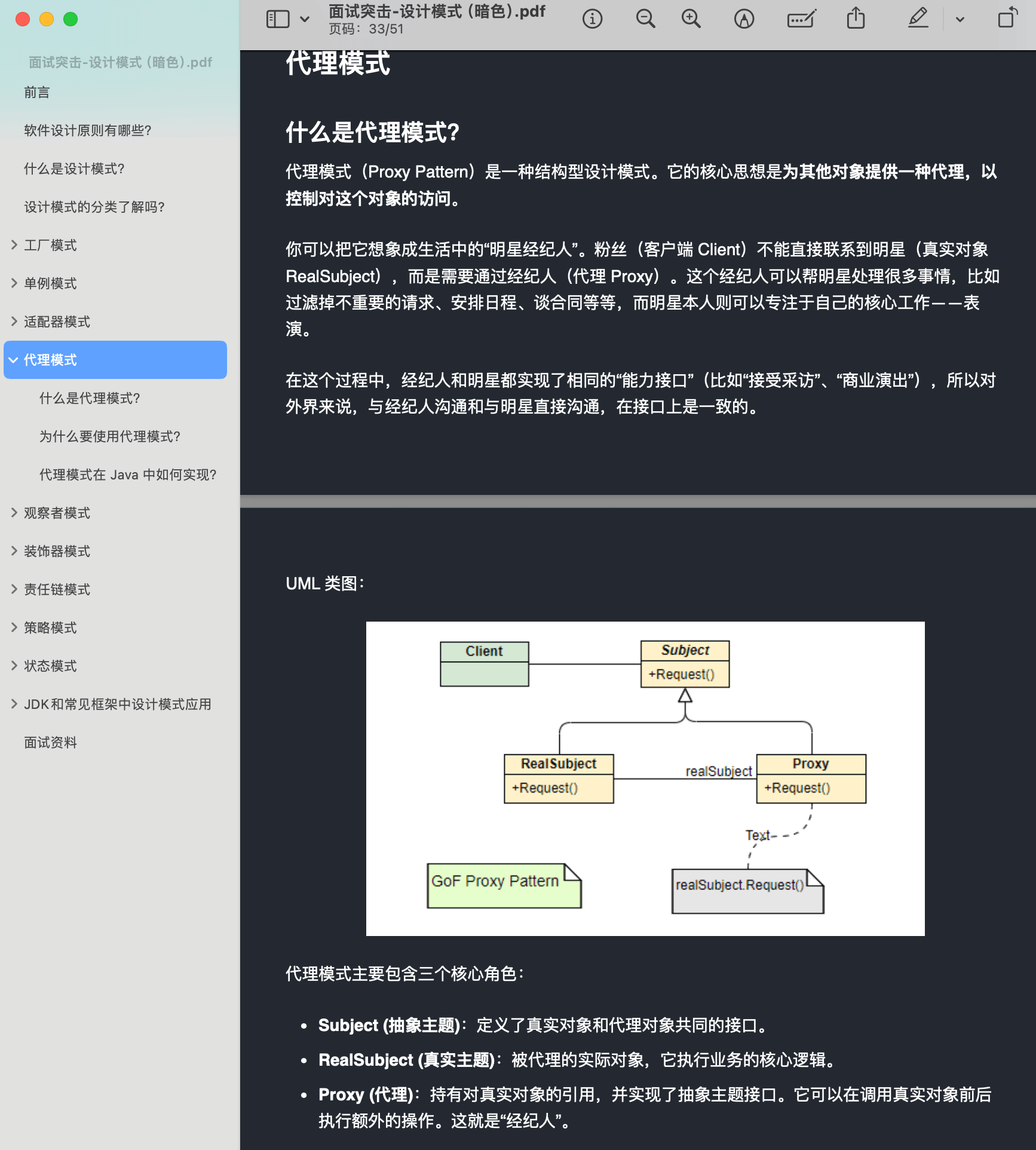
+
+**Java 学习路线**:
+
+
+
+## 如何获取?
+
+老规矩,没有任何花里胡哨的套路,直接**白嫖**: 在 **JavaGuide** 公众号后台回复 **PDF** 即可获取。
+
+
diff --git a/docs/interview-preparation/project-experience-guide.md b/docs/interview-preparation/project-experience-guide.md
index 1b0992fab84..2b9a3c1026a 100644
--- a/docs/interview-preparation/project-experience-guide.md
+++ b/docs/interview-preparation/project-experience-guide.md
@@ -1,7 +1,12 @@
---
title: 项目经验指南
+description: 项目经验指南:针对没有项目/项目平淡的求职者,给出获取实战项目经验的方法与选择建议,并讲清如何做出项目亮点、如何复盘与表达,提升简历与面试竞争力。
category: 面试准备
icon: project
+head:
+ - - meta
+ - name: keywords
+ content: 项目经验,校招项目,实战项目,项目亮点,简历项目描述,后端项目,面试项目准备,项目复盘
---
::: tip 友情提示
diff --git a/docs/interview-preparation/resume-guide.md b/docs/interview-preparation/resume-guide.md
index 396ef4b47e4..f0cd20b003b 100644
--- a/docs/interview-preparation/resume-guide.md
+++ b/docs/interview-preparation/resume-guide.md
@@ -1,7 +1,12 @@
---
title: 程序员简历编写指南
+description: 程序员简历编写指南:从筛选逻辑出发讲清简历结构、项目经历与技能描述写法,提供简历模板与避坑建议,帮助你提高简历通过率并让面试官更好地深挖你的亮点。
category: 面试准备
icon: jianli
+head:
+ - - meta
+ - name: keywords
+ content: 程序员简历,Java简历,简历优化,项目经历写法,简历模板,校招简历,社招简历,面试准备
---
::: tip 友情提示
diff --git a/docs/interview-preparation/self-test-of-common-interview-questions.md b/docs/interview-preparation/self-test-of-common-interview-questions.md
index 9700ac5b941..c3d8c038eb2 100644
--- a/docs/interview-preparation/self-test-of-common-interview-questions.md
+++ b/docs/interview-preparation/self-test-of-common-interview-questions.md
@@ -1,7 +1,12 @@
---
title: 常见面试题自测(付费)
+description: 常见面试题自测:按面试提问方式整理Java后端高频问题,提供提示与重要程度标注,适合面试前自测、定位短板、针对性复习。
category: 知识星球
icon: security-fill
+head:
+ - - meta
+ - name: keywords
+ content: 面试题自测,Java面试题,八股文自测,查缺补漏,面试复习,高频考点,Java后端面试,付费内容
---
面试之前,强烈建议大家多拿常见的面试题来进行自测,检查一下自己的掌握情况,这是一种非常实用的备战技术面试的小技巧。
diff --git a/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md b/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
index a42f9fa2353..beba0d99cbd 100644
--- a/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
+++ b/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
@@ -1,7 +1,12 @@
---
title: 如何高效准备Java面试?
+description: 如何高效准备Java面试:从求职导向学习、技能清单制定到简历优化与面试冲刺,提供系统化备战方法,帮助你少走弯路、提高面试通过率。
category: 知识星球
icon: path
+head:
+ - - meta
+ - name: keywords
+ content: Java面试准备,高效备战面试,求职导向学习,面试冲刺,简历优化,项目准备,校招,Java后端
---
::: tip 友情提示
diff --git a/docs/java/basis/bigdecimal.md b/docs/java/basis/bigdecimal.md
index f4cda70a94f..7978438f298 100644
--- a/docs/java/basis/bigdecimal.md
+++ b/docs/java/basis/bigdecimal.md
@@ -1,15 +1,13 @@
---
title: BigDecimal 详解
+description: 详解BigDecimal使用方法:解决浮点数精度丢失问题,掌握加减乘除运算、RoundingMode舍入规则、compareTo比较方法,适用金融计算等高精度场景。
category: Java
tag:
- Java基础
head:
- - meta
- name: keywords
- content: BigDecimal,浮点数精度,小数运算,compareTo,舍入规则,RoundingMode,divide,阿里巴巴规范
- - - meta
- - name: description
- content: 讲解 BigDecimal 的使用场景与核心 API,解决浮点数精度问题并总结常见舍入规则与最佳实践。
+ content: BigDecimal,浮点数精度,小数运算,RoundingMode舍入模式,BigDecimal比较,金额计算,精度丢失
---
《阿里巴巴 Java 开发手册》中提到:“为了避免精度丢失,可以使用 `BigDecimal` 来进行浮点数的运算”。
@@ -28,7 +26,7 @@ System.out.println(a == b);// false
**为什么浮点数 `float` 或 `double` 运算的时候会有精度丢失的风险呢?**
-这个和计算机保存小数的机制有很大关系。我们知道计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。这也就是解释了为什么十进制小数没有办法用二进制精确表示。
+这个和计算机保存小数的机制有很大关系。我们知道计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。这也就解释了为什么十进制小数没有办法用二进制精确表示。
就比如说十进制下的 0.2 就没办法精确转换成二进制小数:
diff --git a/docs/java/basis/generics-and-wildcards.md b/docs/java/basis/generics-and-wildcards.md
index 6904c622f16..1740999940c 100644
--- a/docs/java/basis/generics-and-wildcards.md
+++ b/docs/java/basis/generics-and-wildcards.md
@@ -1,17 +1,362 @@
---
title: 泛型&通配符详解
+description: 全面解析Java泛型与通配符:深入理解类型擦除机制、上界下界通配符用法、PECS原则应用,掌握泛型编程核心技巧。
category: Java
tag:
- Java基础
head:
- - meta
- name: keywords
- content: 泛型,通配符,类型擦除,上界通配符,下界通配符,PECS,泛型方法
- - - meta
- - name: description
- content: 解析 Java 泛型与通配符的语法与原理,涵盖类型擦除、边界与 PECS 原则等高频知识点。
+ content: Java泛型,通配符,类型擦除,泛型边界,PECS原则,泛型方法,上界下界通配符,泛型接口
---
-**泛型&通配符** 相关的面试题为我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)(点击链接即可查看详细介绍以及获取方法)中。
+## 泛型
+
+### 什么是泛型?有什么作用?
+
+**Java 泛型(Generics)** 是 JDK 5 中引入的一个新特性。使用泛型参数,可以增强代码的可读性以及稳定性。**如无特别说明,以下行为以 Java 8 为准。**
+
+编译器可以对泛型参数进行检测,并且通过泛型参数可以指定传入的对象类型。比如 `ArrayList
+
对于技术八股文来说,尽量不要死记硬背,这种方式非常枯燥且对自身能力提升有限!但是!想要一点不背是不太现实的,只是说要结合实际应用场景和实战来理解记忆。
我一直觉得面试八股文最好是和实际应用场景和实战相结合。很多同学现在的方向都错了,上来就是直接背八股文,硬生生学成了文科,那当然无趣了。
@@ -41,3 +54,7 @@ icon: star
另外,准备八股文的过程中,强烈建议你花个几个小时去根据你的简历(主要是项目经历部分)思考一下哪些地方可能被深挖,然后把你自己的思考以面试问题的形式体现出来。面试之后,你还要根据当下的面试情况复盘一波,对之前自己整理的面试问题进行完善补充。这个过程对于个人进一步熟悉自己的简历(尤其是项目经历)部分,非常非常有用。这些问题你也一定要多花一些时间搞懂吃透,能够流畅地表达出来。面试问题可以参考 [Java 面试常见问题总结(2024 最新版)](https://t.zsxq.com/0eRq7EJPy),记得根据自己项目经历去深入拓展即可!
最后,准备技术面试的同学一定要定期复习(自测的方式非常好),不然确实会遗忘的。
+
+## 详细面试准备计划(后端通用)
+
+[Java 后端面试重点和详细准备计划](https://javaguide.cn/interview-preparation/backend-interview-plan.html)
diff --git a/docs/interview-preparation/pdf-interview-javaguide.md b/docs/interview-preparation/pdf-interview-javaguide.md
new file mode 100644
index 00000000000..67d0da97125
--- /dev/null
+++ b/docs/interview-preparation/pdf-interview-javaguide.md
@@ -0,0 +1,62 @@
+---
+title: 2026 最新后端面试 PDF 资料
+description: 2026 版后端面试 PDF 资料整理(JavaGuide):梳理校招/社招高频考点与复习优先级,覆盖 Java 基础、集合、并发、MySQL、Redis、Spring/Spring Boot、JVM、系统设计与项目经验准备,帮你抓重点高效备战。
+category: 面试准备
+icon: pdf
+head:
+ - - meta
+ - name: keywords
+ content: 后端面试PDF,Java面试PDF,PDF面试资料,Java八股文PDF,面试突击PDF,校招社招,Java后端面试,Java基础,Java集合,Java并发,JVM,MySQL,Redis,Spring Boot,系统设计,项目经验
+---
+
+大家好,我是 Guide。
+
+**2026 版后端 PDF 面试资料终于搞定了!这次的更新量大得惊人,熬了几个通宵,总算能拿出来见人了。**
+
+在上一版的基础上,我把内容又往深里挖了挖。目前这份资料已经涵盖了 **Java 核心、计算机基础、数据库、缓存、分布式、设计模式、智力题、学习路线、面经**等全方位内容。毫不夸张地说,你备战后端面试需要的硬核干货,这一份全包了!
+
+为了让大家看得更爽,我对其中大部分 PDF 进行了“推倒重来式”的优化:
+
+- **重构面试突击系列**:将原先臃肿的内容拆分成多篇,逻辑更清晰。
+- **重写设计模式总结**:新增多道高频设计模式面试题,优化内容表达。
+- **全方位细节完善**:每一个知识点都反复推敲,确保没有逻辑断层。
+
+
+
+这些 PDF 面试资料的质量都非常高,绝大部分都是 Guide 的原创,也会有一些其他优质技术博主分享的原创资料。
+
+之所以一直坚持出 PDF 版,是因为有一些朋友比较喜欢看 PDF 资料,甚至把 PDF 资料打印出来学习。
+
+
+
+截止到目前,这套资料在各个渠道的汇总下载量已经突破了 **35w+** 。 说实话,这个数字对我来说不只是流量,更是沉甸甸的信任和责任。
+
+老规矩,没有任何花里胡哨的套路,直接**白嫖**: 在 **JavaGuide** 公众号后台回复 **PDF** 即可获取。
+
+
+
+由于 PDF 的时效性问题,如果想要更完美的体验,个人其实还是更建议大家去 [JavaGuide](https://javaguide.cn/) 网站上在线阅读,内容更新,一直在持续完善。
+
+## 部分内容概览
+
+**《JavaGuide 面试突击》— Java 集合**:
+
+
+
+**《JavaGuide 面试突击》— JVM**:
+
+
+
+**《JavaGuide 面试突击》—设计模式**:
+
+
+
+**Java 学习路线**:
+
+
+
+## 如何获取?
+
+老规矩,没有任何花里胡哨的套路,直接**白嫖**: 在 **JavaGuide** 公众号后台回复 **PDF** 即可获取。
+
+
diff --git a/docs/interview-preparation/project-experience-guide.md b/docs/interview-preparation/project-experience-guide.md
index 1b0992fab84..2b9a3c1026a 100644
--- a/docs/interview-preparation/project-experience-guide.md
+++ b/docs/interview-preparation/project-experience-guide.md
@@ -1,7 +1,12 @@
---
title: 项目经验指南
+description: 项目经验指南:针对没有项目/项目平淡的求职者,给出获取实战项目经验的方法与选择建议,并讲清如何做出项目亮点、如何复盘与表达,提升简历与面试竞争力。
category: 面试准备
icon: project
+head:
+ - - meta
+ - name: keywords
+ content: 项目经验,校招项目,实战项目,项目亮点,简历项目描述,后端项目,面试项目准备,项目复盘
---
::: tip 友情提示
diff --git a/docs/interview-preparation/resume-guide.md b/docs/interview-preparation/resume-guide.md
index 396ef4b47e4..f0cd20b003b 100644
--- a/docs/interview-preparation/resume-guide.md
+++ b/docs/interview-preparation/resume-guide.md
@@ -1,7 +1,12 @@
---
title: 程序员简历编写指南
+description: 程序员简历编写指南:从筛选逻辑出发讲清简历结构、项目经历与技能描述写法,提供简历模板与避坑建议,帮助你提高简历通过率并让面试官更好地深挖你的亮点。
category: 面试准备
icon: jianli
+head:
+ - - meta
+ - name: keywords
+ content: 程序员简历,Java简历,简历优化,项目经历写法,简历模板,校招简历,社招简历,面试准备
---
::: tip 友情提示
diff --git a/docs/interview-preparation/self-test-of-common-interview-questions.md b/docs/interview-preparation/self-test-of-common-interview-questions.md
index 9700ac5b941..c3d8c038eb2 100644
--- a/docs/interview-preparation/self-test-of-common-interview-questions.md
+++ b/docs/interview-preparation/self-test-of-common-interview-questions.md
@@ -1,7 +1,12 @@
---
title: 常见面试题自测(付费)
+description: 常见面试题自测:按面试提问方式整理Java后端高频问题,提供提示与重要程度标注,适合面试前自测、定位短板、针对性复习。
category: 知识星球
icon: security-fill
+head:
+ - - meta
+ - name: keywords
+ content: 面试题自测,Java面试题,八股文自测,查缺补漏,面试复习,高频考点,Java后端面试,付费内容
---
面试之前,强烈建议大家多拿常见的面试题来进行自测,检查一下自己的掌握情况,这是一种非常实用的备战技术面试的小技巧。
diff --git a/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md b/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
index a42f9fa2353..beba0d99cbd 100644
--- a/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
+++ b/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
@@ -1,7 +1,12 @@
---
title: 如何高效准备Java面试?
+description: 如何高效准备Java面试:从求职导向学习、技能清单制定到简历优化与面试冲刺,提供系统化备战方法,帮助你少走弯路、提高面试通过率。
category: 知识星球
icon: path
+head:
+ - - meta
+ - name: keywords
+ content: Java面试准备,高效备战面试,求职导向学习,面试冲刺,简历优化,项目准备,校招,Java后端
---
::: tip 友情提示
diff --git a/docs/java/basis/bigdecimal.md b/docs/java/basis/bigdecimal.md
index f4cda70a94f..7978438f298 100644
--- a/docs/java/basis/bigdecimal.md
+++ b/docs/java/basis/bigdecimal.md
@@ -1,15 +1,13 @@
---
title: BigDecimal 详解
+description: 详解BigDecimal使用方法:解决浮点数精度丢失问题,掌握加减乘除运算、RoundingMode舍入规则、compareTo比较方法,适用金融计算等高精度场景。
category: Java
tag:
- Java基础
head:
- - meta
- name: keywords
- content: BigDecimal,浮点数精度,小数运算,compareTo,舍入规则,RoundingMode,divide,阿里巴巴规范
- - - meta
- - name: description
- content: 讲解 BigDecimal 的使用场景与核心 API,解决浮点数精度问题并总结常见舍入规则与最佳实践。
+ content: BigDecimal,浮点数精度,小数运算,RoundingMode舍入模式,BigDecimal比较,金额计算,精度丢失
---
《阿里巴巴 Java 开发手册》中提到:“为了避免精度丢失,可以使用 `BigDecimal` 来进行浮点数的运算”。
@@ -28,7 +26,7 @@ System.out.println(a == b);// false
**为什么浮点数 `float` 或 `double` 运算的时候会有精度丢失的风险呢?**
-这个和计算机保存小数的机制有很大关系。我们知道计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。这也就是解释了为什么十进制小数没有办法用二进制精确表示。
+这个和计算机保存小数的机制有很大关系。我们知道计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。这也就解释了为什么十进制小数没有办法用二进制精确表示。
就比如说十进制下的 0.2 就没办法精确转换成二进制小数:
diff --git a/docs/java/basis/generics-and-wildcards.md b/docs/java/basis/generics-and-wildcards.md
index 6904c622f16..1740999940c 100644
--- a/docs/java/basis/generics-and-wildcards.md
+++ b/docs/java/basis/generics-and-wildcards.md
@@ -1,17 +1,362 @@
---
title: 泛型&通配符详解
+description: 全面解析Java泛型与通配符:深入理解类型擦除机制、上界下界通配符用法、PECS原则应用,掌握泛型编程核心技巧。
category: Java
tag:
- Java基础
head:
- - meta
- name: keywords
- content: 泛型,通配符,类型擦除,上界通配符,下界通配符,PECS,泛型方法
- - - meta
- - name: description
- content: 解析 Java 泛型与通配符的语法与原理,涵盖类型擦除、边界与 PECS 原则等高频知识点。
+ content: Java泛型,通配符,类型擦除,泛型边界,PECS原则,泛型方法,上界下界通配符,泛型接口
---
-**泛型&通配符** 相关的面试题为我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)(点击链接即可查看详细介绍以及获取方法)中。
+## 泛型
+
+### 什么是泛型?有什么作用?
+
+**Java 泛型(Generics)** 是 JDK 5 中引入的一个新特性。使用泛型参数,可以增强代码的可读性以及稳定性。**如无特别说明,以下行为以 Java 8 为准。**
+
+编译器可以对泛型参数进行检测,并且通过泛型参数可以指定传入的对象类型。比如 `ArrayList -可以看出,AOT 的主要优势在于启动时间、内存占用和打包体积。JIT 的主要优势在于具备更高的极限处理能力,可以降低请求的最大延迟。
+可以看出,**AOT 的主要优势在于启动时间、内存占用和打包体积**。**JIT 的主要优势在于具备更高的极限处理能力**,可以降低请求的最大延迟。
提到 AOT 就不得不提 [GraalVM](https://www.graalvm.org/) 了!GraalVM 是一种高性能的 JDK(完整的 JDK 发行版本),它可以运行 Java 和其他 JVM 语言,以及 JavaScript、Python 等非 JVM 语言。 GraalVM 不仅能提供 AOT 编译,还能提供 JIT 编译。感兴趣的同学,可以去看看 GraalVM 的官方文档:
-可以看出,AOT 的主要优势在于启动时间、内存占用和打包体积。JIT 的主要优势在于具备更高的极限处理能力,可以降低请求的最大延迟。
+可以看出,**AOT 的主要优势在于启动时间、内存占用和打包体积**。**JIT 的主要优势在于具备更高的极限处理能力**,可以降低请求的最大延迟。
提到 AOT 就不得不提 [GraalVM](https://www.graalvm.org/) 了!GraalVM 是一种高性能的 JDK(完整的 JDK 发行版本),它可以运行 Java 和其他 JVM 语言,以及 JavaScript、Python 等非 JVM 语言。 GraalVM 不仅能提供 AOT 编译,还能提供 JIT 编译。感兴趣的同学,可以去看看 GraalVM 的官方文档:继续下一次循环"] + L3 -->|"break"| Break["跳出整个循环"] + L3 -->|"无"| L1 + Continue --> L1 + end + + Break --> AfterLoop["循环后的代码"] + L1 -->|"不满足"| AfterLoop + AfterLoop --> L4{{"遇到 return?"}} + L4 -->|"是"| Return["结束整个方法"] + L4 -->|"否"| End["方法正常结束"] + end + + classDef start fill:#E99151,color:#fff,rx:10,ry:10 + classDef loop fill:#4CA497,color:#fff,rx:10,ry:10 + classDef decision fill:#00838F,color:#fff,rx:10,ry:10 + classDef alert fill:#C44545,color:#fff,rx:10,ry:10 + + class Start,End start + class L1,L2,AfterLoop loop + class L3,L4 decision + class Continue,Break,Return alert + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + 思考一下:下列语句的运行结果是什么? ```java @@ -454,6 +562,37 @@ Java 中有 8 种基本数据类型,分别为: - 1 种字符类型:`char` - 1 种布尔型:`boolean`。 +```mermaid +flowchart TB + Root["Java 8种基本数据类型"] --> Numeric["数字类型(6种)"] + Root --> Char["字符类型"] + Root --> Bool["布尔类型"] + + Numeric --> IntType["整数型(4种)"] + Numeric --> FloatType["浮点型(2种)"] + + IntType --> byte["byte
8位"] + IntType --> short["short
16位"] + IntType --> int["int
32位"] + IntType --> long["long
64位"] + + FloatType --> float["float
32位"] + FloatType --> double["double
64位"] + + Char --> char["char
16位"] + Bool --> boolean["boolean
1位"] + + classDef root fill:#E99151,color:#fff,rx:10,ry:10 + classDef category fill:#00838F,color:#fff,rx:10,ry:10 + classDef type fill:#4CA497,color:#fff,rx:10,ry:10 + + class Root root + class Numeric,Char,Bool,IntType,FloatType category + class byte,short,int,long,float,double,char,boolean type + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + 这 8 种基本数据类型的默认值以及所占空间的大小如下: | 基本类型 | 位数 | 字节 | 默认值 | 取值范围 | @@ -497,7 +636,7 @@ Java 中有 8 种基本数据类型,分别为: public class Test { // 成员变量,存放在堆中 int a = 10; - // 被 static 修饰的成员变量,JDK 1.7 及之前位于方法区,1.8 后存放于元空间,均不存放于堆中。 + // 被 static 修饰的成员变量,JDK 1.6 及之前位于永久代,1.7 后移出永久代,一直存放在堆中。 // 变量属于类,不属于对象。 static int b = 20; @@ -604,8 +743,38 @@ System.out.println(i1==i2); **什么是自动拆装箱?** -- **装箱**:将基本类型用它们对应的引用类型包装起来; -- **拆箱**:将包装类型转换为基本数据类型; +- **装箱(Boxing)**:将基本类型用它们对应的引用类型包装起来; +- **拆箱(Unboxing)**:将包装类型转换为基本数据类型; + +```mermaid +flowchart LR + subgraph Row["装箱与拆箱对比"] + direction LR + style Row fill:#F0F2F5,stroke:#E0E6ED,stroke-width:1.5px + + subgraph Unboxing["拆箱过程"] + direction LR + style Unboxing fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + D["Integer obj"] -->|"自动拆箱"| E["obj.intValue()"] + E --> F["int 基本类型"] + end + + subgraph Boxing["装箱过程"] + direction LR + style Boxing fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + A["int i = 10"] -->|"自动装箱"| B["Integer.valueOf(10)"] + B --> C["Integer 对象"] + end + end + + classDef core fill:#4CA497,color:#fff,rx:10,ry:10 + classDef highlight fill:#E99151,color:#fff,rx:10,ry:10 + + class A,D core + class C,F highlight + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` 举例: @@ -677,9 +846,9 @@ System.out.println(b);// 0.099999905 System.out.println(a == b);// false ``` -为什么会出现这个问题呢? +**为什么会出现这个问题呢?** -这个和计算机保存浮点数的机制有很大关系。我们知道计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。这也就是解释了为什么浮点数没有办法用二进制精确表示。 +这个和计算机保存浮点数的机制有很大关系。我们知道计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况。这也就解释了为什么浮点数没有办法用二进制精确表示。 就比如说十进制下的 0.2 就没办法精确转换成二进制小数: @@ -738,6 +907,8 @@ System.out.println(l + 1 == Long.MIN_VALUE); // true ### ⭐️成员变量与局部变量的区别? +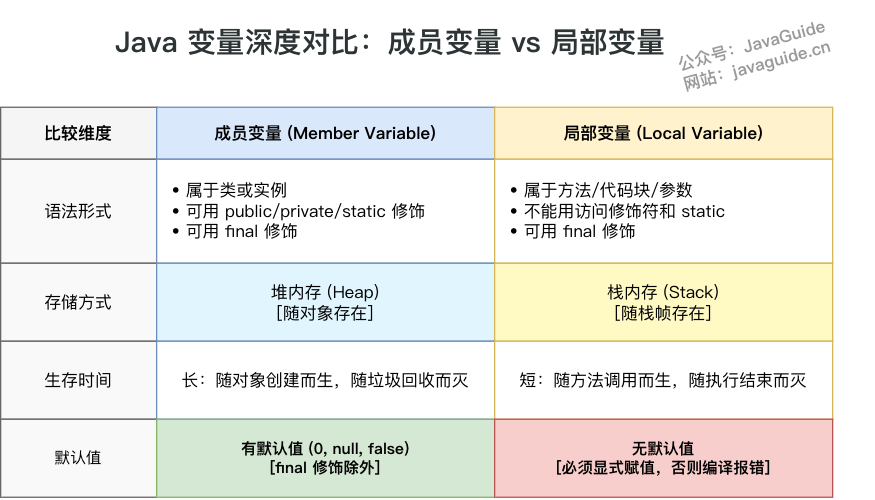 + - **语法形式**:从语法形式上看,成员变量是属于类的,而局部变量是在代码块或方法中定义的变量或是方法的参数;成员变量可以被 `public`,`private`,`static` 等修饰符所修饰,而局部变量不能被访问控制修饰符及 `static` 所修饰;但是,成员变量和局部变量都能被 `final` 所修饰。 - **存储方式**:从变量在内存中的存储方式来看,如果成员变量是使用 `static` 修饰的,那么这个成员变量是属于类的,如果没有使用 `static` 修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。 - **生存时间**:从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动生成,随着方法的调用结束而消亡。 @@ -796,6 +967,8 @@ public class VariableExample { 静态变量也就是被 `static` 关键字修饰的变量。它可以被类的所有实例共享,无论一个类创建了多少个对象,它们都共享同一份静态变量。也就是说,静态变量只会被分配一次内存,即使创建多个对象,这样可以节省内存。 +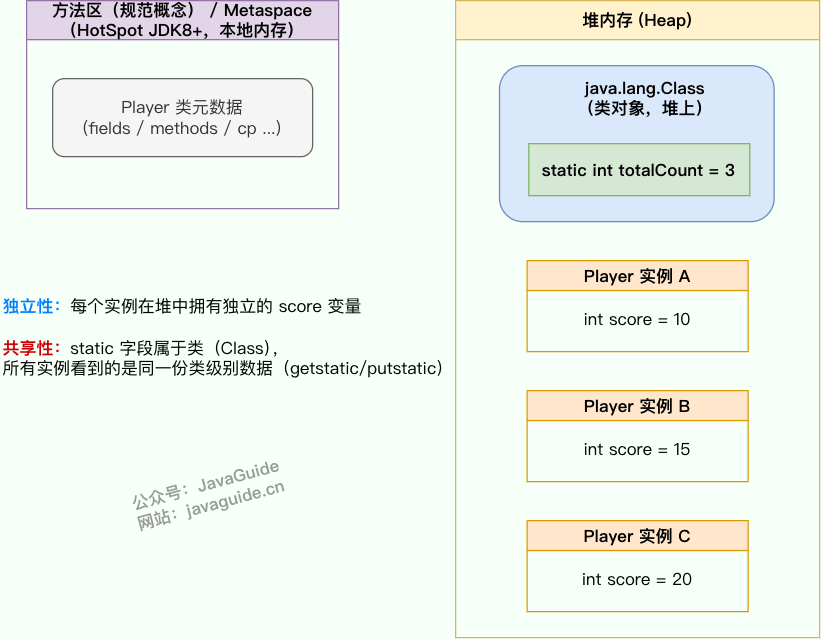 + 静态变量是通过类名来访问的,例如`StaticVariableExample.staticVar`(如果被 `private`关键字修饰就无法这样访问了)。 ```java @@ -817,7 +990,7 @@ public class ConstantVariableExample { ### 字符型常量和字符串常量的区别? - **形式** : 字符常量是单引号引起的一个字符,字符串常量是双引号引起的 0 个或若干个字符。 -- **含义** : 字符常量相当于一个整型值( ASCII 值),可以参加表达式运算; 字符串常量代表一个地址值(该字符串在内存中存放位置)。 +- **含义** : 字符常量相当于一个整型值(ASCII 值),可以参加表达式运算; 字符串常量代表一个地址值(该字符串在内存中存放位置)。 - **占内存大小**:字符常量只占 2 个字节; 字符串常量占若干个字节。 ⚠️ 注意 `char` 在 Java 中占两个字节。 @@ -862,7 +1035,7 @@ public void f1() { // 下面这个方法也没有返回值,虽然用到了 return public void f(int a) { if (...) { - // 表示结束方法的执行,下方的输出语句不会执行 + // 表示结束方法的执行,下方的输出语句不会执行 return; } System.out.println(a); diff --git a/docs/java/basis/java-basic-questions-02.md b/docs/java/basis/java-basic-questions-02.md index 42455193f45..2aa14b0946a 100644 --- a/docs/java/basis/java-basic-questions-02.md +++ b/docs/java/basis/java-basic-questions-02.md @@ -1,15 +1,13 @@ --- title: Java基础常见面试题总结(中) +description: Java面向对象编程核心知识点总结:涵盖封装继承多态三大特性、接口与抽象类区别、Object类方法详解、深拷贝浅拷贝、String/StringBuffer/StringBuilder对比等,帮助快速掌握Java OOP精髓。 category: Java tag: - Java基础 head: - - meta - name: keywords - content: 面向对象, 面向过程, OOP, POP, Java对象, 构造方法, 封装, 继承, 多态, 接口, 抽象类, 默认方法, 静态方法, 私有方法, 深拷贝, 浅拷贝, 引用拷贝, Object类, equals, hashCode, ==, 字符串, String, StringBuffer, StringBuilder, 不可变性, 字符串常量池, intern, 字符串拼接, Java基础, 面试题 - - - meta - - name: description - content: 全网质量最高的Java基础常见知识点和面试题总结,希望对你有帮助! + content: 面向对象,封装继承多态,接口,抽象类,深拷贝浅拷贝,Object类,equals,hashCode,String,字符串常量池,Java面试题 --- @@ -97,7 +95,7 @@ public class Main { 我们直接定义了圆的半径,并使用该半径直接计算出圆的面积和周长。 -### 创建一个对象用什么运算符?对象实体与对象引用有何不同? +### 创建一个对象用什么运算符?对象实例与对象引用有何不同? new 运算符,new 创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。 @@ -210,6 +208,39 @@ public class Student { - 多态不能调用“只在子类存在但在父类不存在”的方法; - 如果子类重写了父类的方法,真正执行的是子类重写的方法,如果子类没有重写父类的方法,执行的是父类的方法。 +```mermaid +flowchart LR + subgraph OOP["面向对象三大特征"] + style OOP fill:#F0F2F5,stroke:#E0E6ED,stroke-width:1.5px + + subgraph Encapsulation["封装 Encapsulation"] + style Encapsulation fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + E1["隐藏内部状态"]:::core + E2["提供公共方法"]:::core + E3["保护数据安全"]:::core + end + + subgraph Inheritance["继承 Inheritance"] + style Inheritance fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + I1["代码复用"]:::core + I2["扩展功能"]:::core + I3["单继承限制"]:::highlight + end + + subgraph Polymorphism["多态 Polymorphism"] + style Polymorphism fill:#F5F7FA,stroke:#E0E6ED,stroke-width:1.5px + P1["父类引用指向子类"]:::core + P2["运行时动态绑定"]:::core + P3["方法重写实现"]:::core + end + end + + classDef core fill:#4CA497,color:#fff,rx:10,ry:10 + classDef highlight fill:#E99151,color:#fff,rx:10,ry:10 + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + ### ⭐️接口和抽象类有什么共同点和区别? #### 接口和抽象类的共同点 @@ -276,6 +307,18 @@ public interface MyInterface { ### 深拷贝和浅拷贝区别了解吗?什么是引用拷贝? +```mermaid +flowchart LR + Copy["对象拷贝"] --> RefCopy["引用拷贝
两个引用指向同一对象"] + Copy --> ShallowCopy["浅拷贝
复制基本类型,共享引用类型"] + Copy --> DeepCopy["深拷贝
递归复制所有属性"] + + classDef main fill:#005D7B,color:#fff,rx:10,ry:10 + class Copy main + + linkStyle default stroke-width:1.5px,opacity:0.8 +``` + 关于深拷贝和浅拷贝区别,我这里先给结论: - **浅拷贝**:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。 @@ -359,9 +402,9 @@ System.out.println(person1.getAddress() == person1Copy.getAddress()); **那什么是引用拷贝呢?** 简单来说,引用拷贝就是两个不同的引用指向同一个对象。 -我专门画了一张图来描述浅拷贝、深拷贝、引用拷贝: +我专门画了一张图来描述浅拷贝、深拷贝和引用拷贝: -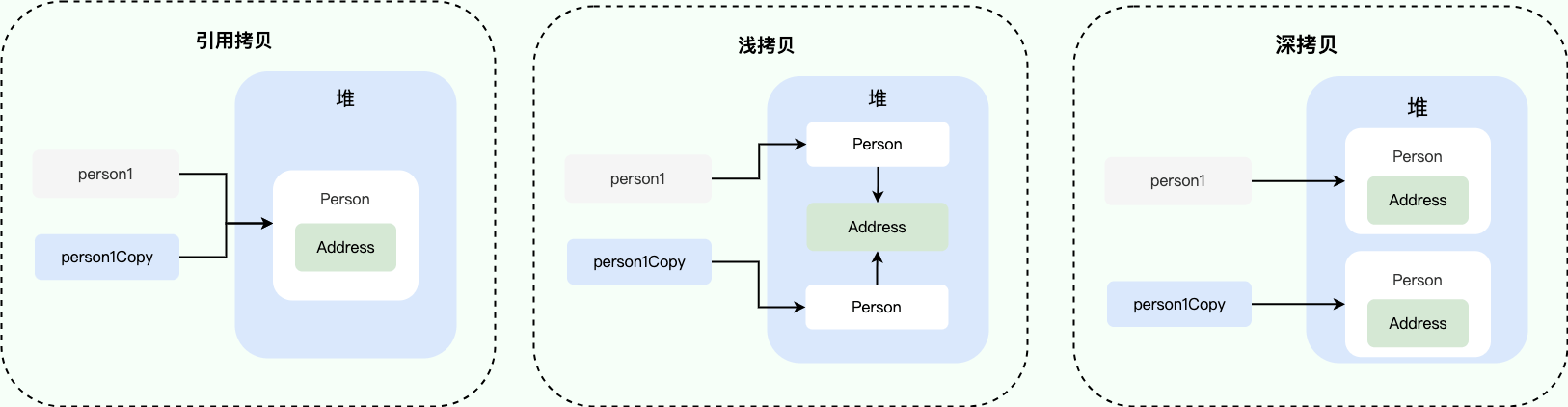 + ## ⭐️Object @@ -529,7 +572,7 @@ public native int hashCode(); **那为什么两个对象有相同的 `hashCode` 值,它们也不一定是相等的?** -因为 `hashCode()` 所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。越糟糕的哈希算法越容易碰撞,但这也与数据值域分布的特性有关(所谓哈希碰撞也就是指的是不同的对象得到相同的 `hashCode` )。 +因为 `hashCode()` 所使用的哈希算法也许刚好会让多个对象传回相同的哈希值。越糟糕的哈希算法越容易碰撞,但这也与数据值域分布的特性有关(所谓哈希碰撞就是指不同的对象得到相同的 `hashCode` )。 总结下来就是: @@ -720,6 +763,8 @@ System.out.println(aa==bb); // true 下面开始详细分析。 +下面开始详细分析。 + 1、如果字符串常量池中不存在字符串对象 “abc”,那么它首先会在字符串常量池中创建字符串对象 "abc",然后在堆内存中再创建其中一个字符串对象 "abc"。 示例代码(JDK 1.8): diff --git a/docs/java/basis/java-basic-questions-03.md b/docs/java/basis/java-basic-questions-03.md index 8f9dcc17073..a68ac71ca14 100644 --- a/docs/java/basis/java-basic-questions-03.md +++ b/docs/java/basis/java-basic-questions-03.md @@ -1,18 +1,16 @@ --- title: Java基础常见面试题总结(下) +description: Java高级特性面试题总结:深入讲解异常处理机制、泛型原理、反射应用、注解使用、SPI机制、序列化、IO流模型(BIO/NIO/AIO)、语法糖等核心知识点。 category: Java tag: - Java基础 head: - - meta - name: keywords - content: Java异常处理, Java泛型, Java反射, Java注解, Java SPI机制, Java序列化, Java反序列化, Java IO流, Java语法糖, Java基础面试题, Checked Exception, Unchecked Exception, try-with-resources, 反射应用场景, 序列化协议, BIO, NIO, AIO, IO模型 - - - meta - - name: description - content: 全网质量最高的Java基础常见知识点和面试题总结,希望对你有帮助! + content: Java异常,泛型,反射,注解,SPI,序列化,IO流,语法糖,try-with-resources,BIO NIO AIO,Java面试题 --- - + ## 异常 diff --git a/docs/java/basis/java-keyword-summary.md b/docs/java/basis/java-keyword-summary.md index 2dee3f100ad..d69513a26c2 100644 --- a/docs/java/basis/java-keyword-summary.md +++ b/docs/java/basis/java-keyword-summary.md @@ -1,15 +1,13 @@ --- title: Java 关键字总结 +description: 系统总结Java常用关键字:详解final、static、this、super、volatile、transient、synchronized等关键字用法与区别,助力Java开发者掌握核心语法。 category: Java tag: - Java基础 head: - - meta - name: keywords - content: Java 关键字,final,static,this,super,abstract,interface,enum,volatile,transient - - - meta - - name: description - content: 梳理常见 Java 关键字的语义与用法差异,便于快速查阅与掌握。 + content: Java关键字,final关键字,static关键字,this关键字,super关键字,volatile,transient,synchronized --- # final,static,this,super 关键字总结 diff --git a/docs/java/basis/proxy.md b/docs/java/basis/proxy.md index dafd1b436aa..1882d0f8c4e 100644 --- a/docs/java/basis/proxy.md +++ b/docs/java/basis/proxy.md @@ -1,15 +1,13 @@ --- title: Java 代理模式详解 +description: 详解Java代理模式原理与实现:对比静态代理与动态代理差异,深入分析JDK动态代理和CGLIB代理机制,理解AOP横切关注点实现。 category: Java tag: - Java基础 head: - - meta - name: keywords - content: 代理模式,静态代理,动态代理,JDK 动态代理,CGLIB,横切增强,设计模式 - - - meta - - name: description - content: 详解 Java 代理模式的静态与动态实现,理解 JDK/CGLIB 动态代理的原理与应用场景。 + content: Java代理模式,静态代理,动态代理,JDK动态代理,CGLIB代理,AOP,设计模式,代理实现 --- ## 1. 代理模式 diff --git a/docs/java/basis/reflection.md b/docs/java/basis/reflection.md index a951992c95e..c4a233e908f 100644 --- a/docs/java/basis/reflection.md +++ b/docs/java/basis/reflection.md @@ -1,15 +1,13 @@ --- title: Java 反射机制详解 +description: 深入讲解Java反射机制原理与应用:掌握Class、Method、Field核心API,理解反射在Spring、MyBatis等框架中的应用,学习动态代理实现。 category: Java tag: - Java基础 head: - - meta - name: keywords - content: 反射,Class,Method,Field,动态代理,运行时分析,框架原理 - - - meta - - name: description - content: 系统讲解 Java 反射的核心概念与常见用法,结合动态代理与框架底层机制理解运行时能力。 + content: Java反射,反射机制,Class类,Method方法,Field字段,动态代理,框架原理,运行时操作 --- ## 何为反射? diff --git a/docs/java/basis/serialization.md b/docs/java/basis/serialization.md index a046a06199d..254032b9ef7 100644 --- a/docs/java/basis/serialization.md +++ b/docs/java/basis/serialization.md @@ -1,15 +1,13 @@ --- title: Java 序列化详解 +description: 深入解析Java序列化与反序列化机制:详解Serializable接口、transient关键字、serialVersionUID作用、序列化协议选择及RPC、缓存等应用场景。 category: Java tag: - Java基础 head: - - meta - name: keywords - content: 序列化,反序列化,Serializable,transient,serialVersionUID,ObjectInputStream,ObjectOutputStream,协议 - - - meta - - name: description - content: 讲解 Java 对象的序列化/反序列化机制与关键细节,涵盖 transient、版本号与常见应用场景。 + content: Java序列化,反序列化,Serializable接口,transient关键字,serialVersionUID,序列化协议,对象持久化 --- ## 什么是序列化和反序列化? diff --git a/docs/java/basis/spi.md b/docs/java/basis/spi.md index a2a7bccb7d3..7392d0f3168 100644 --- a/docs/java/basis/spi.md +++ b/docs/java/basis/spi.md @@ -1,15 +1,13 @@ --- title: Java SPI 机制详解 +description: 全面讲解Java SPI机制原理与应用:理解ServiceLoader服务发现机制、SPI在JDBC/Dubbo/Spring中的应用、与API对比及最佳实践。 category: Java tag: - Java基础 head: - - meta - name: keywords - content: Java SPI机制 - - - meta - - name: description - content: SPI 即 Service Provider Interface ,字面意思就是:“服务提供者的接口”,我的理解是:专门提供给服务提供者或者扩展框架功能的开发者去使用的一个接口。SPI 将服务接口和具体的服务实现分离开来,将服务调用方和服务实现者解耦,能够提升程序的扩展性、可维护性。修改或者替换服务实现并不需要修改调用方。 + content: Java SPI,SPI机制,ServiceLoader,服务发现,插件化,JDBC驱动加载,Dubbo扩展,SPI应用 --- > 本文来自 [Kingshion](https://github.com/jjx0708) 投稿。欢迎更多朋友参与到 JavaGuide 的维护工作,这是一件非常有意义的事情。详细信息请看:[JavaGuide 贡献指南](https://javaguide.cn/javaguide/contribution-guideline.html) 。 diff --git a/docs/java/basis/syntactic-sugar.md b/docs/java/basis/syntactic-sugar.md index 31444ac8385..e0b15493d2b 100644 --- a/docs/java/basis/syntactic-sugar.md +++ b/docs/java/basis/syntactic-sugar.md @@ -1,15 +1,13 @@ --- title: Java 语法糖详解 +description: 深入剖析Java语法糖原理:详解自动装箱拆箱、泛型擦除、增强for、可变参数、枚举、Lambda等语法糖的编译期实现机制,避免使用误区。 category: Java tag: - Java基础 head: - - meta - name: keywords - content: 语法糖,自动装箱拆箱,泛型,增强 for,可变参数,枚举,内部类,类型推断 - - - meta - - name: description - content: 总结 Java 常见语法糖及编译期的“解糖”原理,帮助在提升效率的同时理解底层机制并避免误用。 + content: Java语法糖,自动装箱拆箱,泛型擦除,增强for循环,可变参数,枚举,内部类,Lambda表达式,语法糖原理 --- > 作者:Hollis @@ -690,36 +688,21 @@ public static transient void main(String args[]) throwable = throwable2; throw throwable2; } - if(br != null) - if(throwable != null) - try - { - br.close(); - } - catch(Throwable throwable1) - { - throwable.addSuppressed(throwable1); - } - else - br.close(); - break MISSING_BLOCK_LABEL_113; //该标签为反编译工具的生成错误,(不是Java语法本身的内容)属于反编译工具的临时占位符。正常情况下编译器生成的字节码不会包含这种无效标签。 - Exception exception; - exception; + finally + { if(br != null) if(throwable != null) try { br.close(); } - catch(Throwable throwable3) - { - throwable.addSuppressed(throwable3); + catch(Throwable throwable1) + { + throwable.addSuppressed(throwable1); } else br.close(); - throw exception; - IOException ioexception; - ioexception; + } } } ``` @@ -878,9 +861,9 @@ for (Student stu : students) { 会抛出`ConcurrentModificationException`异常。 -Iterator 是工作在一个独立的线程中,并且拥有一个 mutex 锁。 Iterator 被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量发生变化时,这个索引表的内容不会同步改变,所以当索引指针往后移动的时候就找不到要迭代的对象,所以按照 fail-fast 原则 Iterator 会马上抛出`java.util.ConcurrentModificationException`异常。 +这里涉及集合的 **fail-fast(快速失败)** 机制。以 `ArrayList` 为例,其内部维护了一个 `modCount` 计数器,每次对集合结构进行修改(如添加、删除)时都会递增该计数器。当创建 `Iterator` 时,会将当前的 `modCount` 记录为 `expectedModCount`。在每次调用 `next()` 时,`Iterator` 都会检查 `modCount` 是否等于 `expectedModCount`,如果不等,说明集合在遍历期间被其他方式修改了,就会抛出`java.util.ConcurrentModificationException`异常。 -所以 `Iterator` 在工作的时候是不允许被迭代的对象被改变的。但你可以使用 `Iterator` 本身的方法`remove()`来删除对象,`Iterator.remove()` 方法会在删除当前迭代对象的同时维护索引的一致性。 +所以 `Iterator` 在工作的时候是不允许被迭代的对象被改变的。但你可以使用 `Iterator` 本身的方法`remove()`来删除对象,`Iterator.remove()` 方法会在删除元素后同步更新 `expectedModCount`,从而避免触发该异常。 ## 总结 diff --git a/docs/java/basis/unsafe.md b/docs/java/basis/unsafe.md index 078619421c0..9acffc941cd 100644 --- a/docs/java/basis/unsafe.md +++ b/docs/java/basis/unsafe.md @@ -1,15 +1,13 @@ --- title: Java 魔法类 Unsafe 详解 +description: 深入解析Java魔法类Unsafe:讲解Unsafe直接内存操作、CAS原子操作、对象实例化等底层能力,理解JUC并发工具类实现原理及使用风险。 category: Java tag: - Java基础 head: - - meta - name: keywords - content: Unsafe,低级操作,内存访问,CAS,堆外内存,本地方法,风险 - - - meta - - name: description - content: 介绍 sun.misc.Unsafe 的能力与典型用法,涵盖内存与对象操作、CAS 支持及风险与限制。 + content: Unsafe类,内存操作,CAS原子操作,堆外内存,直接内存,sun.misc.Unsafe,JUC底层实现 --- > 本文整理完善自下面这两篇优秀的文章: @@ -561,80 +559,31 @@ private void increment(int x){ 如果你把上面这段代码贴到 IDE 中运行,会发现并不能得到目标输出结果。有朋友已经在 Github 上指出了这个问题:[issue#2650](https://github.com/Snailclimb/JavaGuide/issues/2650)。下面是修正后的代码: ```java -private volatile int a = 0; // 共享变量,初始值为 0 -private static final Unsafe unsafe; -private static final long fieldOffset; - -static { - try { - // 获取 Unsafe 实例 - Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe"); - theUnsafe.setAccessible(true); - unsafe = (Unsafe) theUnsafe.get(null); - // 获取 a 字段的内存偏移量 - fieldOffset = unsafe.objectFieldOffset(CasTest.class.getDeclaredField("a")); - } catch (Exception e) { - throw new RuntimeException("Failed to initialize Unsafe or field offset", e); - } -} - -public static void main(String[] args) { - CasTest casTest = new CasTest(); - - Thread t1 = new Thread(() -> { - for (int i = 1; i <= 4; i++) { - casTest.incrementAndPrint(i); - } - }); - - Thread t2 = new Thread(() -> { - for (int i = 5; i <= 9; i++) { - casTest.incrementAndPrint(i); - } - }); - - t1.start(); - t2.start(); - - // 等待线程结束,以便观察完整输出 (可选,用于演示) - try { - t1.join(); - t2.join(); - } catch (InterruptedException e) { - Thread.currentThread().interrupt(); - } -} - // 将递增和打印操作封装在一个原子性更强的方法内 private void incrementAndPrint(int targetValue) { while (true) { int currentValue = a; // 读取当前 a 的值 - // 只有当 a 的当前值等于目标值的前一个值时,才尝试更新 - if (currentValue == targetValue - 1) { - if (unsafe.compareAndSwapInt(this, fieldOffset, currentValue, targetValue)) { - // CAS 成功,说明成功将 a 更新为 targetValue - System.out.print(targetValue + " "); - break; // 成功更新并打印后退出循环 - } - // 如果 CAS 失败,意味着在读取 currentValue 和执行 CAS 之间,a 的值被其他线程修改了, - // 此时 currentValue 已经不是 a 的最新值,需要重新读取并重试。 + // 如果当前值已经达到或超过目标值,说明已被其他线程处理,跳过 + if (currentValue >= targetValue) { + return; } - // 如果 currentValue != targetValue - 1,说明还没轮到当前线程更新, - // 或者已经被其他线程更新超过了,让出CPU给其他线程机会。 - // 对于严格顺序递增的场景,如果 current > targetValue - 1,可能意味着逻辑错误或死循环, - // 但在此示例中,我们期望线程能按顺序执行。 - Thread.yield(); // 提示CPU调度器可以切换线程,减少无效自旋 + // 尝试 CAS 操作:如果当前值等于 targetValue - 1,则原子地设置为 targetValue + if (unsafe.compareAndSwapInt(this, fieldOffset, currentValue, targetValue)) { + // CAS 成功后立即打印,确保打印的就是本次设置的值 + System.out.print(targetValue + " "); + return; + } + // CAS 失败,重新读取并重试 } } ``` - 在上述例子中,我们创建了两个线程,它们都尝试修改共享变量 a。每个线程在调用 `incrementAndPrint(targetValue)` 方法时: 1. 会先读取 a 的当前值 `currentValue`。 2. 检查 `currentValue` 是否等于 `targetValue - 1` (即期望的前一个值)。 3. 如果条件满足,则调用`unsafe.compareAndSwapInt()` 尝试将 `a` 从 `currentValue` 更新到 `targetValue`。 4. 如果 CAS 操作成功(返回 true),则打印 `targetValue` 并退出循环。 -5. 如果 CAS 操作失败,或者 `currentValue` 不满足条件,则当前线程会继续循环(自旋),并通过 `Thread.yield()` 尝试让出 CPU,直到成功更新并打印或者条件满足。 +5. 如果 CAS 操作失败,说明有其他线程同时竞争,此时会重新读取 `currentValue` 并重试,直到成功为止。 这种机制确保了每个数字(从 1 到 9)只会被成功设置并打印一次,并且是按顺序进行的。 diff --git a/docs/java/basis/why-there-only-value-passing-in-java.md b/docs/java/basis/why-there-only-value-passing-in-java.md index e3d5a20c5fb..18cc70caee8 100644 --- a/docs/java/basis/why-there-only-value-passing-in-java.md +++ b/docs/java/basis/why-there-only-value-passing-in-java.md @@ -1,15 +1,13 @@ --- title: Java 值传递详解 +description: 详解Java为什么只有值传递:通过示例深入分析Java参数传递机制,澄清值传递与引用传递的常见误区,理解形参实参本质区别。 category: Java tag: - Java基础 head: - - meta - name: keywords - content: 值传递,引用传递,参数传递,对象引用,示例解析,方法调用 - - - meta - - name: description - content: 通过示例解释 Java 参数传递模型,澄清值传递与引用传递的常见误区。 + content: Java值传递,引用传递,参数传递,形参实参,对象引用,方法调用,Java传参机制 --- 开始之前,我们先来搞懂下面这两个概念: diff --git a/docs/java/collection/arrayblockingqueue-source-code.md b/docs/java/collection/arrayblockingqueue-source-code.md index 4a8d473f8d1..24631e5954b 100644 --- a/docs/java/collection/arrayblockingqueue-source-code.md +++ b/docs/java/collection/arrayblockingqueue-source-code.md @@ -1,15 +1,13 @@ --- title: ArrayBlockingQueue 源码分析 +description: ArrayBlockingQueue源码深度解析:详解有界阻塞队列实现、生产者消费者模式应用、ReentrantLock+Condition并发控制、线程池工作队列机制。 category: Java tag: - Java集合 head: - - meta - name: keywords - content: ArrayBlockingQueue,阻塞队列,生产者消费者,有界队列,JUC,put,take,线程池,ReentrantLock,Condition - - - meta - - name: description - content: 讲解 ArrayBlockingQueue 的有界阻塞队列实现与典型生产者-消费者使用,结合线程池工作队列分析锁与条件的并发设计。 + content: ArrayBlockingQueue源码,阻塞队列,有界队列,生产者消费者模式,ReentrantLock,Condition,线程池工作队列 --- ## 阻塞队列简介 diff --git a/docs/java/collection/arraylist-source-code.md b/docs/java/collection/arraylist-source-code.md index ee9b8b496de..f2db885d25e 100644 --- a/docs/java/collection/arraylist-source-code.md +++ b/docs/java/collection/arraylist-source-code.md @@ -1,15 +1,13 @@ --- title: ArrayList 源码分析 +description: ArrayList源码深度解析:详解ArrayList底层数组结构、1.5倍扩容机制、RandomAccess快速随机访问、序列化实现及与Vector性能对比。 category: Java tag: - Java集合 head: - - meta - name: keywords - content: ArrayList,动态数组,ensureCapacity,RandomAccess,扩容机制,序列化,add/remove,索引访问,性能,Vector 区别,列表实现 - - - meta - - name: description - content: 系统梳理 ArrayList 的底层原理与常见用法,包含动态数组结构、扩容策略、接口实现以及与 Vector 的差异与性能特点。 + content: ArrayList源码,ArrayList扩容机制,动态数组,RandomAccess,ArrayList序列化,ArrayList与Vector区别 --- @@ -29,7 +27,7 @@ public class ArrayList
并设置 Capture 得到的值 + + Note over C: 5. 业务逻辑执行
get context = "A" + + Note over C: 6. Restore + Note right of C: 恢复工作线程原有 TTL 值
防止上下文污染 + + C-->>P: 7. 任务执行结束 + +``` + +也就是说,TTL 的本质是在任务提交时 Capture 上下文,在任务执行前 Replay 上下文,在任务结束后 Restore 线程状态,从而安全地支持线程池中的 `ThreadLocal` 传递。 + +TTL 提供了两种主要的接入方式,可根据侵入性要求和改造成本进行选择。 + +**1. 显式包装(手动接入)** + +使用 `TtlRunnable.get(Runnable)` 或 `TtlCallable.get(Callable)` 对任务进行包装,使用 `TtlExecutors.getTtlExecutor(Executor)`、`getTtlExecutorService(...)` 对线程池进行包装。这种接入方式清晰可控,但需要业务代码配合,存在一定侵入性。 + +下面这段代码展示了 TTL 通过 CRR,在支持线程池复用和拒绝策略的前提下,安全地传递并隔离 `ThreadLocal` 上下文。 + +```java +public class TtlContextHolder { + private static final Logger log = LoggerFactory.getLogger(TtlContextHolder.class); + + // 1. 使用 static final 确保 TTL 实例不被重复创建,防止内存泄漏 + // 重写 copy 方法(可选):如果是引用类型,建议实现深拷贝 + private static final TransmittableThreadLocal
Java Stack):::main + + %% 分支1:定义与对比 + Root --> Comp[基本特征]:::compare + Comp --> Comp1[线程私有,随线程创建/销毁]:::compare + Comp --> Comp2[服务对象: Java 方法]:::compare + Comp --> Comp3[栈帧先进后出]:::compare + + %% 分支2:栈帧结构 + Root --> Struct[栈帧结构]:::structure + Struct --> S1[局部变量表、操作数栈、动态链接、出口信息]:::structure + + %% 分支3:异常情况 + Root --> Err[异常情况]:::error + Err --> Err1[StackOverflowError: 栈深度溢出]:::error + Err --> Err2[OutOfMemoryError: 内存扩展失败]:::error + + %% 线条样式 + linkStyle default stroke:#005D7B,stroke-width:1.5px,opacity:0.8 +``` + 与程序计数器一样,Java 虚拟机栈(后文简称栈)也是线程私有的,它的生命周期和线程相同,随着线程的创建而创建,随着线程的死亡而死亡。 栈绝对算的上是 JVM 运行时数据区域的一个核心,除了一些 Native 方法调用是通过本地方法栈实现的(后面会提到),其他所有的 Java 方法调用都是通过栈来实现的(也需要和其他运行时数据区域比如程序计数器配合)。 @@ -93,7 +165,12 @@ Java 虚拟机规范对于运行时数据区域的规定是相当宽松的。以 栈空间虽然不是无限的,但一般正常调用的情况下是不会出现问题的。不过,如果函数调用陷入无限循环的话,就会导致栈中被压入太多栈帧而占用太多空间,导致栈空间过深。那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出 `StackOverFlowError` 错误。 -Java 方法有两种返回方式,一种是 return 语句正常返回,一种是抛出异常。不管哪种返回方式,都会导致栈帧被弹出。也就是说, **栈帧随着方法调用而创建,随着方法结束而销毁。无论方法正常完成还是异常完成都算作方法结束。** +**Java 方法有两种返回方式**: + +- **正常返回**:执行return语句,返回值传递给调用者。 +- **异常返回**:方法执行过程中抛出异常且未被捕获。 + +不管哪种返回方式,都会导致栈帧被弹出。也就是说, **栈帧随着方法调用而创建,随着方法结束而销毁。无论方法正常完成还是异常完成都算作方法结束。** 除了 `StackOverFlowError` 错误之外,栈还可能会出现`OutOfMemoryError`错误,这是因为如果栈的内存大小可以动态扩展, 那么当虚拟机在动态扩展栈时无法申请到足够的内存空间,则抛出`OutOfMemoryError`异常。 @@ -106,6 +183,40 @@ Java 方法有两种返回方式,一种是 return 语句正常返回,一种 ### 本地方法栈 +```mermaid +graph LR + %% 颜色定义 + classDef main fill:#005D7B,color:#fff,rx:10,ry:10; + classDef compare fill:#00838F,color:#fff,rx:10,ry:10; + classDef structure fill:#4CA497,color:#fff,rx:10,ry:10; + classDef implement fill:#E99151,color:#fff,rx:10,ry:10; + classDef error fill:#C44545,color:#fff,rx:10,ry:10; + + %% 核心节点 + Root(本地方法栈):::main + + %% 分支1:定义与对比 + Root --> Comp[定义与对比]:::compare + Comp --> Comp1[作用与虚拟机栈相似]:::compare + Comp --> Comp2[服务对象: Native 方法]:::compare + + %% 分支2:HotSpot 实现 + Root --> Imp[虚拟机实现]:::implement + Imp --> Imp1[HotSpot 与虚拟机栈合二为一]:::implement + + %% 分支3:栈帧结构 + Root --> Struct[栈帧内容]:::structure + Struct --> S1[局部变量表、操作数栈、动态链接、出口信息]:::structure + + %% 分支4:异常情况 + Root --> Err[异常与内存]:::error + Err --> Err1[StackOverflowError: 栈深度溢出]:::error + Err --> Err2[OutOfMemoryError: 内存扩展失败]:::error + + %% 线条样式 + linkStyle default stroke:#005D7B,stroke-width:1.5px,opacity:0.8 +``` + 和虚拟机栈所发挥的作用非常相似,区别是:**虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。** 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。 本地方法被执行的时候,在本地方法栈也会创建一个栈帧,用于存放该本地方法的局部变量表、操作数栈、动态链接、出口信息。 @@ -114,6 +225,40 @@ Java 方法有两种返回方式,一种是 return 语句正常返回,一种 ### 堆 +```mermaid +graph LR + %% 颜色定义 + classDef main fill:#005D7B,color:#fff,rx:10,ry:10; + classDef compare fill:#00838F,color:#fff,rx:10,ry:10; + classDef structure fill:#4CA497,color:#fff,rx:10,ry:10; + classDef implement fill:#E99151,color:#fff,rx:10,ry:10; + classDef error fill:#C44545,color:#fff,rx:10,ry:10; + + %% 核心节点 + Root(Java 堆):::main + + %% 分支1:基本定义与地位 + Root --> Def[定义与地位]:::compare + Def --> Def1[JVM 内存中最大区域]:::compare + Def --> Def2[所有线程共享]:::compare + Def --> Def3[虚拟机启动时创建,生命周期长]:::compare + + %% 分支2:核心用途 + Root --> Use[核心用途]:::structure + Use --> Use1[存放对象实例(非静态字段)]:::structure + Use --> Use2[存放数组数据]:::structure + Use --> Use3[对象内存统一管理]:::structure + + %% 分3:分代结构 (GC 堆) + Root --> GC[分代结构]:::implement + GC --> GC1[新生代:Eden 区 + 两个 Survivor 区]:::implement + GC --> GC2[老年代:Old Generation]:::implement + GC --> GC3[目的:优化垃圾回收效率]:::implement + + %% 线条样式 + linkStyle default stroke:#005D7B,stroke-width:1.5px,opacity:0.8 +``` + Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线程共享的一块内存区域,在虚拟机启动时创建。**此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。** Java 世界中“几乎”所有的对象都在堆中分配,但是,随着 JIT 编译器的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化,所有的对象都分配到堆上也渐渐变得不那么“绝对”了。从 JDK 1.7 开始已经默认开启逃逸分析,如果某些方法中的对象引用没有被返回或者未被外面使用(也就是未逃逸出去),那么对象可以直接在栈上分配内存。 @@ -180,6 +325,40 @@ MaxTenuringThreshold of 20 is invalid; must be between 0 and 15 ### 方法区 +```mermaid +graph LR + %% 颜色定义 + classDef main fill:#005D7B,color:#fff,rx:10,ry:10; + classDef compare fill:#00838F,color:#fff,rx:10,ry:10; + classDef structure fill:#4CA497,color:#fff,rx:10,ry:10; + classDef implement fill:#E99151,color:#fff,rx:10,ry:10; + classDef error fill:#C44545,color:#fff,rx:10,ry:10; + + %% 核心节点 + Root(方法区):::main + + %% 分支1:基本定义与地位 + Root --> Def[定义与地位]:::compare + Def --> Def1[线程共享的内存区域]:::compare + Def --> Def2[JVM 规范定义的逻辑区域]:::compare + Def --> Def3[具体实现随虚拟机而异]:::compare + + %% 分支2:核心存储内容 + Root --> Store[核心存储内容]:::structure + Store --> Store1[类的元数据: 结构/字段/方法信息]:::structure + Store --> Store2[方法的字节码: 原始指令序列]:::structure + Store --> Store3[运行时常量池: 字面量与符号引用]:::structure + + %% 分支3:HotSpot 位置演变 (JDK 7+) + Root --> Change[位置演变与例外]:::implement + Change --> Change1[静态变量: 移至 Java 堆(JDK 7)]:::implement + Change --> Change2[字符串常量池: 移至 Java 堆(JDK 7)]:::implement + Change --> Change3[JIT 代码缓存: 独立 Code Cache 区域]:::implement + + %% 线条样式 + linkStyle default stroke:#005D7B,stroke-width:1.5px,opacity:0.8 +``` + 方法区属于是 JVM 运行时数据区域的一块逻辑区域,是各个线程共享的内存区域。 《Java 虚拟机规范》只是规定了有方法区这么个概念和它的作用,方法区到底要如何实现那就是虚拟机自己要考虑的事情了。也就是说,在不同的虚拟机实现上,方法区的实现是不同的。 @@ -242,6 +421,37 @@ JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1 ### 运行时常量池 +```mermaid +graph LR + %% 颜色定义 + classDef main fill:#005D7B,color:#fff,rx:10,ry:10; + classDef compare fill:#00838F,color:#fff,rx:10,ry:10; + classDef structure fill:#4CA497,color:#fff,rx:10,ry:10; + classDef implement fill:#E99151,color:#fff,rx:10,ry:10; + classDef error fill:#C44545,color:#fff,rx:10,ry:10; + + %% 核心节点 + Root(运行时常量池):::main + + %% 分支1:来源与地位 + Root --> Source[定义与地位]:::compare + Source --> Source1[源自 Class 文件的常量池表]:::compare + Source --> Source2[类加载后存入方法区]:::compare + Source --> Source3[功能类似于高级符号表]:::compare + + %% 分支2:存储内容分类 + Root --> Content[存储内容]:::structure + Content --> Content1[字面量: 文本字符串/常量值等]:::structure + Content --> Content2[符号引用: 类/字段/方法的描述]:::structure + + %% 分支3:异常处理 + Root --> Error[异常情况]:::error + Error --> Error2[无法申请内存时抛出 OutOfMemoryError]:::error + + %% 线条样式 + linkStyle default stroke:#005D7B,stroke-width:1.5px,opacity:0.8 +``` + Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有用于存放编译期生成的各种字面量(Literal)和符号引用(Symbolic Reference)的 **常量池表(Constant Pool Table)** 。 字面量是源代码中的固定值的表示法,即通过字面我们就能知道其值的含义。字面量包括整数、浮点数和字符串字面量。常见的符号引用包括类符号引用、字段符号引用、方法符号引用、接口方法符号。 @@ -258,6 +468,40 @@ Class 文件中除了有类的版本、字段、方法、接口等描述信息 ### 字符串常量池 +```mermaid +graph LR + %% 颜色定义 + classDef main fill:#005D7B,color:#fff,rx:10,ry:10; + classDef compare fill:#00838F,color:#fff,rx:10,ry:10; + classDef structure fill:#4CA497,color:#fff,rx:10,ry:10; + classDef implement fill:#E99151,color:#fff,rx:10,ry:10; + classDef error fill:#C44545,color:#fff,rx:10,ry:10; + + %% 核心节点 + Root(字符串常量池):::main + + %% 分支1:内存位置演进 + Root --> History[内存位置演进]:::compare + History --> Hist1[JDK 1.6: 存在于永久代 PermGen]:::compare + History --> Hist2[JDK 1.7+: 移至堆 Heap 中]:::compare + History --> Hist3[目的: 避免永久代 OOM 且方便 GC]:::compare + + %% 分支2:底层实现结构 + Root --> Impl[底层实现机制]:::structure + Impl --> Impl1[StringTable: 本质是 HashTable]:::structure + Impl --> Impl2[Key: 字符串内容 Hash / Value: 对象引用]:::structure + Impl --> Impl3[固定长度的数组 + 链表结构]:::structure + + %% 分支3:风险与调优 + Root --> Tuning[风险与调优]:::error + Tuning --> Risk1[StringTable 过小导致 Hash 冲突严重]:::error + Tuning --> Risk2[大量 intern 导致性能下降]:::error + Tuning --> Param[-XX:StringTableSize 调优参数]:::error + + %% 线条样式 + linkStyle default stroke:#005D7B,stroke-width:1.5px,opacity:0.8 +``` + **字符串常量池** 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。 ```java @@ -289,6 +533,40 @@ JDK1.7 之前,字符串常量池存放在永久代。JDK1.7 字符串常量池 ### 直接内存 +```mermaid +graph LR + %% 颜色定义 + classDef main fill:#005D7B,color:#fff,rx:10,ry:10; + classDef compare fill:#00838F,color:#fff,rx:10,ry:10; + classDef structure fill:#4CA497,color:#fff,rx:10,ry:10; + classDef implement fill:#E99151,color:#fff,rx:10,ry:10; + classDef error fill:#C44545,color:#fff,rx:10,ry:10; + + %% 核心节点 + Root(直接内存):::main + + %% 分支1:定义与地位 + Root --> Source[定义与地位]:::compare + Source --> Source1[非运行时数据区的一部分]:::compare + Source --> Source2[非 JVM 规范定义的内存区域]:::compare + Source --> Source3[通过 JNI 在本地内存分配]:::compare + + %% 分支2:核心优势 + Root --> Advantage[核心优势]:::implement + Advantage --> Adv1[避免 Java 堆与 Native 堆来回复制数据]:::implement + Advantage --> Adv2[显著提高 I/O 性能]:::implement + Advantage --> Adv3[减少垃圾回收对应用的影响]:::implement + + %% 分支3:限制与异常 + Root --> Error[限制与异常]:::error + Error --> Error1[不受 Java 堆大小限制]:::error + Error --> Error2[受本机总内存及寻址空间限制]:::error + Error --> Error3[内存不足时抛出 OutOfMemoryError]:::error + + %% 线条样式 + linkStyle default stroke:#005D7B,stroke-width:1.5px,opacity:0.8 +``` + 直接内存是一种特殊的内存缓冲区,并不在 Java 堆或方法区中分配的,而是通过 JNI 的方式在本地内存上分配的。 直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。而且也可能导致 `OutOfMemoryError` 错误出现。 @@ -309,6 +587,45 @@ JDK1.4 中新加入的 **NIO(Non-Blocking I/O,也被称为 New I/O)**, Java 对象的创建过程我建议最好是能默写出来,并且要掌握每一步在做什么。 +```mermaid +graph TD + %% 颜色定义 + classDef root fill:#004D61,color:#fff,rx:10,ry:10; + classDef step fill:#005D7B,color:#fff,rx:10,ry:10; + classDef detail fill:#4CA497,color:#fff,rx:10,ry:10; + classDef logic fill:#E99151,color:#fff,rx:10,ry:10; + + %% 核心流程 + Start(new 指令触发):::root + + Start --> S1[Step 1: 类加载检查]:::step + S1 --> S1_1[检查常量池是否有类符号引用]:::detail + S1_1 --> S1_2[检查类是否已加载/解析/初始化]:::detail + + S1_2 --> S2[Step 2: 分配内存]:::step + S2 --> S2_Method{分配方式}:::logic + S2_Method -->|堆内存规整| S2_A[指针碰撞]:::logic + S2_Method -->|堆内存交错| S2_B[空闲列表]:::logic + S2_A & S2_B --> S2_Safe[并发安全: TLAB 或 CAS 重试]:::detail + + S2_Safe --> S3[Step 3: 初始化零值]:::step + S3 --> S3_1[将分配到的内存空间初始化为 0]:::detail + S3_1 --> S3_2[保证实例字段不赋初值即可直接使用]:::detail + + S3_2 --> S4[Step 4: 设置对象头]:::step + S4 --> S4_1[Mark Word: 哈希码/GC分代年龄/锁状态]:::detail + S4_1 --> S4_2[Klass Pointer: 元数据指针指向类]:::detail + + S4_2 --> S5[Step 5: 执行 init 方法]:::step + S5 --> S5_1[按照程序员意愿进行初始化]:::detail + S5_1 --> S5_2[执行构造方法]:::detail + + S5_2 --> End((对象创建完成)):::root + + %% 线条样式 + linkStyle default stroke:#005D7B,stroke-width:1.5px,opacity:0.8 +``` + #### Step1:类加载检查 虚拟机遇到一条 new 指令时,首先将去检查这个指令的参数是否能在常量池中定位到这个类的符号引用,并且检查这个符号引用代表的类是否已被加载过、解析和初始化过。如果没有,那必须先执行相应的类加载过程。 diff --git a/docs/java/new-features/java10.md b/docs/java/new-features/java10.md index f2681bc6f8a..e19e6477a90 100644 --- a/docs/java/new-features/java10.md +++ b/docs/java/new-features/java10.md @@ -1,5 +1,6 @@ --- title: Java 10 新特性概览 +description: 概览 JDK 10 的主要更新,重点介绍 var 类型推断与其他平台改进。 category: Java tag: - Java新特性 @@ -7,24 +8,25 @@ head: - - meta - name: keywords content: Java 10,JDK10,var 局部变量类型推断,垃圾回收改进,性能 - - - meta - - name: description - content: 概览 JDK 10 的主要更新,重点介绍 var 类型推断与其他平台改进。 --- -**Java 10** 发布于 2018 年 3 月 20 日,最知名的特性应该是 `var` 关键字(局部变量类型推断)的引入了,其他还有垃圾收集器改善、GC 改进、性能提升、线程管控等一批新特性。 +**Java 10** 发布于 2018 年 3 月 20 日,这是一个非 LTS(长期支持)版本,Oracle 仅提供六个月的支持。 + +下图是从 JDK 8 到 JDK 25 每个版本的更新带来的新特性数量和更新时间: -**概览(精选了一部分)**: + -- [JEP 286:局部变量类型推断](https://openjdk.java.net/jeps/286) -- [JEP 304:垃圾回收器接口](https://openjdk.java.net/jeps/304) -- [JEP 307:G1 并行 Full GC](https://openjdk.java.net/jeps/307) -- [JEP 310:应用程序类数据共享(扩展 CDS 功能)](https://openjdk.java.net/jeps/310) -- [JEP 317:实验性的基于 Java 的 JIT 编译器](https://openjdk.java.net/jeps/317) +这篇文章会挑选其中较为重要的一些新特性进行详细介绍: -## 局部变量类型推断(var) +- [JEP 286: Local-Variable Type Inference(局部变量类型推断)](https://openjdk.org/jeps/286) +- [JEP 304: Garbage-Collector Interface(垃圾回收器接口)](https://openjdk.org/jeps/304) +- [JEP 307: Parallel Full GC for G1(G1 并行 Full GC)](https://openjdk.org/jeps/307) +- [JEP 310: Application Class-Data Sharing(应用程序类数据共享)](https://openjdk.org/jeps/310) +- [JEP 317: Experimental Java-Based JIT Compiler(实验性的基于 Java 的 JIT 编译器)](https://openjdk.org/jeps/317) -由于太多 Java 开发者希望 Java 中引入局部变量推断,于是 Java 10 的时候它来了,也算是众望所归了! +## JEP 286: Local-Variable Type Inference + +由于太多 Java 开发者希望 Java 中引入局部变量类型推断,于是 Java 10 的时候它来了,也算是众望所归了! Java 10 提供了 `var` 关键字声明局部变量。 @@ -36,35 +38,51 @@ var list = List.of(1, 2, 3); var map = new HashMap
{@code ...}` 。
@@ -81,15 +77,15 @@ URL: http://127.0.0.1:8000/
`@snippet` 这种方式生成的效果更好且使用起来更方便一些。
-## JEP 416:使用方法句柄重新实现反射核心
+## JEP 416: Reimplement Core Reflection with Method Handles(方法句柄重构核心反射,转正)
-Java 18 改进了 `java.lang.reflect.Method`、`Constructor` 的实现逻辑,使之性能更好,速度更快。这项改动不会改动相关 API ,这意味着开发中不需要改动反射相关代码,就可以体验到性能更好反射。
+Java 18 改进了 `java.lang.reflect.Method`、`Constructor` 的实现逻辑,使之性能更好,速度更快。这项改动不会改动相关 API ,这意味着开发中不需要改动反射相关代码,就可以体验到性能更好的反射。
OpenJDK 官方给出了新老实现的反射性能基准测试结果。
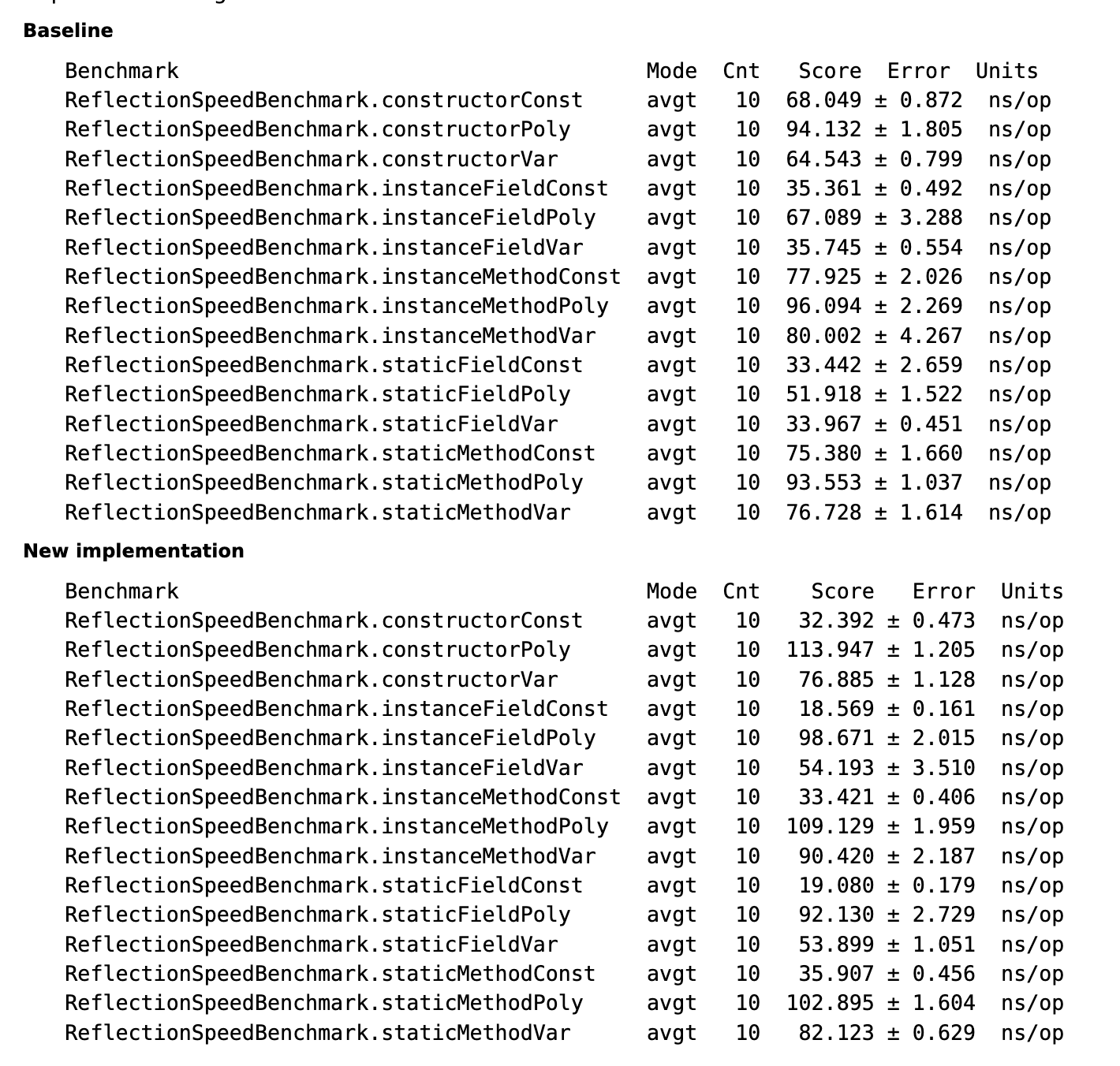
-## JEP 417: 向量 API(第三次孵化)
+## JEP 417: Vector API(向量 API,第三次孵化)
向量(Vector) API 最初由 [JEP 338](https://openjdk.java.net/jeps/338) 提出,并作为[孵化 API](http://openjdk.java.net/jeps/11)集成到 Java 16 中。第二轮孵化由 [JEP 414](https://openjdk.java.net/jeps/414) 提出并集成到 Java 17 中,第三轮孵化由 [JEP 417](https://openjdk.java.net/jeps/417) 提出并集成到 Java 18 中,第四轮由 [JEP 426](https://openjdk.java.net/jeps/426) 提出并集成到了 Java 19 中。
@@ -133,11 +129,11 @@ void vectorComputation(float[] a, float[] b, float[] c) {
在 JDK 18 中,向量 API 的性能得到了进一步的优化。
-## JEP 418:互联网地址解析 SPI
+## JEP 418: Internet-Address Resolution SPI(互联网地址解析 SPI,转正)
Java 18 定义了一个全新的 SPI(service-provider interface),用于主要名称和地址的解析,以便 `java.net.InetAddress` 可以使用平台之外的第三方解析器。
-## JEP 419:Foreign Function & Memory API(第二次孵化)
+## JEP 419: Foreign Function & Memory API(外部函数和内存 API,第二次孵化)
Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行互操作。通过高效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不受 JVM 管理的内存),该 API 使 Java 程序能够调用本机库并处理本机数据,而不会像 JNI 那样危险和脆弱。
diff --git a/docs/java/new-features/java19.md b/docs/java/new-features/java19.md
index 2c4a4839efd..13cc1b771a2 100644
--- a/docs/java/new-features/java19.md
+++ b/docs/java/new-features/java19.md
@@ -1,5 +1,6 @@
---
title: Java 19 新特性概览
+description: 介绍 JDK 19 的预览特性与并发相关更新,为后续虚拟线程铺垫。
category: Java
tag:
- Java新特性
@@ -7,26 +8,20 @@ head:
- - meta
- name: keywords
content: Java 19,JDK19,虚拟线程预览,结构化并发,外部函数 API,JEP
- - - meta
- - name: description
- content: 介绍 JDK 19 的预览特性与并发相关更新,为后续虚拟线程铺垫。
---
-JDK 19 定于 2022 年 9 月 20 日正式发布以供生产使用,非长期支持版本。不过,JDK 19 中有一些比较重要的新特性值得关注。
+JDK 19 于 2022 年 9 月 20 日正式发布,非长期支持版本。
-JDK 19 只有 7 个新特性:
+JDK 19 共有 7 个新特性,这篇文章会挑选其中较为重要的一些新特性进行详细介绍:
-- [JEP 405: Record Patterns(记录模式)](https://openjdk.org/jeps/405)(预览)
-- [JEP 422: Linux/RISC-V Port](https://openjdk.org/jeps/422)
- [JEP 424: Foreign Function & Memory API(外部函数和内存 API)](https://openjdk.org/jeps/424)(预览)
- [JEP 425: Virtual Threads(虚拟线程)](https://openjdk.org/jeps/425)(预览)
-- [JEP 426: Vector(向量)API](https://openjdk.java.net/jeps/426)(第四次孵化)
-- [JEP 427: Pattern Matching for switch(switch 模式匹配)](https://openjdk.java.net/jeps/427)
+- [JEP 426: Vector API(向量 API)](https://openjdk.java.net/jeps/426)(第四次孵化)
- [JEP 428: Structured Concurrency(结构化并发)](https://openjdk.org/jeps/428)(孵化)
-这里只对 424、425、426、428 这 4 个我觉得比较重要的新特性进行详细介绍。
+下图是从 JDK 8 到 JDK 25 每个版本的更新带来的新特性数量和更新时间:
-相关阅读:[OpenJDK Java 19 文档](https://openjdk.org/projects/jdk/19/)
+
## JEP 424: 外部函数和内存 API(预览)
@@ -37,21 +32,21 @@ Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行
在没有外部函数和内存 API 之前:
- Java 通过 [`sun.misc.Unsafe`](https://hg.openjdk.java.net/jdk/jdk/file/tip/src/jdk.unsupported/share/classes/sun/misc/Unsafe.java) 提供一些执行低级别、不安全操作的方法(如直接访问系统内存资源、自主管理内存资源等),`Unsafe` 类让 Java 语言拥有了类似 C 语言指针一样操作内存空间的能力的同时,也增加了 Java 语言的不安全性,不正确使用 `Unsafe` 类会使得程序出错的概率变大。
-- Java 1.1 就已通过 Java 原生接口(JNI)支持了原生方法调用,但并不好用。JNI 实现起来过于复杂,步骤繁琐(具体的步骤可以参考这篇文章:[Guide to JNI (Java Native Interface)](https://www.baeldung.com/jni) ),不受 JVM 的语言安全机制控制,影响 Java 语言的跨平台特性。并且,JNI 的性能也不行,因为 JNI 方法调用不能从许多常见的 JIT 优化(如内联)中受益。虽然[JNA](https://github.com/java-native-access/jna)、[JNR](https://github.com/jnr/jnr-ffi)和[JavaCPP](https://github.com/bytedeco/javacpp)等框架对 JNI 进行了改进,但效果还是不太理想。
+- Java 1.1 就已通过 Java 原生接口(JNI)支持了原生方法调用,但并不好用。JNI 实现起来过于复杂,步骤繁琐(具体的步骤可以参考这篇文章:[Guide to JNI (Java Native Interface)](https://www.baeldung.com/jni)),不受 JVM 的语言安全机制控制,影响 Java 语言的跨平台特性。并且,JNI 的性能也不行,因为 JNI 方法调用不能从许多常见的 JIT 优化(如内联)中受益。虽然 [JNA](https://github.com/java-native-access/jna)、[JNR](https://github.com/jnr/jnr-ffi) 和 [JavaCPP](https://github.com/bytedeco/javacpp) 等框架对 JNI 进行了改进,但效果还是不太理想。
引入外部函数和内存 API 就是为了解决 Java 访问外部函数和外部内存存在的一些痛点。
Foreign Function & Memory API (FFM API) 定义了类和接口:
-- 分配外部内存:`MemorySegment`、`MemoryAddress`和`SegmentAllocator`;
-- 操作和访问结构化的外部内存:`MemoryLayout`, `VarHandle`;
-- 控制外部内存的分配和释放:`MemorySession`;
-- 调用外部函数:`Linker`、`FunctionDescriptor`和`SymbolLookup`。
+- 分配外部内存:`MemorySegment`、`MemoryAddress` 和 `SegmentAllocator`
+- 操作和访问结构化的外部内存:`MemoryLayout`、`VarHandle`
+- 控制外部内存的分配和释放:`MemorySession`
+- 调用外部函数:`Linker`、`FunctionDescriptor` 和 `SymbolLookup`
下面是 FFM API 使用示例,这段代码获取了 C 库函数的 `radixsort` 方法句柄,然后使用它对 Java 数组中的四个字符串进行排序。
```java
-// 1. 在C库路径上查找外部函数
+// 1. 在 C 库路径上查找外部函数
Linker linker = Linker.nativeLinker();
SymbolLookup stdlib = linker.defaultLookup();
MethodHandle radixSort = linker.downcallHandle(
@@ -69,7 +64,7 @@ for (int i = 0; i < javaStrings.length; i++) {
}
// 5. 通过调用外部函数对堆外数据进行排序
radixSort.invoke(offHeap, javaStrings.length, MemoryAddress.NULL, '\0');
-// 6. 将(重新排序的)字符串从堆外复制到堆上
+// 6. 将(重新排序的)字符串从堆外复制到堆上
for (int i = 0; i < javaStrings.length; i++) {
MemoryAddress cStringPtr = offHeap.getAtIndex(ValueLayout.ADDRESS, i);
javaStrings[i] = cStringPtr.getUtf8String(0);
@@ -79,7 +74,7 @@ assert Arrays.equals(javaStrings, new String[] {"car", "cat", "dog", "mouse"});
## JEP 425: 虚拟线程(预览)
-虚拟线程(Virtual Thread-)是 JDK 而不是 OS 实现的轻量级线程(Lightweight Process,LWP),许多虚拟线程共享同一个操作系统线程,虚拟线程的数量可以远大于操作系统线程的数量。
+虚拟线程(Virtual Thread)是 JDK 而不是 OS 实现的轻量级线程(Lightweight Process,LWP),许多虚拟线程共享同一个操作系统线程,虚拟线程的数量可以远大于操作系统线程的数量。
虚拟线程在其他多线程语言中已经被证实是十分有用的,比如 Go 中的 Goroutine、Erlang 中的进程。
diff --git a/docs/java/new-features/java20.md b/docs/java/new-features/java20.md
index 4dc09646ae8..c7678fe3e09 100644
--- a/docs/java/new-features/java20.md
+++ b/docs/java/new-features/java20.md
@@ -1,5 +1,6 @@
---
title: Java 20 新特性概览
+description: 总结 JDK 20 的语言与并发改动,延续虚拟线程与模式匹配相关增强。
category: Java
tag:
- Java新特性
@@ -7,28 +8,27 @@ head:
- - meta
- name: keywords
content: Java 20,JDK20,记录模式预览,虚拟线程改进,语言增强,JEP
- - - meta
- - name: description
- content: 总结 JDK 20 的语言与并发改动,延续虚拟线程与模式匹配相关增强。
---
JDK 20 于 2023 年 3 月 21 日发布,非长期支持版本。
根据开发计划,下一个 LTS 版本就是将于 2023 年 9 月发布的 JDK 21。
-
-
-JDK 20 只有 7 个新特性:
+JDK 20 共有 7 个新特性,这篇文章会挑选其中较为重要的一些新特性进行详细介绍:
-- [JEP 429:Scoped Values(作用域值)](https://openjdk.org/jeps/429)(第一次孵化)
-- [JEP 432:Record Patterns(记录模式)](https://openjdk.org/jeps/432)(第二次预览)
-- [JEP 433:switch 模式匹配](https://openjdk.org/jeps/433)(第四次预览)
+- [JEP 429: Scoped Values(作用域值)](https://openjdk.org/jeps/429)(第一次孵化)
+- [JEP 432: Record Patterns(记录模式)](https://openjdk.org/jeps/432)(第二次预览)
+- [JEP 433: Pattern Matching for switch(switch 模式匹配)](https://openjdk.org/jeps/433)(第四次预览)
- [JEP 434: Foreign Function & Memory API(外部函数和内存 API)](https://openjdk.org/jeps/434)(第二次预览)
- [JEP 436: Virtual Threads(虚拟线程)](https://openjdk.org/jeps/436)(第二次预览)
-- [JEP 437:Structured Concurrency(结构化并发)](https://openjdk.org/jeps/437)(第二次孵化)
-- [JEP 432:向量 API(](https://openjdk.org/jeps/438)第五次孵化)
+- [JEP 437: Structured Concurrency(结构化并发)](https://openjdk.org/jeps/437)(第二次孵化)
+- [JEP 438: Vector API(向量 API)](https://openjdk.org/jeps/438)(第五次孵化)
+
+下图是从 JDK 8 到 JDK 25 每个版本的更新带来的新特性数量和更新时间:
+
+
-## JEP 429:作用域值(第一次孵化)
+## JEP 429: Scoped Values(作用域值,第一次孵化)
作用域值(Scoped Values)它可以在线程内和线程间共享不可变的数据,优于线程局部变量,尤其是在使用大量虚拟线程时。
@@ -47,7 +47,7 @@ ScopedValue.where(V,